











论文链接:Self-Supervised Interest Point Detection and Description
目录
(2) Interest Point Decoder 特征点解码网络
一、背景介绍
这篇文章设计了一种自监督网络框架,能够同时提取特征点的位置以及描述子
相比于patch-based方法,本文提出的算法能够在原始图像提取到像素级精度的特征点的位置及其描述子。本文提出了一种单应性适应(Homographic Adaptation)的策略以增强特征点的复检率以及跨域的实用性(这里跨域指的是synthetic-to-real的能力,网络模型在虚拟数据集上训练完成,同样也可以在真实场景下表现优异的能力)
特点:自监督的;无需patch-based;实时;全尺寸的;兴趣点多视角重复性高;跨域适应性高;多任务(单一网络中,同时训练兴趣点检测和描述符)
算法优劣对比对比
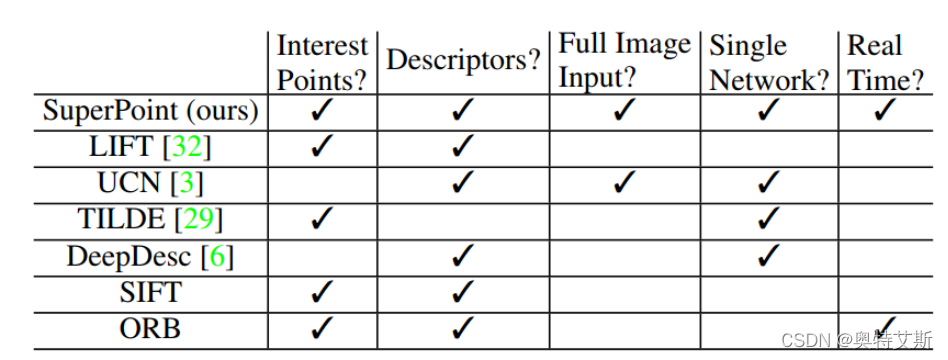
传统方法的问题:基于图像块的算法导致特征点位置精度不够准确;特征点与描述子分开进行训练导致运算资源的浪费,网络不够精简,实时性不足;仅仅训练特征点或者描述子的一种,不能用同一个网络进行联合训练
