







《AGENT AI- SURVEYING THE HORIZONS OF MULTIMODAL INTERACTION》
https://download.csdn.net/download/ajian005/90168014
ABSTRACT(摘要)
Multi-modal AI systems will likely become a ubiquitous presence in our everyday lives. A promising approach to making these systems more interactive is to embody them as agents within physical and virtual environments. At present, systems leverage existing foundation models as the basic building blocks for the creation of embodied agents. Embedding agents within such environments facilitates the ability of models to process and interpret visual and contextual data, which is critical for the creation of more sophisticated and context-aware AI systems. For example, a system that can perceive user actions, human behavior, environmental objects, audio expressions, and the collective sentiment of a scene can be used to inform and direct agent responses within the given environment. To accelerate research on agent-based multimodal intelligence, we define “Agent AI” as a class of interactive systems that can perceive visual stimuli, language inputs, and other environmentally- grounded data, and can produce meaningful embodied actions. In particular, we explore systems that aim to improve agents based on next-embodied action prediction by incorporating external knowledge, multi-sensory inputs, and human feedback. We argue that by developing agentic AI systems in grounded environments, one can also mitigate the hallucinations of large foundation models and their tendency to generate environmentally incorrect outputs. The emerging field of Agent AI subsumes the broader embodied and agentic aspects of multimodal interactions. Beyond agents acting and interacting in the physical world, we envision a future where people can easily create any virtual reality or simulated scene and interact with agents embodied within the virtual environment.
多模态交互前沿展望:智能体人工智能
摘要
多模态人工智能系统很可能在我们日常生活中变得无处不在。一个使这些系统更具交互性的有前景的方法是将它们构建为物理和虚拟环境中的智能体。目前,系统利用现有的基础模型作为创建具身智能体的基本构建块。将智能体嵌入到这些环境中,有助于模型处理和解释视觉和上下文数据,这对于创建更复杂和具有上下文感知能力的人工智能系统至关重要。例如,一个能够感知用户行为、人类行为、环境物体、音频表达以及场景的集体情绪的系统,可以用来告知和指导智能体在给定环境中的反应。为了加速基于智能体的多模态智能研究,我们将“智能体人工智能(Agent AI)”定义为一类交互系统,它可以感知视觉刺激、语言输入和其他基于环境的数据,并能产生有意义的具身行动。我们特别探索旨在通过整合外部知识、多感官输入和人类反馈来改进基于下一具身行动预测的智能体的系统。我们认为,通过在基于环境的环境中开发智能体人工智能系统,还可以减轻大型基础模型的幻觉及其产生环境不正确输出的倾向。新兴的智能体人工智能领域涵盖了多模态交互更广泛的具身和智能体方面。除了在物理世界中行动和交互的智能体之外,我们还设想了一个未来,人们可以轻松创建任何虚拟现实或模拟场景,并与嵌入在虚拟环境中的智能体进行交互。
更详细的解释:
想象一下,未来的生活里,人工智能不仅仅存在于手机或电脑里,而是像一个“智能体”一样,存在于我们周围的环境中。它可以“看”到我们(通过摄像头),“听”到我们(通过麦克风),甚至能理解我们所处的环境。这就是“多模态人工智能”和“具身智能体”结合的愿景。
什么是多模态人工智能?
简单来说,就是人工智能系统能够处理多种类型的信息,比如图像、声音、文字等等,就像人类一样,通过多种感官来感知世界。
什么是具身智能体?
就是把人工智能“装”在一个“身体”里,这个“身体”可以是机器人,也可以是虚拟世界中的一个虚拟形象。这样,人工智能就能够通过这个“身体”与环境进行互动,而不仅仅是处理数据。
智能体人工智能(Agent AI)
本文提出的“智能体人工智能”就是指这样一类系统:
●它们能够感知环境,包括视觉信息(比如物体、人物)、语言信息(比如我们说的话)以及其他环境信息。
●它们能够根据感知到的信息做出相应的行动,比如移动、说话、操作物体等等。
为什么要研究智能体人工智能?
●更强的交互性: 具身智能体可以更自然地与人类互动,提供更人性化的服务。
●更强的环境感知能力: 通过感知环境,智能体可以更好地理解上下文,做出更明智的决策。
●减少“幻觉”: 大型语言模型有时会产生不符合事实或逻辑的输出,被称为“幻觉”。通过让智能体在真实或模拟环境中“生活”,可以帮助它们更好地理解现实世界,从而减少“幻觉”的发生。
未来的展望
文章展望了这样一个未来:我们可以轻松创建各种虚拟场景,并与存在于这些虚拟场景中的智能体进行互动。这为游戏、教育、培训等领域带来了无限的可能性。
总而言之,智能体人工智能是一个充满希望的研究方向,它将推动人工智能从单纯的数据处理走向更智能、更具交互性的方向发展,并可能在未来深刻地改变我们的生活。
1 Introduction(介绍)
1.1 Motivation(动机)
Agent AI: Surveying the Horizons of Multimodal Interaction A PREPRINT
Historically, AI systems were defined at the 1956 Dartmouth Conference as artificial life forms that could collect information from the environment and interact with it in useful ways. Motivated by this definition, Minsky’s MIT group built in 1970 a robotics system, called the “Copy Demo,” that observed “blocks world” scenes and successfully reconstructed the observed polyhedral block structures. The system, which comprised observation, planning, and manipulation modules, revealed that each of these subproblems is highly challenging and further research was necessary. The AI field fragmented into specialized subfields that have largely independently made great progress in tackling these and other problems, but over-reductionism has blurred the overarching goals of AI research.
To advance beyond the status quo, it is necessary to return to AI fundamentals motivated by Aristotelian Holism. Fortunately, the recent revolution in Large Language Models (LLMs) and Visual Language Models (VLMs) has made it possible to create novel AI agents consistent with the holistic ideal. Seizing upon this opportunity, this article explores models that integrate language proficiency, visual cognition, context memory, intuitive reasoning, and adaptability. It explores the potential completion of this holistic synthesis using LLMs and VLMs. In our exploration, we also revisit system design based on Aristotle’s Final Cause, the teleological “why the system exists”, which may have been overlooked in previous rounds of AI development.
With the advent of powerful pretrained LLMs and VLMs, a renaissance in natural language processing and computer vision has been catalyzed. LLMs now demonstrate an impressive ability to decipher the nuances of real-world linguistic data, often achieving abilities that parallel or even surpass human expertise (OpenAI, 2023). Recently, researchers have shown that LLMs may be extended to act as agents within various environments, performing intricate actions and tasks when paired with domain-specific knowledge and modules (Xi et al., 2023). These scenarios, characterized by complex reasoning, understanding of the agent’s role and its environment, along with multi-step planning, test the agent’s ability to make highly nuanced and intricate decisions within its environmental constraints (Wu et al., 2023; Meta Fundamental AI Research (FAIR) Diplomacy Team et al., 2022).
