







EM(Expectation-Maximum)算法也称期望最大化算法,迭代分为两步:期望步(E步)+极大步(M步)
算法流程:初始化分布参数+重复迭代直到收敛
无人车有三类约束:
- Rraffic Regulation
- Decisions
- Best Trajectory
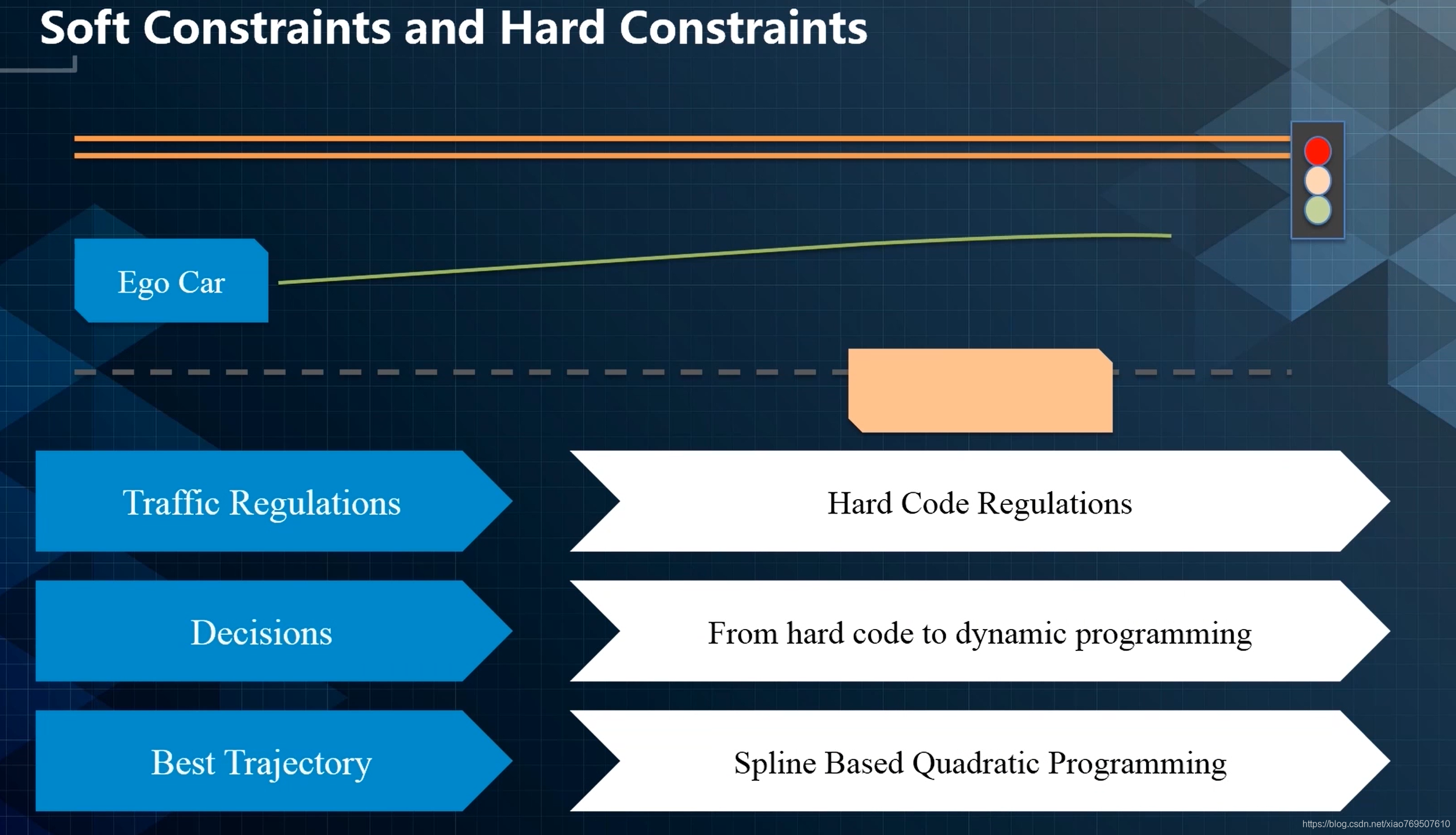
硬限制+软限制。前者比如交通规则
如果换道生成的策略的trajectory比不换道生成的策略的trajectory要好,那么就换道。
