







系列篇章💥
目录
前言
在当今数字化信息飞速发展的时代,语音识别技术已成为人工智能领域的重要分支,广泛应用于视频字幕生成、会议记录、语音数据分析等众多场景。然而,面对长音频数据处理,传统自动语音识别(ASR)系统往往暴露出效率低下、精度不足等问题。就在这样的技术背景下,WhisperX 项目应运而生,它如同一颗新星,为语音识别领域带来了全新的解决方案,助力开发者和企业突破技术瓶颈,实现高效的语音数据处理。
一、项目概述
WhisperX 是一个开源的自动语音识别(ASR)项目,由 m-bain 开发,基于 OpenAI 的 Whisper 模型,并在此基础上进行了深度优化和扩展。它通过引入批量推理、强制音素对齐和语音活动检测等技术,实现了高达 70 倍的实时转录速度,并提供精确的单词级时间戳和说话人识别功能。该项目不仅在性能上取得了突破,还在 Ego4d 转录挑战中荣获第一名,并被接受在 INTERSPEECH 2023 上展示,充分彰显了其技术先进性和实用性。
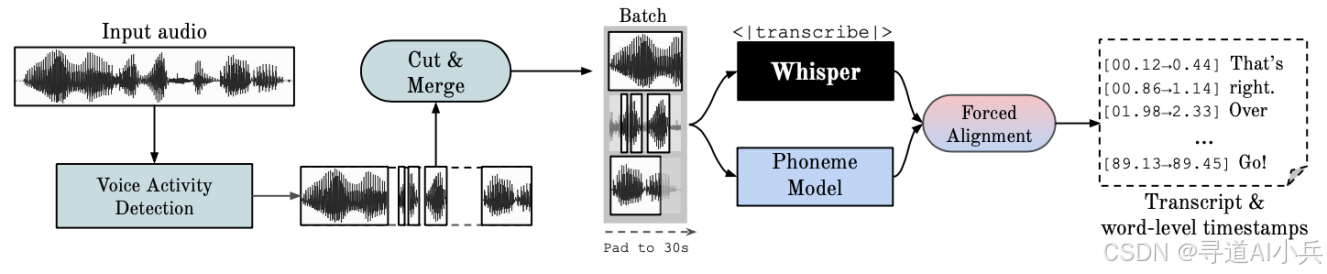
二、核心功能
(一)自动语音识别
WhisperX 使用 Whisper 模型进行语音识别,能够处理多种语言的音频数据,包括英语、德语、法语、西班牙语、意大利语、日语和中文。无论音频中夹杂着不同语言,它都能精准识别并转录,展现出卓越的多语言处理能力。
(二)词级别时间戳
通过结合 wav2vec2 模型进行强制对齐,WhisperX 能够生成每个单词的精确时间戳,显著提高了转录的准确性。这意味着在转录文本中,每一个单词的出现时间都能被精准定位,为后续的文本处理和分析提供了更细致的时间维度信息。
(三)说话人分割
项目集成了 pyannote-audio 的说话人分割功能,能够识别和标注音频中的不同说话人。在多人对话场景下,这一功能显得尤为重要,它能够清晰地区分出不同说话人的发言内容,让转录文本更具条理性和可读性。
(四)批处理推理
WhisperX 支持批处理推理,能够在 GPU 上实现高达 70 倍的实时处理速度。这一技术突破使得处理大规模音频数据成为可能,大大提升了工作效率,为大规模语音数据处理提供了强大的技术支持。
(五)语音活动检测(VAD)
通过 VAD 预处理,WhisperX 能够更准确地识别和转录包含语音的音频段。它能够有效过滤掉音频中的非语音部分,减少幻听现象,同时不影响转录的准确性,从而提高了转录质量。
三、技术原理
(一)基于 Whisper 模型的优化
Whisper 是由 OpenAI 开发的 ASR 模型,经过大规模多样化音频数据集的训练,能够产生高度准确的转录结果。然而,Whisper 原生不支持批处理,且其时间戳仅在句子级别,可能会有几秒钟的误差。WhisperX 在此基础上进行了优化,通过强制音素对齐和语音活动检测等技术,实现了单词级时间戳的精确标注。
Whisper 模型采用了基于 Transformer 的架构,具有强大的序列建模能力。它通过端到端的训练方式,能够直接将音频信号映射到文本序列。WhisperX 利用 Whisper 模型的强大性能,同时针对其不足之处进行改进,从而实现了更高效、更精准的语音识别。
(二)强制音素对齐
强制对齐是指将正字法转录与音频记录对齐的过程,以自动生成音素级别的分段。WhisperX 使用 wav2vec2 模型进行强制对齐,从而提供精确的单词级时间戳。这一技术的核心在于利用 wav2vec2 模型对音频进行深度特征提取,然后与转录文本进行逐帧比对,找到每一个单词在音频中的精确起始和结束时间。
wav2vec2 模型是一种基于自监督学习的语音表示学习模型,它通过对大量无标注语音数据的学习,能够提取出语音信号中的丰富特征。在强制对齐过程中,这些特征被用来与文本进行精确匹配,从而实现单词级别的时间戳标注。
(三)说话人分割技术
WhisperX 集成了 pyannote-audio 的说话人分割功能,能够将包含人类语音的音频流按每个说话人的身份分割成同质段。这一功能对于多说话人场景的语音转录尤为重要。
pyannote-audio 是一个专门用于语音处理的开源库,提供了多种说话人分割算法。WhisperX 利用其先进的说话人分割技术,通过对音频中的语音特征进行分析,识别出不同说话人的语音模式,从而实现精准的说话人分割。这一技术使得 WhisperX 能够在多人对话场景下,清晰地标注出每个说话人的发言内容,极大地提高了转录文本的可读性和实用性。
(四)语音活动检测(VAD)