二、整体步骤
如下图整个训练流程分为三部分:(1)特征点预训练(2)自监督标签(3)联合训练:
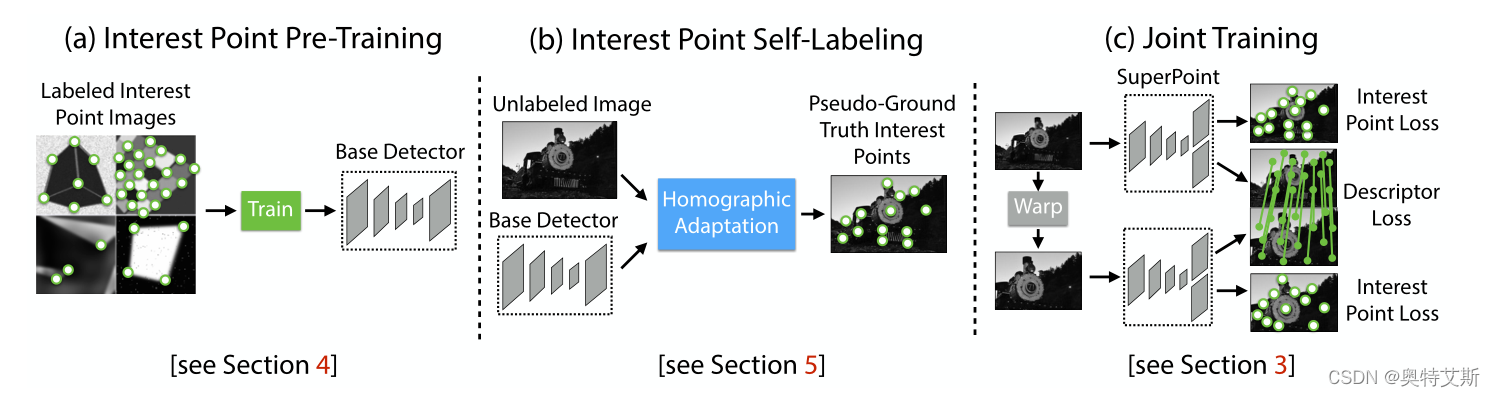
(1)特征点预训练:
创建合成数据集 Synthetic Shapes(图形简单、像素小、总量巨大,兴趣点准确 ) 利用合成数据集搭建 Superpoint网络(网络后面细说)。训练结果在合成数据集 Synthetic Shapes上,显著优于传统的兴趣点检测器(FAST等)。这里训练出的检测器我们叫:MagicPoint
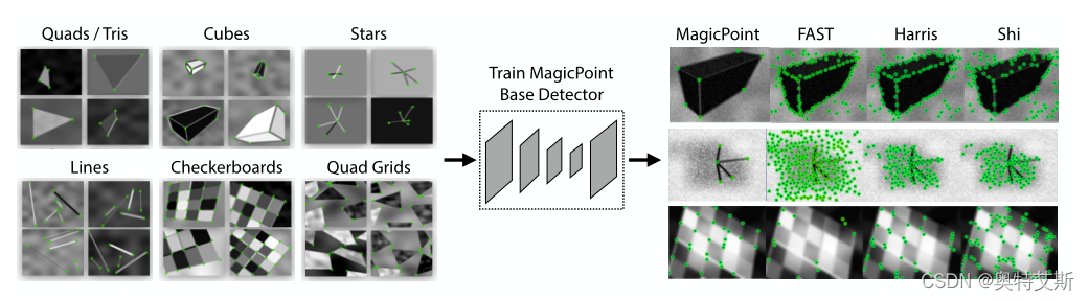
测量了1000张合成形状数据集的图像的平均精度mAP(mean Average Precision),Magicpoint明显精度更高(尤其对corner-like非常敏感) 。与经典探测器(如 FAST、Harris等)相比,抗噪声能力显著
MagicPoint与经典检测器的对比

然而, 与经典的兴趣点检测器相比, MagicPoint在不同的纹理和图案上, 遗漏了许多潜在的兴趣点位置;多视角的重复性欠佳;迁移能力不足。显然,这不是我们想要的最好的检测器(dataset太简单,迁移性不强)