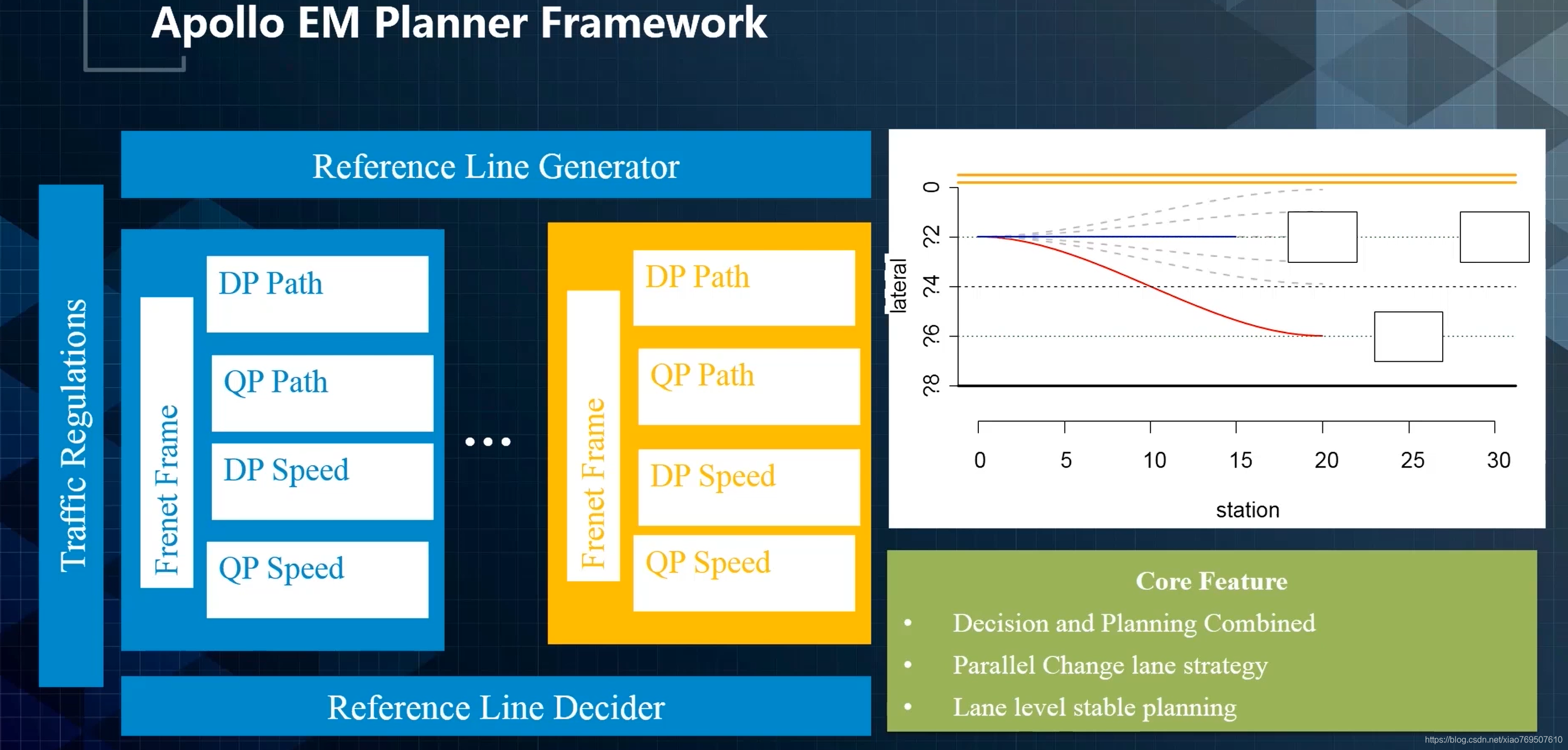
EM迭代过程:
- 生成一条Optimal path
- 在该path上对所有障碍物进行投影
- 然后生成一个optimal speed profile,在下一个周期该speed profile会送到path optimization
- 不断path / speed迭代,直至收敛到最优解
该算法的缺点:贪心算法,收敛到局部最优(但也够用)
分四步走:两步E两步M
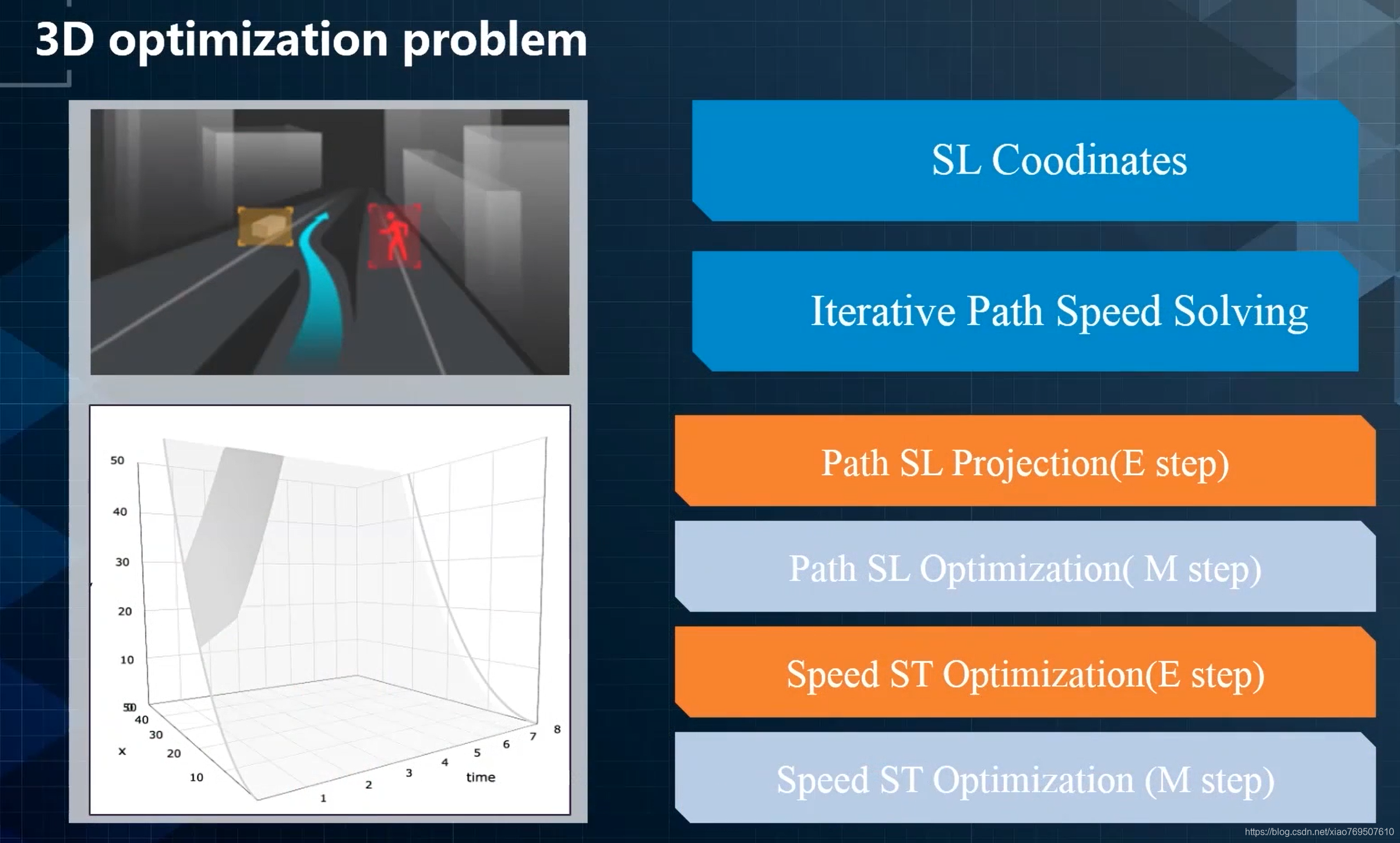
优化问题的核心分三部分:

想要解决好决策问题,需要理解下面三个圆圈
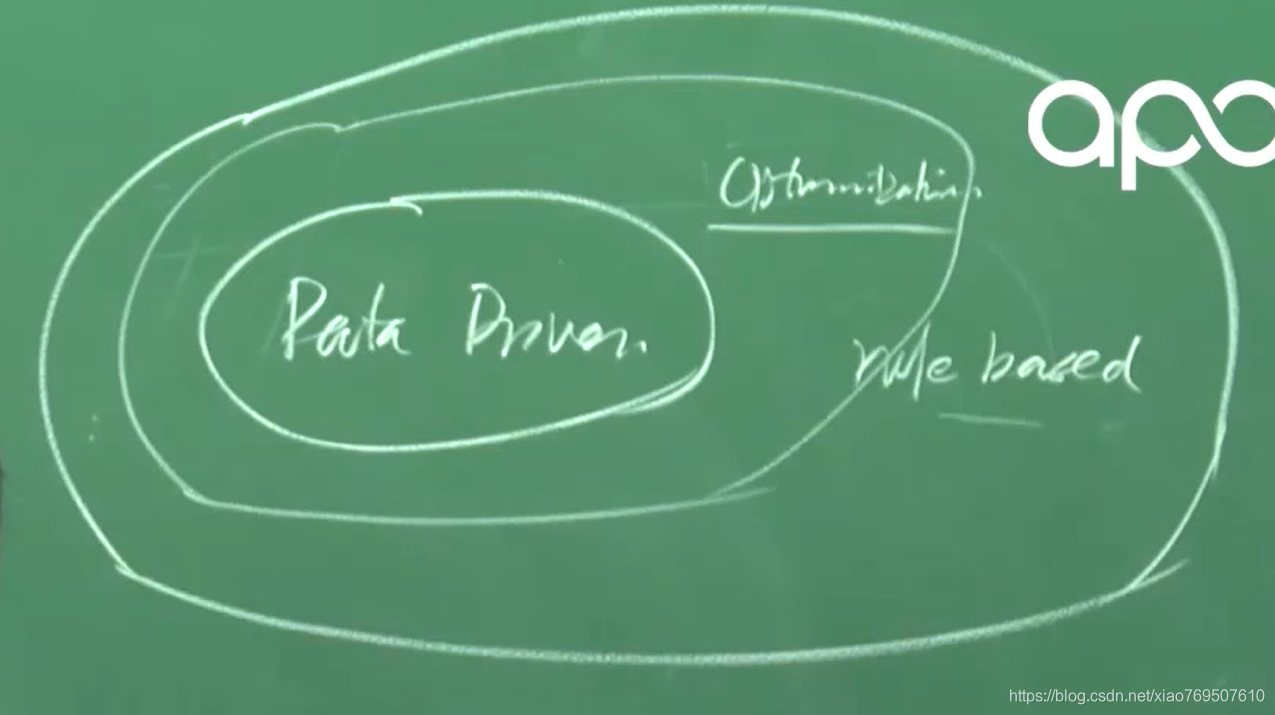
- rule based(规则)
- optimization(优化)
- path driven(数据闭环)
先了解清楚这个问题,才去通过大量的数据训练
(下图是老师推荐的课)

handling uncertainty with model
寻找一个action能够优化反馈函数(优化方式:RL)
RL:
能够给出状态到动作的映射
将见过的题做总结,并且知道了什么类型的题用什么方法或者套路去完成。