语音活动检测是检测人类语音是否存在的过程。WhisperX 在预处理阶段使用 VAD,减少了幻听现象,同时不影响转录的准确性。
VAD 技术通过对音频信号的特征分析,判断当前音频帧是否包含语音。在语音识别预处理阶段,VAD 可以有效地过滤掉音频中的非语音部分,减少这些部分对语音识别模型的干扰,从而提高转录的准确性。
四、应用场景
(一)视频字幕生成
在视频内容创作领域,WhisperX 的准确时间戳和说话人标签简化了为视频内容创建字幕和字幕的过程,增强了可访问性和观看体验。无论是教育视频、影视作品还是网络直播,WhisperX 都能快速准确地生成字幕,为观众提供更好的观看体验。
(二)会议和讲座转录
WhisperX 能够捕获会议、讲座和网络研讨会中的讨论,并通过说话人识别来组织和澄清转录文本。在企业会议记录场景下,它能够快速将会议内容转录成文本,并区分不同发言人的观点,为后续的会议纪要整理和决策支持提供有力帮助。
(三)音频索引和搜索
WhisperX 提供详细的转录文本和时间信息,从而为音频档案和播客提供高级索引和搜索功能。用户可以通过关键词快速定位到音频中的相关内容,大大提高了音频资源的利用效率。
(四)教育领域
WhisperX 可以辅助教学,为课堂视频录制提供文字化支持,助力教学材料的整理。教师可以通过 WhisperX 快速将课堂讲解内容转录成文本,制作成电子教材,方便学生复习和预习。
五、快速使用
(一)环境准备
WhisperX 基于 Python 开发,需要安装以下依赖:
- Python 3.8 或更高版本:Python 是目前最流行的编程语言之一,具有丰富的库和框架支持。WhisperX 依托 Python 的强大生态,实现了高效的语音识别功能。
- PyTorch 1.10 或更高版本:PyTorch 是一个开源的机器学习框架,提供了强大的张量计算和自动求导功能。WhisperX 利用 PyTorch 的高效计算能力,加速了模型的训练和推理过程。
- whisper:Whisper 是 OpenAI 开发的自动语音识别模型,是 WhisperX 的基础。安装 whisper 库可以方便地调用 Whisper 模型进行语音识别。
(二)安装 WhisperX
通过以下命令安装 WhisperX:
pip install git+https://github.com/m-bain/whisperX.git
这条命令通过 pip 从 GitHub 上直接安装 WhisperX 库,确保获取到最新版本的代码。
(三)基本使用
以下是一个简单的使用示例:
import whisperx
import torch
# 加载模型
device = "cuda" if torch.cuda.is_available() else "cpu"
model = whisperx.load_model("large-v2", device)
# 转录音频
audio_path = "path/to/your/audio.wav"
result = model.transcribe(audio_path)
# 打印结果
print(result)
在这段代码中,首先导入了 whisperx 和 torch 库。然后根据设备情况(是否支持 CUDA)加载了 WhisperX 模型。接着指定音频文件路径,调用模型的 transcribe 方法进行语音识别,并将结果打印出来。这个简单的示例展示了 WhisperX 的基本使用流程,用户可以根据实际需求进行扩展和定制。
六、结语
WhisperX 作为一个开源的自动语音识别项目,凭借其高效的转录速度、精确的时间戳标注和强大的说话人分割功能,为语音识别领域带来了新的突破。无论是在视频字幕生成、会议记录还是教育领域,WhisperX 都展现出了广泛的应用前景。希望本文的介绍能够帮助你更好地了解和使用 WhisperX,如果你对该项目感兴趣,可以访问其 GitHub 页面,获取更多详细信息。
七、相关资源
- WhisperX 仓库:https://github.com/m-bain/whisperX
- WhisperX 论文:https://arxiv.org/abs/2303.00747

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!


















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