(2)自监督标签:
用(1)中训练好的检测器MagicPoint用它得到数据集(选用的COCO数据集)的特征点。由此 self-supervised dataset 训练而产生的检测结果具有更强的可重复性 每张图片变换量 N_h=100,最终detctor的重复性提高21%。这一步称作兴趣点自标注(Interest Point Self-Labeling)
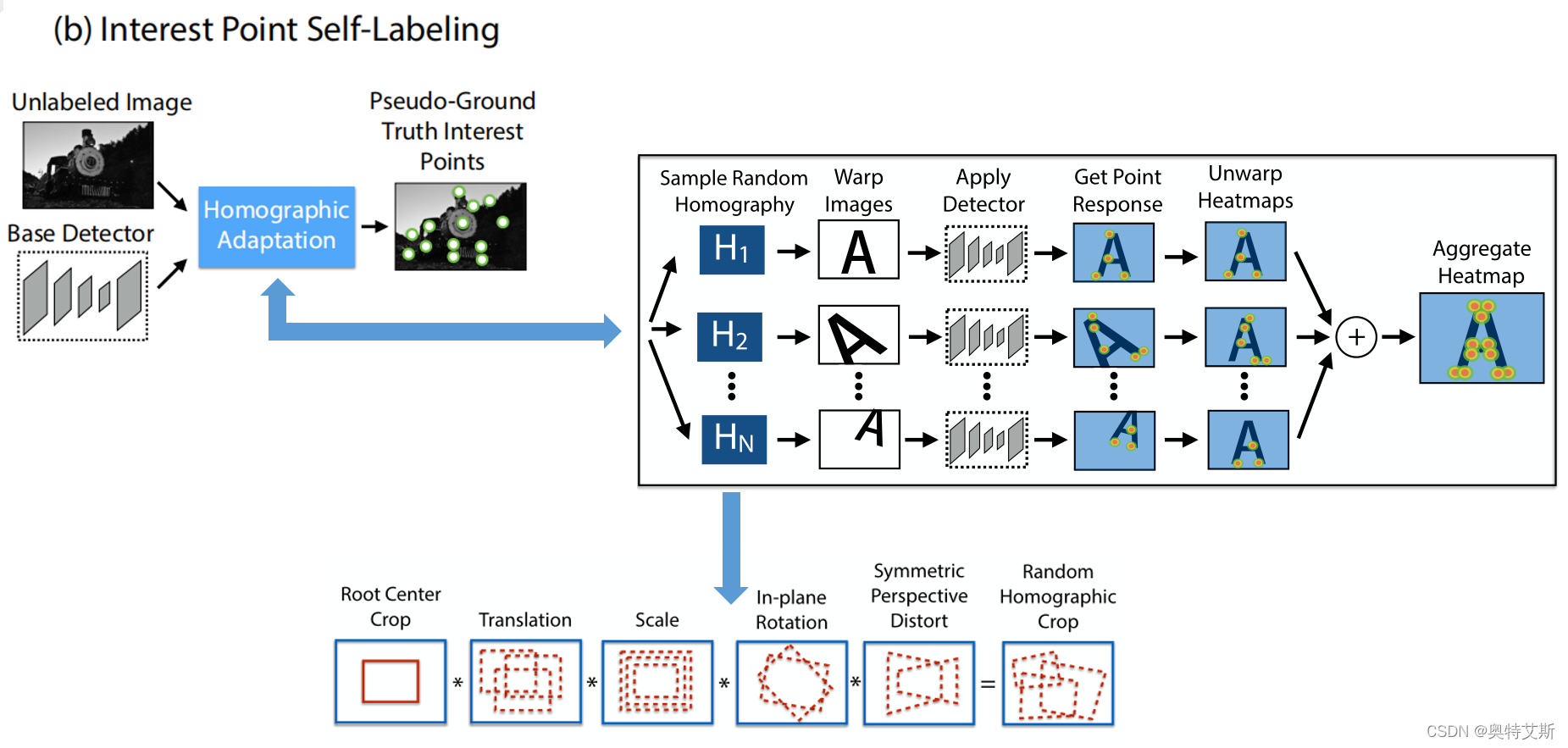
(3)联合训练:
如图所示我们,后面一章来细说:
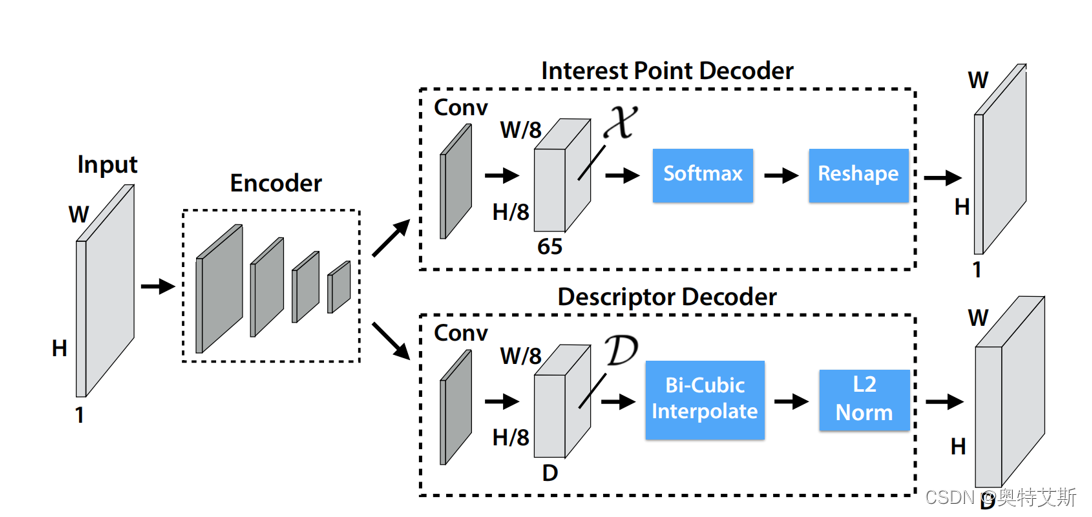
三、网络结构
不难发现,整个环节出现了四次superpoint网络:
(1)训练基础网络(特征点检测)
(2)使用基本网络生成数据集
(3)训练最终网络(描述符训练采用孪生网络故2次)
网络共享一个单一的前向encoder,只是在decoder时采用了不同的结构,根据任务的不同学习不同的网络参数。这也是本框架与其他网络的不同之处:其他网络采用的是先训练好特征点检测网络,然后再去进行对特征点描述网络进行训练。如图所示: 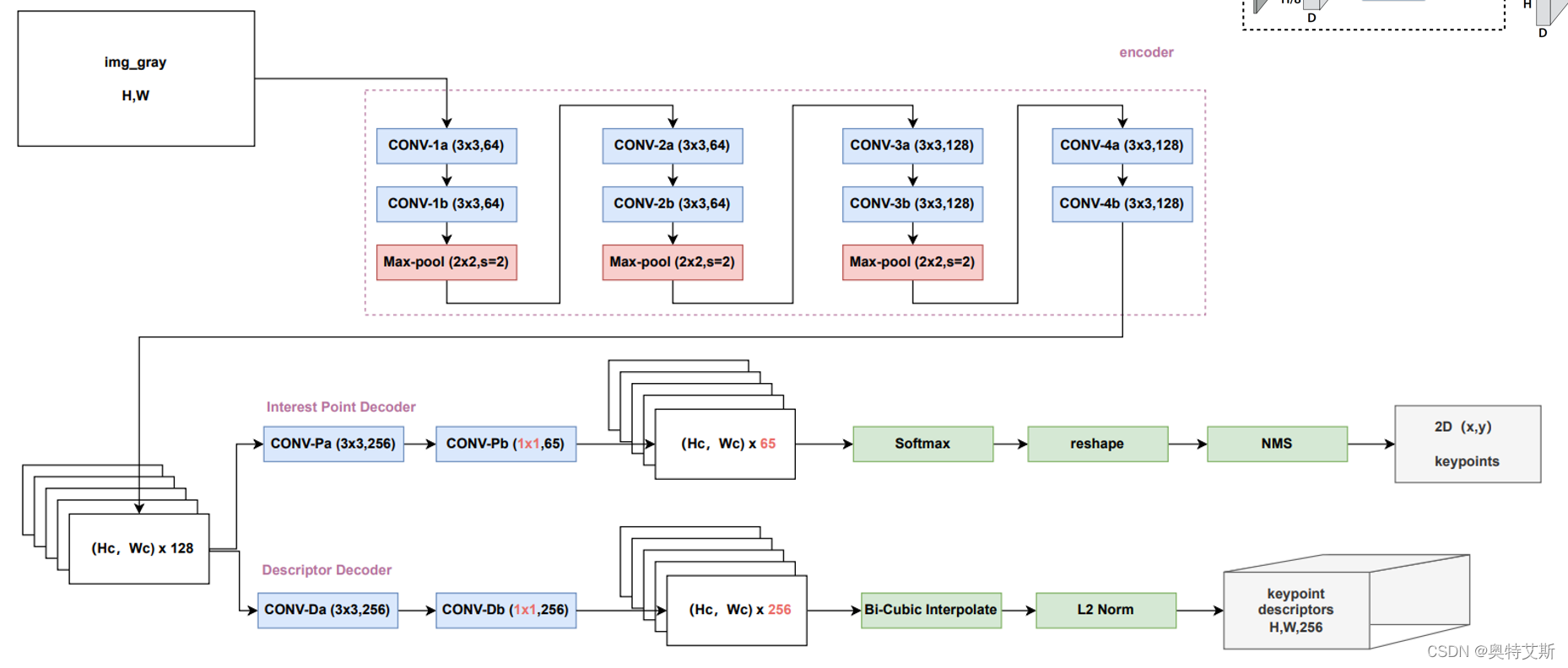
