







目录
引言
在人工智能领域,大型语言模型(LLM)因其强大的语言理解和生成能力而备受关注。vivo AI Lab开发的蓝心大模型(BlueLM)以其卓越的性能和广泛的应用场景,成为业界关注的焦点。本文将为您提供一个全面的实战指南,帮助您了解如何在实际项目中部署和体验BlueLM的强大功能。
一、BlueLM概述
蓝心大模型(BlueLM)是vivo精心打造的一款自研通用大型语言模型矩阵,涵盖了从十亿到千亿不同参数量级的五款模型。具体来说,BlueLM家族中的7B和1B模型特别优化以支持高通和联发科两大平台,专为端侧应用场景设计;而70B、130B和175B模型则针对云端服务和需要复杂逻辑推理的应用场景进行了特别定制。这些模型的多样性和专业性,使得BlueLM能够灵活应对各种不同的技术挑战和业务需求。
二、BlueLM核心特点
蓝心大模型(BlueLM)之所以在众多大型语言模型中脱颖而出,得益于其一系列核心特点,这些特点不仅定义了BlueLM的能力范围,也为其实用价值和应用前景提供了坚实的基础。以下是BlueLM的几个关键核心特点:
1. 多参数量级覆盖
BlueLM提供了从十亿到千亿参数量级的模型选择,这种广泛的覆盖范围使得BlueLM能够灵活适应不同的应用需求和计算资源限制。无论是在资源受限的移动设备上,还是在需要处理大规模数据的云端服务中,BlueLM都能提供合适的解决方案。
2. 跨平台兼容性
BlueLM特别针对高通和联发科两大主流移动平台进行了优化,确保了在不同设备上的高性能和兼容性。这种跨平台的设计使得BlueLM能够广泛应用于各种智能设备,为用户提供一致的体验。
3. 高性能与优化
尽管拥有庞大的参数量,BlueLM在设计时就注重性能优化,通过先进的算法和技术减少了模型的推理时间和资源消耗。这使得BlueLM在保持高精度的同时,也能在实际应用中实现快速响应。
4. 安全性与隐私保护
在人工智能领域,数据安全和隐私保护至关重要。BlueLM在设计和开发过程中严格遵循安全和隐私标准,确保用户数据的安全和隐私得到充分保护。
5. 易于集成与使用
BlueLM提供了简洁的API接口和详细的文档,使得开发者可以轻松地将模型集成到自己的项目中。这种易用性大大降低了技术门槛,使得非专业的开发者也能快速上手。
6. 多语言和多模态能力
BlueLM支持多语言处理,能够理解和生成多种语言的文本,这对于全球化的应用场景尤为重要。此外,BlueLM还具备多模态处理能力,能够处理包括文本、图像在内的多种类型的数据。
7. 持续进化的能力
作为vivo AI Lab的旗舰产品,BlueLM不断接收最新的研究成果和技术更新,确保模型能够持续进化,适应不断变化的技术环境和应用需求。
8. 广泛的应用场景
BlueLM的应用场景非常广泛,从内容创作、知识问答到逻辑推理、代码生成,再到信息提取和自动化办公,BlueLM都能提供强大的支持。
这些核心特点共同构成了BlueLM的核心竞争力,使其成为一个在多个领域都能发挥重要作用的大型语言模型。随着技术的不断进步,BlueLM将继续扩展其能力边界,为用户提供更加丰富和高效的AI解决方案。
三、BlueLM评估测试
为了确保模型评估的准确性和可比性,vivo AI Lab官方选择了业界广泛认可的OpenCompass评测框架,对BlueLM模型进行了一系列的标准化测试。这些测试覆盖了多个关键领域,包括C-Eval、MMLU、CMMLU、GaoKao、AGIEval、BBH、GSM8K、MATH和HumanEval等榜单,旨在全面评估BlueLM在通用语言理解、数学解题以及编程代码创作方面的能力。通过这些细致入微的测试,我们能够深入洞察BlueLM的性能表现,从而为模型的进一步优化和应用提供坚实的数据支持。
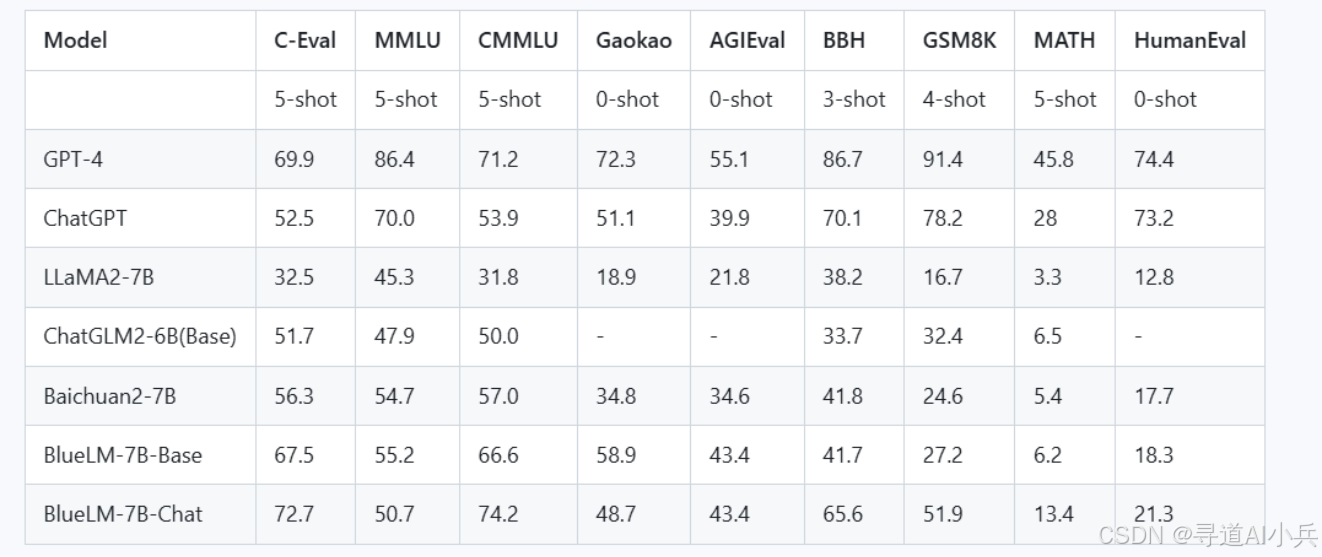