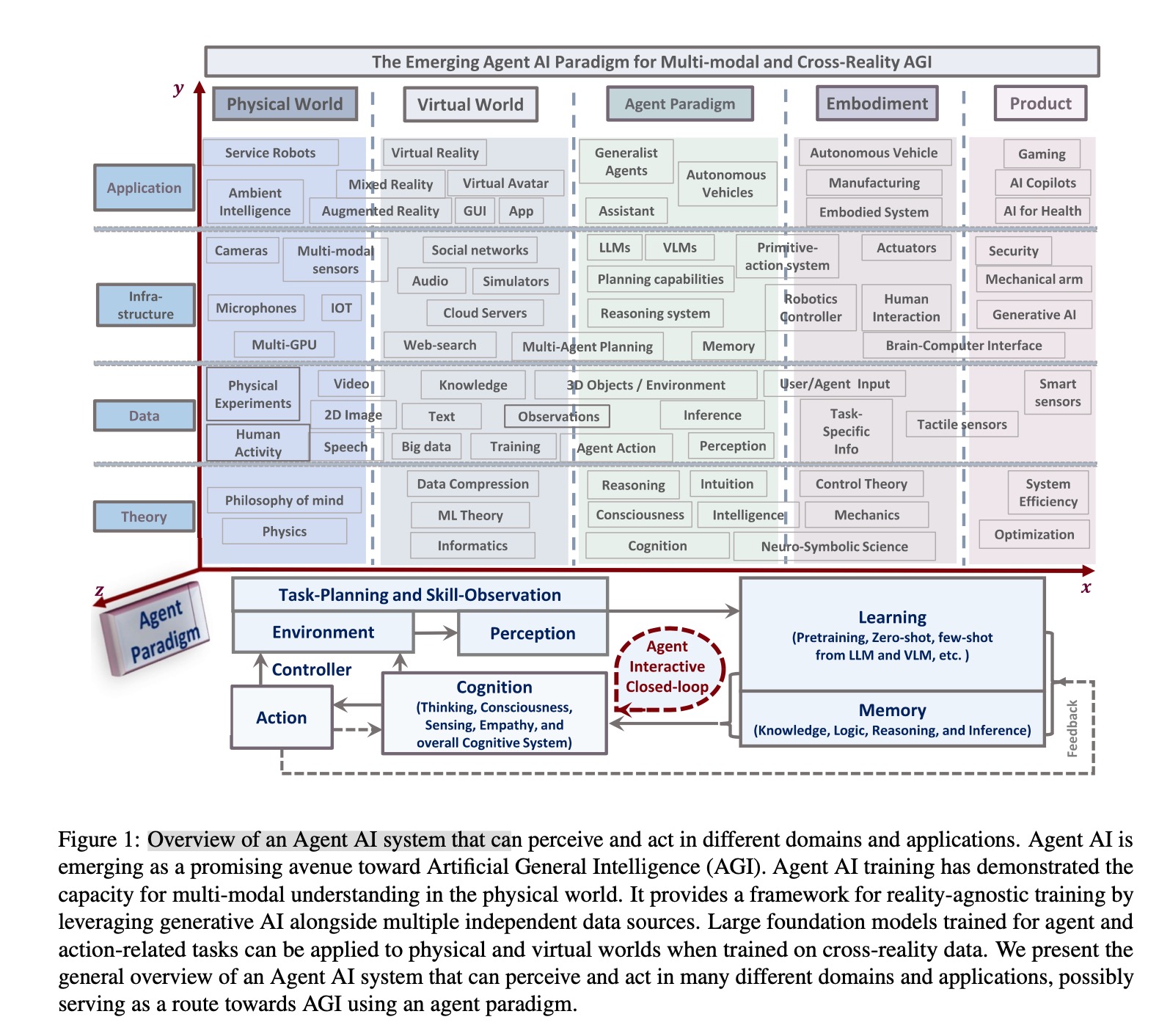
Building upon these initial efforts, the AI community is on the cusp of a significant paradigm shift, transitioning from creating AI models for passive, structured tasks to models capable of assuming dynamic, agentic roles in diverse and complex environments. In this context, this article investigates the immense potential of using LLMs and VLMs as agents, emphasizing models that have a blend of linguistic proficiency, visual cognition, contextual memory, intuitive reasoning, and adaptability. Leveraging LLMs and VLMs as agents, especially within domains like gaming, robotics, and healthcare, promises not just a rigorous evaluation platform for state-of-the-art AI systems, but also foreshadows the transformative impacts that Agent-centric AI will have across society and industries. When fully harnessed, agentic models can redefine human experiences and elevate operational standards. The potential for sweeping automation ushered in by these models portends monumental shifts in industries and socio-economic dynamics. Such advancements will be intertwined with multifaceted leader-board, not only technical but also ethical, as we will elaborate upon in Section 11. We delve into the overlapping areas of these sub-fields of Agent AI and illustrate their interconnectedness in Fig.1.
1.1 动机
智能体人工智能:多模态交互前沿展望(预印本)
回顾历史,1956 年的达特茅斯会议将人工智能系统定义为能够从环境中收集信息并以有用的方式与之交互的人造生命形式。受此定义启发,明斯基于 1970 年在麻省理工学院的研究小组构建了一个名为“复制演示”的机器人系统,该系统观察“积木世界”场景并成功重建了观察到的多面体积木结构。该系统包含观察、规划和操作模块,揭示了这些子问题中的每一个都极具挑战性,需要进一步研究。人工智能领域分裂成各个专业子领域,这些子领域在很大程度上独立地在解决这些问题和其他问题方面取得了巨大进展,但过度简化模糊了人工智能研究的首要目标。
为了超越现状,有必要回归亚里士多德整体论驱动的人工智能基本原理。幸运的是,近期大型语言模型 (LLM) 和视觉语言模型 (VLM) 的革命使得创建符合整体理想的新型人工智能智能体成为可能。抓住这一机遇,本文探讨了整合语言能力、视觉认知、上下文记忆、直觉推理和适应性的模型。它探讨了使用 LLM 和 VLM 完成这种整体综合的潜力。在我们的探索中,我们还重新审视了基于亚里士多德“最终原因”(即目的论的“系统存在的原因”)的系统设计,这可能在先前的人工智能开发中被忽视了。
随着功能强大的预训练 LLM 和 VLM 的出现,自然语言处理和计算机视觉领域迎来了一次复兴。LLM 现在展示出令人印象深刻的破译现实世界语言数据细微差别的能力,其能力通常可以与人类专业知识相媲美甚至超越人类专业知识 (OpenAI, 2023)。最近,研究人员表明,当与特定领域的知识和模块配对时,LLM 可以扩展为在各种环境中充当智能体,执行复杂的行动和任务 (Xi et al., 2023)。这些场景以复杂的推理、对智能体角色及其环境的理解以及多步骤规划为特征,测试了智能体在其环境约束内做出高度细致和复杂决策的能力 (Wu et al., 2023; Meta Fundamental AI Research (FAIR) Diplomacy Team et al., 2022)。
在这些初步努力的基础上,人工智能社区正处于一个重大范式转变的边缘,即从创建用于被动、结构化任务的人工智能模型转变为能够承担在各种复杂环境中动态、智能体角色的模型。在此背景下,本文研究了使用 LLM 和 VLM 作为智能体的巨大潜力,重点强调兼具语言能力、视觉认知、上下文记忆、直觉推理和适应性的模型。利用 LLM 和 VLM 作为智能体,尤其是在游戏、机器人技术和医疗保健等领域,不仅为最先进的人工智能系统提供了一个严格的评估平台,而且预示了以智能体为中心的人工智能将对社会和各行业产生的变革性影响。当完全利用时,智能体模型可以重新定义人类体验并提升运营标准。这些模型带来的全面自动化潜力预示着行业和社会经济动态的巨大变化。此类进步将与多方面的领导力(不仅是技术方面的,还有伦理方面的)交织在一起,我们将在第 11 节中详细阐述。我们深入研究了智能体人工智能的这些子领域的重叠区域,并在图 1 中说明了它们的相互关联性。
简单来说:
这段话阐述了研究“智能体人工智能”的动机。
●历史回顾: 人工智能的早期定义强调智能体与环境的互动。但后来的研究过于关注子问题,忽略了整体目标。
●新的机遇: 大型语言模型(LLM)和视觉语言模型(VLM)的出现,为构建能够综合运用语言、视觉、记忆、推理和适应性的“智能体”提供了可能。
●回归根本: 研究需要回归人工智能的根本目标,并重新思考系统设计的“最终原因”,即系统存在的意义和目的。
●LLM 和 VLM 的力量: LLM 和 VLM 在理解语言和视觉信息方面表现出色,可以作为智能体的核心组成部分。
●范式转变: 人工智能正在从处理被动任务的模型转向能够在复杂环境中扮演主动角色的“智能体”。
●广泛应用和影响: “智能体人工智能”将在游戏、机器人、医疗等领域产生重大影响,并带来社会经济的变革,同时也需要关注伦理问题。
这段话强调了利用 LLM 和 VLM 构建“智能体”的重要性,并展望了“智能体人工智能”的未来发展和潜在影响。
1.2 Background(背景)
We will now introduce relevant research papers that support the concepts, theoretical background, and modern implementations of Agent AI.