Superpoint 网络完整结构
(1) Shared Encoder 共享编码网络
整体而言,本质上有两个网络,只是前半部分共享了一部分而已。输入(H,W)的图像,经过4次block块(每一个块包括2个卷积层和最大池化层,最后一次没有池化层),池化层选用的步长step为2,每一次 tensor 尺寸就缩小一倍。最终输出的就是(Hc,Wc,128)的 tensor。其中Hc=H/8,Wc=W/8。
(2) Interest Point Decoder 特征点解码网络
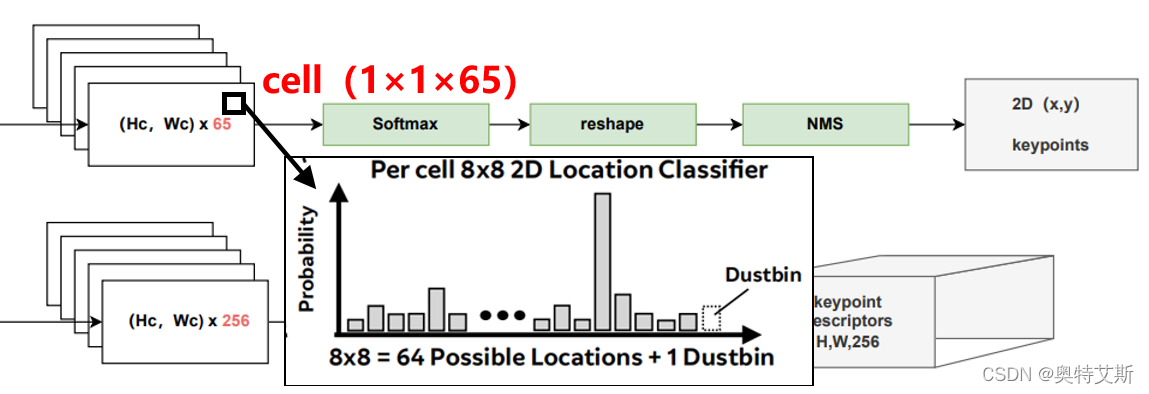
得到上文的(Hc,Wc,128)后,我们来"共享"使用它。经过两层卷积获得(Hc,Wc,65)的tensor。其中65代表原尺寸8x8的范围的,与之一一对应。(64+1,最后那1位进行舍去dustbin)。对每一个通道(65位)进行softmax过程中会舍去。