通过OpenCompass框架下的多维度测试,BlueLM在通用能力、数学能力和代码能力方面均展现出了卓越的性能。这些测试结果不仅证明了BlueLM的技术实力,也为未来的应用开发提供了宝贵的参考。
四、BlueLM应用领域
BlueLM的应用领域非常广泛,以下是一些主要的应用场景:
- 内容创作辅助:BlueLM可以帮助用户生成创意文本、撰写文章或博客,甚至创作诗歌和故事,提高写作效率和质量。
- 知识问答系统:在教育和研究领域,BlueLM提供准确的知识问答服务,帮助学习者和研究人员快速获取所需信息。
- 逻辑推理与分析:在法律、金融等需要复杂逻辑推理的领域,BlueLM能够分析和解答复杂的逻辑问题,辅助决策制定。
- 代码生成和软件开发:BlueLM协助编写和优化代码,提高开发效率,尤其在自动化测试和代码审查方面表现出色。
- 信息提取和数据分析:从大量文本中快速提取关键信息,助力数据分析和报告制作。
- 自动化办公:BlueLM帮助撰写和编辑官方文档、报告,甚至自动生成会议纪要和邮件回复。
- 多语言翻译和本地化:提供高质量的翻译服务,帮助企业和个人跨越语言障碍。
- 创意娱乐:在娱乐和游戏行业,BlueLM用于生成创意内容,如游戏剧情、角色对话等,增强用户体验。
BlueLM的这些特点和应用领域展示了其作为大型语言模型的多功能性和实用性。随着技术的不断进步和模型的持续优化,BlueLM有望在未来的人工智能应用中发挥更加关键的作用。
五、BlueLM部署体验
1、环境准备
首先需要下载本仓库:
git clone https://github.com/vivo-ai-lab/BlueLM
cd BlueLM
然后使用 pip 安装依赖:
pip install -r requirements.txt
使用 BlueLM-7B-Base-32K 或 BlueLM-7B-Chat-32K,请额外安装 flash_attn:
pip install flash_attn==2.3.3
2、Base 模型推理示例
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("vivo-ai/BlueLM-7B-Base", trust_remote_code=True, use_fast=False)
model = AutoModelForCausalLM.from_pretrained("vivo-ai/BlueLM-7B-Base", device_map="cuda:0", trust_remote_code=True)
model = model.eval()
inputs = tokenizer("儒林外史->吴敬梓\n隋唐演义->褚人获\n红楼梦->", return_tensors="pt")
inputs = inputs.to("cuda:0")
pred = model.generate(**inputs, max_new_tokens=64, repetition_penalty=1.1)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
3、命令行 Demo体验
想要快速体验BlueLM的强大功能吗?通过简单的命令行操作,您可以立即开始与BlueLM的交互。以下是如何在命令行中运行我们的Demo:
python cli_demo.py
这条命令将启动一个交互式的命令行界面,让您能够直接输入指令和问题,体验BlueLM的即时响应和处理能力。
4、网页Demo体验
除了命令行,您还可以通过一个简单的网页界面来体验BlueLM。以下是如何启动网页Demo的步骤:
streamlit run web_demo.py --server.port 8080
执行上述命令后,BlueLM的网页Demo将在本地服务器的8080端口上运行。只需打开您的网络浏览器,输入http://localhost:8080,即可访问一个直观的用户界面,通过图形化操作体验BlueLM的各项功能。