思考点:当环境发生剧烈变化,是否还能应对?
图意:看到老虎应该如何行动(往左往右还是直接进他嘴里)
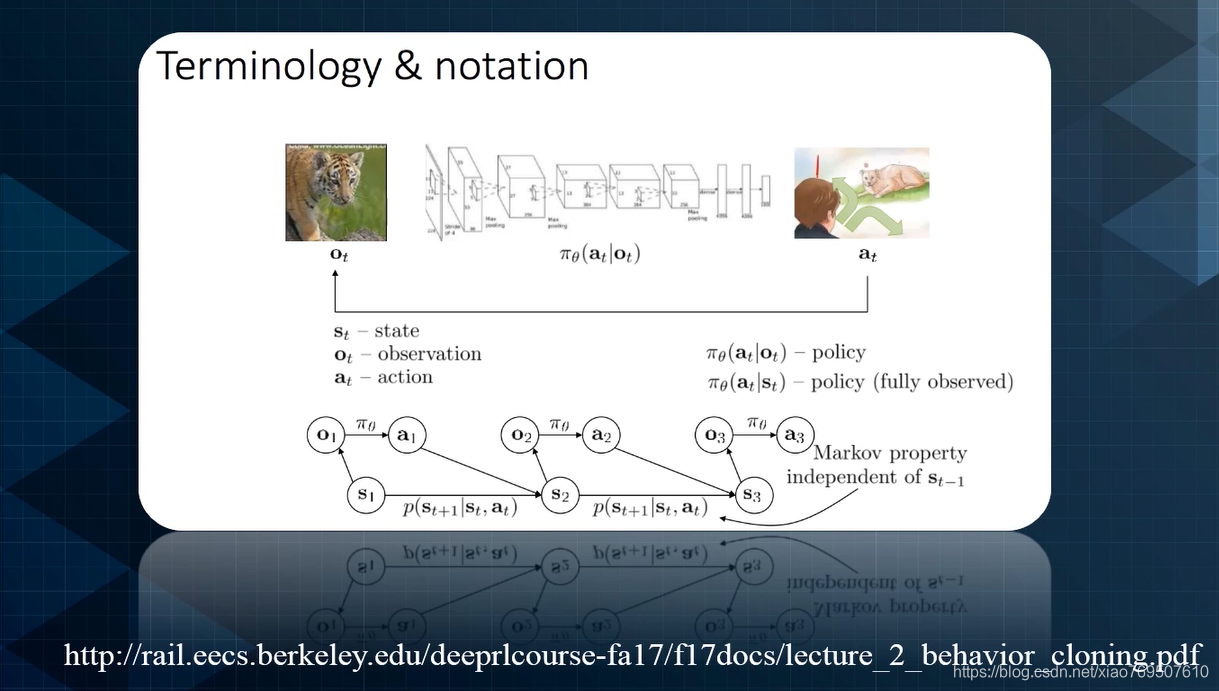
imitation learning:模仿学习
RL最关心的问题:如何做这个映射

数据驱动:经过对大量案例的分析,形成模型。当遇到相似问题的时候,可以直接套用数据驱动的模型获得结果,十分快速。














 5253
5253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