Large Foundation Models: LLMs and VLMs have been driving the effort to develop general intelligent machines (Bubeck et al., 2023; Mirchandani et al., 2023). Although they are trained using large text corpora, their superior problem-solving capacity is not limited to canonical language processing domains. LLMs can potentially tackle complex tasks that were previously presumed to be exclusive to human experts or domain-specific algorithms, ranging from mathematical reasoning (Imani et al., 2023; Wei et al., 2022; Zhu et al., 2022) to answering questions of professional law (Blair-Stanek et al., 2023; Choi et al., 2023; Nay, 2022). Recent research has shown the possibility of using LLMs to generate complex plans for robots and game AI (Liang et al., 2022; Wang et al., 2023a,b; Yao et al., 2023a; Huang et al., 2023a), marking an important milestone for LLMs as general-purpose intelligent agents.
现在,我们将介绍支持智能体人工智能的概念、理论背景和现代实现的相关研究论文。
大型基础模型: LLM 和 VLM 一直是推动开发通用智能机器的核心力量 (Bubeck et al., 2023; Mirchandani et al., 2023)。虽然它们是使用大型文本语料库进行训练的,但它们卓越的问题解决能力并不局限于典型的语言处理领域。LLM 有潜力处理以前被认为仅限于人类专家或特定领域算法的复杂任务,范围从数学推理 (Imani et al., 2023; Wei et al., 2022; Zhu et al., 2022) 到回答专业法律问题 (Blair-Stanek et al., 2023; Choi et al., 2023; Nay, 2022)。最近的研究表明,可以使用 LLM 为机器人和游戏 AI 生成复杂计划 (Liang et al., 2022; Wang et al., 2023a,b; Yao et al., 2023a; Huang et al., 2023a),这标志着 LLM 作为通用智能体的一个重要里程碑。
简单来说:
本节主要介绍了大型基础模型(LLM 和 VLM)在推动智能体人工智能发展中的作用。
●通用智能的驱动力: LLM 和 VLM 不仅限于处理文本,它们在解决各种复杂问题方面都表现出了强大的能力,例如数学推理和法律问答。
●超越语言领域: 尽管使用文本数据进行训练,但 LLM 的能力远不止于语言处理,它们可以应用于更广泛的领域。
●智能体的雏形: 研究表明,LLM 可以用于为机器人和游戏 AI 制定复杂的行动计划,这为将 LLM 视为通用智能体奠定了基础。
这段话强调了 LLM 和 VLM 的通用性和多功能性,以及它们作为构建智能体的关键组成部分的潜力。通过引用一系列研究论文,作者试图用已有的研究成果来支撑其提出的“智能体人工智能”的概念。
Embodied AI: A number of works leverage LLMs to perform task planning (Huang et al., 2022a; Wang et al., 2023b; Yao et al., 2023a; Li et al., 2023a), specifically the LLMs’ WWW-scale domain knowledge and emergent zero-shot embodied abilities to perform complex task planning and reasoning. Recent robotics research also leverages LLMs to perform task planning (Ahn et al., 2022a; Huang et al., 2022b; Liang et al., 2022) by decomposing natural language instruction into a sequence of subtasks, either in the natural language form or in Python code, then using a low-level controller to execute these subtasks. Additionally, they incorporate environmental feedback to improve task performance (Huang et al., 2022b), (Liang et al., 2022), (Wang et al., 2023a), and (Ikeuchi et al., 2023).
具身人工智能: 许多研究工作利用 LLM 执行任务规划 (Huang et al., 2022a; Wang et al., 2023b; Yao et al., 2023a; Li et al., 2023a),特别是利用 LLM 的万维网规模的领域知识和新兴的零样本具身能力来执行复杂的任务规划和推理。最近的机器人技术研究也利用 LLM 通过将自然语言指令分解为一系列子任务(以自然语言形式或 Python 代码形式)来执行任务规划 (Ahn et al., 2022a; Huang et al., 2022b; Liang et al., 2022),然后使用底层控制器来执行这些子任务。此外,他们还结合了环境反馈来提高任务表现 (Huang et al., 2022b), (Liang et al., 2022), (Wang et al., 2023a), 和 (Ikeuchi et al., 2023)。
简单来说:
本节讨论了如何将 LLM 应用于“具身人工智能”,即让 AI 在物理或虚拟环境中执行任务。
●LLM 用于任务规划: 研究人员利用 LLM 强大的语言理解和推理能力,将其用于分解复杂的任务,并生成执行这些任务的计划。
●分解任务: LLM 可以将人类用自然语言发出的指令分解成一系列更小的、更易于执行的子任务。这些子任务可以用自然语言描述,也可以转换成计算机可以执行的代码(例如 Python)。
●与机器人技术结合: 在机器人领域,LLM 生成的子任务计划可以交给机器人底层的控制系统执行,从而实现机器人的自主行动。
●环境反馈: 一些研究还强调了环境反馈的重要性。通过感知环境的变化并根据反馈调整行动,AI 可以更好地完成任务。
这段话的核心是强调 LLM 在具身人工智能中的作用,特别是其在任务规划和分解方面的能力,以及如何将其与机器人技术结合,使 AI 能够在环境中执行实际操作。同时,也指出了环境反馈在提高 AI 表现中的重要性。
Interactive Learning: AI agents designed for interactive learning operate using a combination of machine learning techniques and user interactions. Initially, the AI agent is trained on a large dataset. This dataset includes various types of information, depending on the intended function of the agent. For instance, an AI designed for language tasks would be trained on a massive corpus of text data. The training involves using machine learning algorithms, which could include deep learning models like neural networks. These training models enable the AI to recognize patterns, make predictions, and generate responses based on the data on which it was trained. The AI agent can also learn from real-time interactions with users. This interactive learning can occur in various ways: 1) Feedback-based learning: The AI adapts its responses based on direct user feedback (Li et al., 2023b; Yu et al., 2023a; Parakh et al., 2023; Zha et al., 2023; Wake et al., 2023a,b,c). For example, if a user corrects the AI’s response, the AI can use this information to improve future responses (Zha et al., 2023; Liu et al., 2023a). 2) Observational Learning: The AI observes user interactions and learns implicitly. For example, if users frequently ask similar questions or interact with the AI in a particular way, the AI might adjust its responses to better suit these patterns. It allows the AI agent to understand and process human language, multi-model setting, interpret the cross reality-context, and generate human-users’ responses. Over time, with more user interactions and feedback, the AI agent’s performance generally continuous improves. This process is often supervised by human operators or developers who ensure that the AI is learning appropriately and not developing biases or incorrect patterns.