5、量化部署推理
官方提供了 BlueLM-7B-Chat 的 4bits 版本 BlueLM-7B-Chat-4bits。如果你的 GPU 显存有限,可以尝试加载 4-bits 模型,只需要 5GB 显存。且经过测试,BlueLM 在 4-bits 量化下仍能流畅地生成文本。
模型下载:https://huggingface.co/vivo-ai/BlueLM-7B-Chat-4bits
安装依赖:
cd BlueLM/quant_cuda
python setup_cuda.py install
加载模型推理示例:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("vivo-ai/BlueLM-7B-Chat-4bits", trust_remote_code=True, use_fast=False)
model = AutoModelForCausalLM.from_pretrained("vivo-ai/BlueLM-7B-Chat-4bits", device_map="cuda:0", trust_remote_code=True)
model = model.eval()
inputs = tokenizer("[|Human|]:三国演义的作者是谁?[|AI|]:", return_tensors="pt")
inputs = inputs.to("cuda:0")
outputs = model.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(outputs.cpu()[0], skip_special_tokens=True))
#三国演义的作者是谁? 《三国演义》是由元末明初小说家罗贯中所著,是中国古典四大名著之一,也是中国古代历史小说发展的巅峰之作。
结语
随着人工智能技术的飞速发展,大型语言模型(LLM)已经成为推动智能应用创新的关键力量。蓝心大模型(BlueLM)作为vivo AI Lab的杰出成果,不仅在技术上展现了卓越的性能,更在实际应用中证明了其广泛的适用性和强大的潜力。本文通过实战指南的形式,详细介绍了BlueLM的部署和体验过程,旨在帮助更多的大家深入了解并利用这一强大的工具。
通过本文的介绍,我们可以看到BlueLM在多参数量级覆盖、跨平台兼容性、高性能优化、安全性与隐私保护、易于集成与使用、多语言和多模态能力以及持续进化的能力等方面的优势。这些特点使得BlueLM不仅能够满足当前的技术需求,还能够适应未来技术发展的趋势。BlueLM的广泛应用场景,从内容创作到自动化办公,从知识问答到逻辑推理,都展示了其作为大型语言模型的多功能性和实用性。
随着技术的不断进步,BlueLM将继续扩展其能力边界,为用户提供更加丰富和高效的AI解决方案。我们期待BlueLM在未来能够带来更多的创新和突破,同时也鼓励更多的开发者和研究人员加入到BlueLM的探索和应用中来,共同推动人工智能技术的发展和应用。
GitHub地址:https://github.com/vivo-ai-lab/BlueLM

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,加入技术交流群,开启编程探索之旅。
💘精心准备📚500本编程经典书籍、💎AI专业教程,以及高效AI工具。等你加入,与我们一同成长,共铸辉煌未来。
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!



















 1606
1606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