每个像素的经过该解码器的输出是该像素是特征点的概率(probability of “point-ness”)。通常而言,我们可以通过反卷积得到上采样的图像。文章中选用的是“增加深度,扩大尺寸”。然后对进行reshape即 (h,w,64)→(h×8,w×8)。至此我们就有了每个像素的经过该解码器的输出——该像素是特征点的概率。
(3)Descriptor Decoder 特征点描述网络
同理,我们还是“共享”使用encoder层的输出(Hc,Wc,128)。经过卷积解码器得到(Hc,Wc,256),双线性插值扩大尺寸(H,W,256),最后对每一个像素的描述子(256维)进行L2归一化。

具体训练流程:采用类似孪生网络。左图进行wrap生成右图,双双进入superpoint网络,联合求取loss。
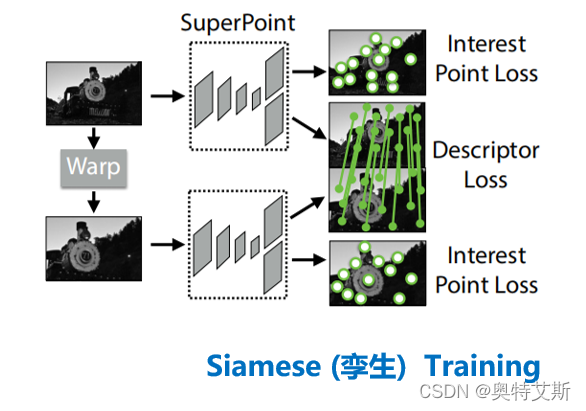
(4)损失设计
损失函数设计分为三部分:Lp:特征点损失;Lp':右图特征点损失;Ld:特征描述损失

Lp:特征点损失:
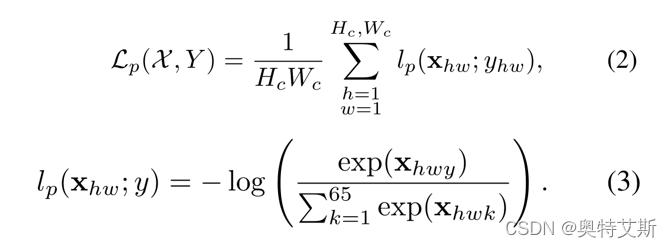
Ld:特征描述损失

四、结果


















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