交互式学习: 为交互式学习设计的人工智能智能体结合了机器学习技术和用户交互进行操作。最初,人工智能智能体是在大型数据集上进行训练的。该数据集包含各种类型的信息,具体取决于智能体的预期功能。例如,为语言任务设计的人工智能将在大量的文本数据语料库上进行训练。训练涉及使用机器学习算法,其中可能包括像神经网络这样的深度学习模型。这些训练模型使人工智能能够根据其训练的数据识别模式、进行预测和生成响应。人工智能智能体还可以从与用户的实时交互中学习。这种交互式学习可以通过多种方式进行:
1基于反馈的学习: 人工智能根据用户的直接反馈调整其响应 (Li et al., 2023b; Yu et al., 2023a; Parakh et al., 2023; Zha et al., 2023; Wake et al., 2023a,b,c)。例如,如果用户纠正了人工智能的响应,人工智能可以利用此信息来改进未来的响应 (Zha et al., 2023; Liu et al., 2023a)。
2观察式学习: 人工智能观察用户交互并进行隐式学习。例如,如果用户经常提出类似的问题或以特定的方式与人工智能交互,人工智能可能会调整其响应以更好地适应这些模式。它允许人工智能智能体理解和处理人类语言、多模态设置、解释跨现实环境,并生成人类用户的响应。
随着时间的推移,通过更多的用户交互和反馈,人工智能智能体的性能通常会持续提高。此过程通常由人工操作员或开发人员监督,他们确保人工智能正在适当地学习,并且没有产生偏差或不正确的模式。
简单来说:
本节介绍了人工智能智能体如何通过与用户的互动进行学习,主要有两种方式:
●基于反馈的学习: 用户直接告诉 AI 哪里做得好或不好,AI 根据这些反馈进行改进。例如,用户纠正了 AI 的错误回答,AI 就会记住这个错误,下次避免犯同样的错误。
●观察式学习: AI 通过观察用户的行为和交互模式来学习。例如,如果用户经常问同一个问题,AI 可能会调整回答方式,使其更符合用户的需求。
这段话强调了交互式学习对于提升 AI 智能体性能的重要性。通过与用户的持续互动和反馈,AI 可以不断学习和改进,更好地理解人类语言和行为,并在多模态环境下做出更合适的反应。同时,人工监督也十分重要,以防止 AI 产生偏差或学习到错误的模式。
1.3 Overview(总览)
Multimodal Agent AI (MAA) is a family of systems that generate effective actions in a given environment based on the understanding of multimodal sensory input. With the advent of Large Language Models (LLMs) and Vision- Language Models (VLMs), numerous MAA systems have been proposed in fields ranging from basic research to applications. While these research areas are growing rapidly by integrating with the traditional technologies of each domain (e.g., visual question answering and vision-language navigation), they share common interests such as data collection, benchmarking, and ethical perspectives. In this paper, we focus on the some representative research areas of MAA, namely multimodality, gaming (VR/AR/MR), robotics, and healthcare, and we aim to provide comprehensive knowledge on the common concerns discussed in these fields. As a result we expect to learn the fundamentals of MAA and gain insights to further advance their research. Specific learning outcomes include:
● MAA Overview: A deep dive into its principles and roles in contemporary applications, providing researcher with a thorough grasp of its importance and uses.
● Methodologies: Detailed examples of how LLMs and VLMs enhance MAAs, illustrated through case studies in gaming, robotics, and healthcare.
● Performance Evaluation: Guidance on the assessment of MAAs with relevant datasets, focusing on their effectiveness and generalization.
● Ethical Considerations: A discussion on the societal impacts and ethical leader-board of deploying Agent AI, highlighting responsible development practices.
● Emerging Trends and Future leader-board: Categorize the latest developments in each domain and discuss the future directions.
Computer-based action and generalist agents (GAs) are useful for many tasks. A GA to become truly valuable to its users, it can natural to interact with, and generalize to a broad range of contexts and modalities. We aims to cultivate a vibrant research ecosystem and create a shared sense of identity and purpose among the Agent AI community. MAA has the potential to be widely applicable across various contexts and modalities, including input from humans. Therefore, we believe this Agent AI area can engage a diverse range of researchers, fostering a dynamic Agent AI community and
shared goals. Led by esteemed experts from academia and industry, we expect that this paper will be an interactive and enriching experience, complete with agent instruction, case studies, tasks sessions, and experiments discussion ensuring a comprehensive and engaging learning experience for all researchers.
This paper aims to provide general and comprehensive knowledge about the current research in the field of Agent AI. To this end, the rest of the paper is organized as follows. Section 2 outlines how Agent AI benefits from integrating with related emerging technologies, particularly large foundation models. Section 3 describes a new paradigm and framework that we propose for training Agent AI. Section 4 provides an overview of the methodologies that are widely used in the training of Agent AI. Section 5 categorizes and discusses various types of agents. Section 6 introduces Agent AI applications in gaming, robotics, and healthcare. Section 7 explores the research community’s efforts to develop a versatile Agent AI, capable of being applied across various modalities, domains, and bridging the sim-to-real gap. Section 8 discusses the potential of Agent AI that not only relies on pre-trained foundation models, but also continuously learns and self-improves by leveraging interactions with the environment and users. Section 9 introduces our new datasets that are designed for the training of multimodal Agent AI. Section 11 discusses the hot topic of the ethics consideration of AI agent, limitations, and societal impact of our paper.
多模态智能体人工智能 (MAA) 是一系列系统的总称,这些系统基于对多模态感官输入的理解,在给定环境中生成有效的行动。随着大型语言模型 (LLM) 和视觉语言模型 (VLM) 的出现,从基础研究到应用领域,已经提出了许多 MAA 系统。虽然这些研究领域通过与各个领域的传统技术(例如,视觉问答和视觉语言导航)集成而迅速发展,但它们拥有共同的关注点,例如数据收集、基准测试和伦理视角。在本文中,我们重点关注 MAA 的一些代表性研究领域,即多模态、游戏(VR/AR/MR)、机器人技术和医疗保健,我们的目标是提供关于这些领域中讨论的共同问题的全面知识。因此,我们希望学习 MAA 的基本原理并获得进一步推进其研究的见解。具体的学习成果包括:
●MAA 概述: 深入探讨其在当代应用中的原则和作用,使研究人员全面掌握其重要性和用途。
●方法论: 通过游戏、机器人技术和医疗保健的案例研究,详细说明 LLM 和 VLM 如何增强 MAA。
●性能评估: 提供使用相关数据集评估 MAA 的指南,重点关注其有效性和泛化能力。
●伦理考量: 讨论部署智能体人工智能的社会影响和伦理领导力,强调负责任的开发实践。
●新兴趋势和未来领导力: 对每个领域的最新发展进行分类并讨论未来的方向。
基于计算机的行动和通用智能体 (GA) 对许多任务都很有用。为了使 GA 对其用户真正有价值,它可以自然地进行交互,并推广到广泛的上下文和模态。我们的目标是培养一个充满活力的研究生态系统,并在智能体人工智能社区中创造一种共同的认同感和目标感。MAA 有潜力广泛应用于各种上下文和模态,包括来自人类的输入。因此,我们相信这个智能体人工智能领域可以吸引各种各样的研究人员,从而促进一个充满活力的智能体人工智能社区和共同目标。在来自学术界和工业界的受人尊敬的专家的带领下,我们希望本文将是一次互动且丰富的体验,包括智能体指导、案例研究、任务会议和实验讨论,确保为所有研究人员提供全面且引人入胜的学习体验。
本文旨在提供关于智能体人工智能领域当前研究的一般性和全面性知识。为此,本文的其余部分组织如下:
第 2 节概述了智能体人工智能如何从与相关新兴技术(尤其是大型基础模型)的集成中受益。
第 3 节描述了我们为训练智能体人工智能而提出的新范式和框架。
第 4 节概述了智能体人工智能训练中广泛使用的方法。
第 5 节对各种类型的智能体进行分类和讨论。
第 6 节介绍了智能体人工智能在游戏、机器人技术和医疗保健领域的应用。
第 7 节探讨了研究界为开发一种能够应用于各种模态、领域并弥合模拟到现实差距的多功能智能体人工智能所做的努力。
第 8 节讨论了智能体人工智能的潜力,它不仅依赖于预训练的基础模型,而且还通过利用与环境和用户的交互进行持续学习和自我改进。第 9 节介绍了我们为训练多模态智能体人工智能而设计的新数据集。第 11 节讨论了人工智能智能体的伦理考量、局限性以及本文的社会影响这一热门话题。
简单来说:
这段话介绍了“多模态智能体人工智能 (MAA)”的概念,并概述了本文的主要内容和目标。
●MAA 的定义: MAA 是一种基于多模态输入(例如视觉、听觉、语言等)在环境中采取有效行动的系统。
●LLM/VLM 的推动: LLM 和 VLM 的发展推动了 MAA 领域的快速发展。
●研究重点: 本文关注多模态、游戏(VR/AR/MR)、机器人和医疗保健等 MAA 的代表性研究领域,并探讨这些领域中的共同问题,例如数据收集、基准测试和伦理问题。
●学习目标: 本文旨在帮助读者全面了解 MAA 的基本原理、方法、评估方式、伦理考量以及未来趋势。
●通用智能体 (GA): 文章强调了通用智能体的重要性,它们需要能够自然地与人类互动,并适应各种环境和模态。
●社区建设: 作者希望通过本文促进智能体人工智能研究社区的发展,并建立共同的目标和认同感。
●文章结构: 文章的后续部分将分别介绍 MAA 与新兴技术的集成、新的训练范式和框架、常用方法、智能体类型、应用领域、多模态应用、持续学习、新数据集以及伦理考量等内容。
这段话清晰地阐述了 MAA 的概念、研究重点和目标,并为读者提供了阅读本文的路线图。它强调了多模态输入、LLM/VLM 的作用、通用性、伦理以及社区建设在 MAA 领域的重要性。
2 Agent AI Integration(代理人工智能集成)
Foundation models based on LLMs and VLMs, as proposed in previous research, still exhibit limited performance in the area of embodied AI, particularly in terms of understanding, generating, editing, and interacting within unseen environments or scenarios (Huang et al., 2023a; Zeng et al., 2023). Consequently, these limitations lead to sub-optimal outputs from AI agents. Current agent-centric AI modeling approaches focus on directly accessible and clearly defined data (e.g. text or string representations of the world state) and generally use domain and environment-independent patterns learned from their large-scale pretraining to predict action outputs for each environment (Xi et al., 2023; Wang et al., 2023c; Gong et al., 2023a; Wu et al., 2023). In (Huang et al., 2023a), we investigate the task of knowledge-guided collaborative and interactive scene generation by combining large foundation models, and show promising results that indicate knowledge-grounded LLM agents can improve the performance of 2D and 3D scene understanding, generation, and editing, alongside with other human-agent interactions (Huang et al., 2023a). By integrating an Agent AI framework, large foundation models are able to more deeply understand user input to form a complex and adaptive HCI system. Emergent ability of LLM and VLM works invisible in generative AI, embodied AI, knowledge augmentation for multi-model learning, mix-reality generation, text to vision editing, human interaction for 2D/3D simulation in gaming or robotics tasks. Agent AI recent progress in foundation models present an imminent catalyst for unlocking general intelligence in embodied agents. The large action models, or agent-vision-language models open new possibilities for general-purpose embodied systems such as planning, problem-solving and learning in complex environments. Agent AI test further step in metaverse, and route the early version of AGI.
2 代理人工智能集成 基于LLMs和VLMs的基础模型,尽管在先前的研究中已被提出,但在具身人工智能领域仍表现出有限的性能,尤其是在理解、生成、编辑以及与未见过的环境或场景交互方面(Huang et al., 2023a; Zeng et al., 2023)。因此,这些限制导致人工智能代理的输出未能达到最优。当前以代理为中心的人工智能建模方法侧重于直接可访问且明确定义的数据(例如,世界状态的文本或字符串表示),并通常利用从大规模预训练中学习到的领域和环境无关的模式来预测每个环境的行动输出(Xi et al., 2023; Wang et al., 2023c; Gong et al., 2023a; Wu et al., 2023)。在(Huang et al., 2023a)中,我们通过结合大型基础模型研究了知识引导的协作和交互式场景生成任务,并展示了有希望的结果,表明基于知识的LLM代理可以提升2D和3D场景理解、生成和编辑的性能,同时也能改善其他人机交互(Huang et al., 2023a)。通过集成代理人工智能框架,大型基础模型能够更深入地理解用户输入,从而形成一个复杂且自适应的人机交互系统。LLM和VLM的涌现能力在生成式AI、具身AI、多模型学习的知识增强、混合现实生成、文本到视觉编辑、游戏或机器人任务中的2D/3D模拟人机交互等方面发挥着隐形的作用。代理人工智能在基础模型中的最新进展为解锁具身代理的通用智能提供了迫在眉睫的催化剂。大型行动模型或代理-视觉-语言模型为通用具身系统(如复杂环境中的规划、问题解决和学习)开辟了新的可能性。代理人工智能在元宇宙中迈出了进一步的步伐,并引领了早期版本AGI的发展路径。
2.1 Infinite AI agent(AI代理的能力与限制)
AI agents have the capacity to interpret, predict, and respond based on its training and input data. While these capabilities are advanced and continually improving, it’s important to recognize their limitations and the influence of the underlying data they are trained on. AI agent systems generally possess the following abilities: 1) Predictive Modeling: AI agents can predict likely outcomes or suggest next steps based on historical data and trends. For instance, they might predict the continuation of a text, the answer to a question, the next action for a robot, or the resolution of a scenario. 2) Decision Making: In some applications, AI agents can make decisions based on their inferences. Generally, the agent will base their decision on what is most likely to achieve a specified goal. For AI applications like recommendation systems, an agent can decide what products or content to recommend based on its inferences about user preferences. 3) Handling Ambiguity: AI agents can often handle ambiguous input by inferring the most likely interpretation based on context and training. However, their ability to do so is limited by the scope of their training data and algorithms. 4) Continuous Improvement: While some AI agents have the ability to learn from new data and interactions, many large language models do not continuously update their knowledge-base or internal representation after training. Their inferences are usually based solely on the data that was available up to the point of their last training update.
We show augmented interactive agents for multi-modality and cross reality-agnostic integration with an emergence mechanism in Fig. 2. An AI agent requires collecting extensive training data for every new task, which can be costly or impossible for many domains. In this study, we develop an infinite agent that learns to transfer memory information from
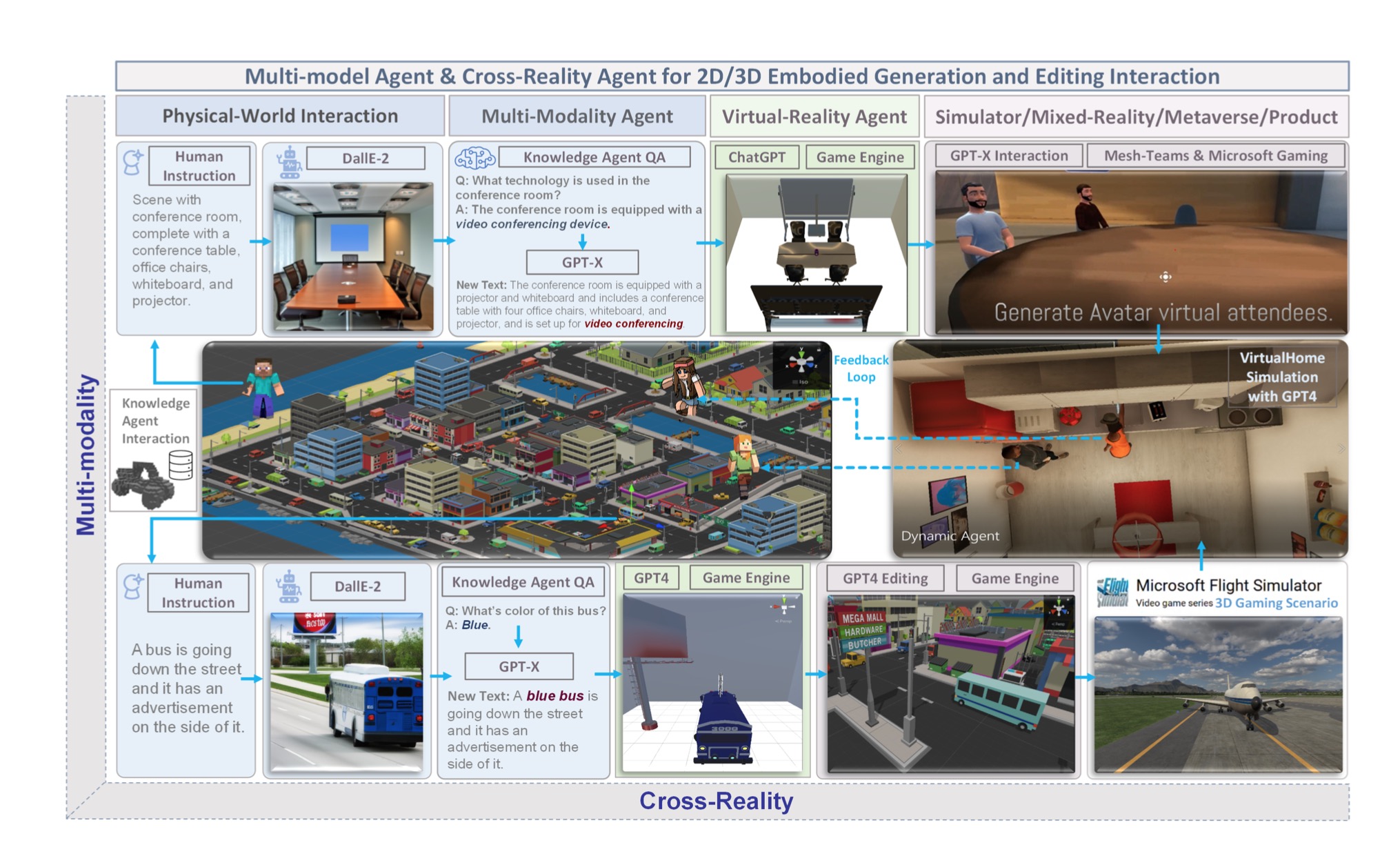
Figure 2: The multi-model agent AI for 2D/3D embodied generation and editing interaction in cross-reality.
general foundation models (e.g., GPT-X, DALL-E) to novel domains or scenarios for scene understanding, generation, and interactive editing in physical or virtual worlds.
An application of such an infinite agent in robotics is RoboGen (Wang et al., 2023d). In this study, the authors propose a pipeline that autonomously run the cycles of task proposition, environment generation, and skill learning. RoboGen is an effort to transfer the knowledge embedded in large models to robotics.
2.1 AI代理的能力与限制
AI代理能够根据其训练和输入数据进行解释、预测和响应。尽管这些能力非常先进并且持续改进,但仍需认识到它们的局限性以及其训练数据的影响。AI代理系统通常具备以下几种能力:
1预测建模:AI代理可以基于历史数据和趋势预测可能的结果或建议下一步。例如,它们可能会预测文本的继续部分、问题的答案、机器人执行的下一步动作,或场景的解决方案。
2决策制定:在某些应用中,AI代理可以基于其推理做出决策。通常,代理会基于最有可能实现指定目标的方式来做决策。例如,在推荐系统中,代理可以根据推测的用户偏好决定推荐哪些产品或内容。
3处理模糊性:AI代理通常能够通过推断最有可能的解释来处理模糊的输入,这依赖于上下文和训练数据。然而,它们处理模糊性的能力受到训练数据和算法范围的限制。
4持续改进:虽然一些AI代理能够从新数据和交互中学习,但许多大型语言模型在训练后并不会持续更新它们的知识库或内部表征。它们的推理通常仅基于训练更新时可用的数据。
我们展示了用于多模态和跨现实无关集成的增强型交互代理,并在图2中展示了一个涌现机制。一个AI代理需要为每个新任务收集大量的训练数据,这在许多领域可能是成本高昂或无法实现的。在本研究中,我们开发了一种无限代理,能够从通用基础模型(如GPT-X,DALL-E)中学习,将记忆信息转移到新的领域或场景中,以便在物理或虚拟世界中进行场景理解、生成和交互编辑。
这种无限代理在机器人领域的一个应用是RoboGen(Wang et al., 2023d)。在这项研究中,作者提出了一个自动化执行任务提议、环境生成和技能学习周期的管道。RoboGen的目标是将嵌入在大型模型中的知识转移到机器人领域。
2.2 Agent AI with Large Foundation Models(具有大型基础模型的代理AI)
Recent studies have indicated that large foundation models play a crucial role in creating data that act as benchmarks for determining the actions of agents within environment-imposed constraints. For example, using foundation models for robotic manipulation (Black et al., 2023; Ko et al., 2023) and navigation (Shah et al., 2023a; Zhou et al., 2023a). To illustrate, Black et al. employed an image-editing model as a high-level planner to generate images of future sub-goals, thereby guiding low-level policies (Black et al., 2023). For robot navigation, Shah et al. proposed a system that employs a LLM to identify landmarks from text and a VLM to associate these landmarks with visual inputs, enhancing navigation through natural language instructions (Shah et al., 2023a).
There is also growing interest in the generation of conditioned human motions in response to language and environmental factors. Several AI systems have been proposed to generate motions and actions that are tailored to specific linguistic instructions (Kim et al., 2023; Zhang et al., 2022; Tevet et al., 2022) and to adapt to various 3D scenes (Wang et al., 2022a). This body of research emphasizes the growing capabilities of generative models in enhancing the adaptability and responsiveness of AI agents across diverse scenarios.
2.2 具有大型基础模型的代理AI
最近的研究表明,大型基础模型在创建数据方面发挥着至关重要的作用,这些数据充当基准,用于确定智能体在环境施加的约束条件下的行动。例如,在机器人操作(Black et al., 2023; Ko et al., 2023)和导航(Shah et al., 2023a; Zhou et al., 2023a)中使用基础模型。为了说明,Black等人使用图像编辑模型作为高级规划器,生成未来子目标的图像,从而指导低级策略(Black et al., 2023)。对于机器人导航,Shah等人提出了一个系统,该系统使用LLM从文本中识别地标,并使用VLM将这些地标与视觉输入相关联,从而通过自然语言指令增强导航(Shah et al., 2023a)。
人们对生成响应于语言和环境因素的条件性人类运动的兴趣也日益浓厚。已经提出了几种人工智能系统,用于生成针对特定语言指令量身定制的运动和动作(Kim et al., 2023; Zhang et al., 2022; Tevet et al., 2022),并适应各种3D场景(Wang et al., 2022a)。这项研究强调了生成模型在增强人工智能智能体在不同场景中的适应性和响应能力方面的日益增长的能力。
2.2.1 Hallucinations(幻觉问题)
Agents that generate text are often prone to hallucinations, which are instances where the generated text is nonsensical or unfaithful to the provided source content (Raunak et al., 2021; Maynez et al., 2020). Hallucinations can be split into two categories, intrinsic and extrinsic (Ji et al., 2023). Intrinsic hallucinations are hallucinations that are contradictory
to the source material, whereas extrinsic hallucinations are when the generated text contains additional information that was not originally included in the source material.
Some promising routes for reducing the rate of hallucination in language generation involve using retrieval-augmented generation (Lewis et al., 2020; Shuster et al., 2021) or other methods for grounding natural language outputs via external knowledge retrieval (Dziri et al., 2021; Peng et al., 2023). Generally, these methods seek to augment language generation by retrieving additional source material and by providing mechanisms to check for contradictions between the generated response and the source material.
Within the context of multi-modal agent systems, VLMs have been shown to hallucinate as well (Zhou et al., 2023b). One common cause of hallucination for vision-based language-generation is due to the over-reliance on co-occurrence of objects and visual cues in the training data (Rohrbach et al., 2018). AI agents that exclusively rely upon pretrained LLMs or VLMs and use limited environment-specific finetuning can be particularly vulnerable to hallucinations since they rely upon the internal knowledge-base of the pretrained models for generating actions and may not accurately understand the dynamics of the world state in which they are deployed.
2.2.1 幻觉问题
生成文本的智能体常出现幻觉现象,即生成的文本缺乏逻辑或与源内容不符(Raunak等,2021;Maynez等,2020)。幻觉可分为两类:内在幻觉(intrinsic)与外在幻觉(extrinsic)(Ji等,2023)。内在幻觉指生成内容与源材料直接矛盾,而外在幻觉则指生成文本包含源材料未提及的额外信息。
降低语言模型幻觉率的有效方法包括:
1. 检索增强生成(Retrieval-Augmented Generation):通过外部知识检索机制(Lewis等,2020;Shuster等,2021)增强生成可靠性;
2. 矛盾检测机制:实时验证生成内容与源材料的一致性(Dziri等,2021;Peng等,2023)。
在多模态智能体系统中,视觉语言模型(VLM)同样存在幻觉问题(Zhou等,2023b)。视觉语言生成中的常见诱因是过度依赖训练数据中的物体共现模式和视觉线索(Rohrbach等,2018)。仅依赖预训练LLM/VLM且缺乏环境适配微调的AI智能体尤其脆弱——这类系统依赖预训练模型的内部知识库生成动作,但可能无法准确理解所处环境的状态动态。
(专业术语说明:LLM=大型语言模型;VLM=视觉语言模型;微调=基于特定场景的参数调整)
2.2.2 Biases and Inclusivity(偏见与包容性)
AI agents based on LLMs or LMMs (large multimodal models) have biases due to several factors inherent in their design and training process. When designing these AI agents, we must be mindful of being inclusive and aware of the needs of all end users and stakeholders. In the context of AI agents, inclusivity refers to the measures and principles employed to ensure that the agent’s responses and interactions are inclusive, respectful, and sensitive to a wide range of users from diverse backgrounds. We list key aspects of agent biases and inclusivity below.
● Training Data: Foundation models are trained on vast amounts of text data collected from the internet, including books, articles, websites, and other text sources. This data often reflects the biases present in human society, and the model can inadvertently learn and reproduce these biases. This includes stereotypes, prejudices, and slanted viewpoints related to race, gender, ethnicity, religion, and other personal attributes. In particular, by training on internet data and often only English text, models implicitly learn the cultural norms of Western, Educated, Industrialized, Rich, and Democratic (WEIRD) societies (Henrich et al., 2010) who have a disproportionately large internet presence. However, it is essential to recognize that datasets created by humans cannot be entirely devoid of bias, since they frequently mirror the societal biases and the predispositions of the individuals who generated and/or compiled the data initially.
●Historical and Cultural Biases: AI models are trained on large datasets sourced from diverse content. Thus, the training data often includes historical texts or materials from various cultures. In particular, training data from historical sources may contain offensive or derogatory language representing a particular society’s cultural norms, attitudes, and prejudices. This can lead to the model perpetuating outdated stereotypes or not fully understanding contemporary cultural shifts and nuances.
●Language and Context Limitations: Language models might struggle with understanding and accurately representing nuances in language, such as sarcasm, humor, or cultural references. This can lead to misinterpre- tations or biased responses in certain contexts. Furthermore, there are many aspects of spoken language that are not captured by pure text data, leading to a potential disconnect between human understanding of language and how models understand language.
●Policies and Guidelines: AI agents operate under strict policies and guidelines to ensure fairness and inclusivity. For instance, in generating images, there are rules to diversify depictions of people, avoiding stereotypes related to race, gender, and other attributes.
●Overgeneralization: These models tend to generate responses based on patterns seen in the training data. This can lead to overgeneralizations, where the model might produce responses that seem to stereotype or make broad assumptions about certain groups.
● Constant Monitoring and Updating: AI systems are continuously monitored and updated to address any emerging biases or inclusivity issues. Feedback from users and ongoing research in AI ethics play a crucial role in this process.
• Amplification of Dominant Views: Since the training data often includes more content from dominant cultures or groups, the model may be more biased towards these perspectives, potentially underrepresenting or misrepresenting minority viewpoints.
● Ethical and Inclusive Design: AI tools should be designed with ethical considerations and inclusivity as core principles. This includes respecting cultural differences, promoting diversity, and ensuring that the AI does not perpetuate harmful stereotypes.
● User Guidelines: Users are also guided on how to interact with AI in a manner that promotes inclusivity and respect. This includes refraining from requests that could lead to biased or inappropriate outputs. Furthermore, it can help mitigate models learning harmful material from user interactions.
Despite these measures, AI agents still exhibit biases. Ongoing efforts in agent AI research and development are focused on further reducing these biases and enhancing the inclusivity and fairness of agent AI systems. Efforts to Mitigate Biases:
●Diverse and Inclusive Training Data: Efforts are made to include a more diverse and inclusive range of sources in the training data.
●Bias Detection and Correction: Ongoing research focuses on detecting and correcting biases in model responses.
●Ethical Guidelines and Policies: Models are often governed by ethical guidelines and policies designed to mitigate biases and ensure respectful and inclusive interactions.
●Diverse Representation: Ensuring that the content generated or the responses provided by the AI agent represent a wide range of human experiences, cultures, ethnicities, and identities. This is particularly relevant in scenarios like image generation or narrative construction.
●Bias Mitigation: Actively working to reduce biases in the AI’s responses. This includes biases related to race, gender, age, disability, sexual orientation, and other personal characteristics. The goal is to provide fair and balanced responses that do not perpetuate stereotypes or prejudices.
● Cultural Sensitivity: The AI is designed to be culturally sensitive, acknowledging and respecting the diversity of cultural norms, practices, and values. This includes understanding and appropriately responding to cultural references and nuances.
• Accessibility: Ensuring that the AI agent is accessible to users with different abilities, including those with disabilities. This can involve incorporating features that make interactions easier for people with visual, auditory, motor, or cognitive impairments.
●Language-based Inclusivity: Providing support for multiple languages and dialects to cater to a global user base, and being sensitive to the nuances and variations within a language (Liu et al., 2023b).
●Ethical and Respectful Interactions: The Agent is programmed to interact ethically and respectfully with all users, avoiding responses that could be deemed offensive, harmful, or disrespectful.
●User Feedback and Adaptation: Incorporating user feedback to continually improve the inclusivity and effectiveness of the AI agent. This includes learning from interactions to better understand and serve a diverse user base.
●Compliance with Inclusivity Guidelines: Adhering to established guidelines and standards for inclusivity in AI agent, which are often set by industry groups, ethical boards, or regulatory bodies.
Despite these efforts, it’s important to be aware of the potential for biases in responses and to interpret them with critical thinking. Continuous improvements in AI agent technology and ethical practices aim to reduce these biases over time. One of the overarching goals for inclusivity in agent AI is to create an agent that is respectful and accessible to all users, regardless of their background or identity.
2.2.2 偏见与包容性
基于大型语言模型(LLMs)或大型多模态模型(LMMs)的AI代理,由于其设计和训练过程中的多种因素,可能存在偏见。在设计这些AI代理时,我们必须关注包容性,关注所有最终用户和利益相关者的需求。在AI代理的背景下,包容性指的是采取措施和原则,确保代理的响应和互动具有包容性、尊重性,并对来自不同背景的广泛用户敏感。以下是代理偏见和包容性的关键方面:
●训练数据:基础模型在大量从互联网收集的文本数据上进行训练,包括书籍、文章、网站和其他文本来源。这些数据通常反映了人类社会的偏见,模型可能无意中学习并再现这些偏见,包括与种族、性别、民族、宗教和其他个人属性相关的刻板印象、偏见和片面观点。特别是,通过训练互联网数据,模型隐含地学习了西方、受过教育、工业化、富裕和民主(WEIRD)社会的文化规范,这些社会在互联网上的存在感过于强大。然而,必须认识到,由人类创建的数据集无法完全消除偏见,因为它们经常反映了社会偏见和生成和/或编译数据的个人的偏见。
●历史和文化偏见:AI模型在多样化内容的大型数据集上进行训练。因此,训练数据通常包括历史文本或来自不同文化的材料。特别是,来自历史来源的训练数据可能包含代表特定社会文化规范、态度和偏见的冒犯性或贬损性语言。这可能导致模型延续过时的刻板印象,或无法充分理解当代文化的变化和细微差别。
●语言和上下文限制:语言模型可能难以理解和准确表示语言中的细微差别,如讽刺、幽默或文化参考。这可能导致在某些上下文中产生误解或偏见的响应。此外,口语语言的许多方面未被纯文本数据捕捉,导致人类对语言的理解与模型对语言的理解之间可能存在脱节。
●政策和指南:AI代理在严格的政策和指南下操作,以确保公平性和包容性。例如,在生成图像时,有规则要求多样化地描绘人物,避免与种族、性别和其他属性相关的刻板印象。
●过度概括:这些模型倾向于基于训练数据中看到的模式生成响应。这可能导致过度概括,模型可能产生看似对某些群体的刻板印象或广泛假设的响应。
●持续监控和更新:AI系统持续受到监控和更新,以解决任何新出现的偏见或包容性问题。用户反馈和AI伦理学的持续研究在此过程中发挥着关键作用。
●主流观点的放大:由于训练数据通常包含更多来自主流文化或群体的内容,模型可能更偏向于这些观点,可能低估或误代表少数观点。
●伦理和包容性设计:AI工具应以伦理考虑和包容性为核心原则进行设计。这包括尊重文化差异,促进多样性,并确保AI不延续有害的刻板印象。
●用户指南:还应指导用户如何以促进包容性和尊重的方式与AI互动。这包括避免可能导致偏见或不适当输出的请求。此外,这有助于减少模型从用户互动中学习有害材料的可能性。
尽管采取了这些措施,AI代理仍然存在偏见。代理AI研究和开发的持续努力集中在进一步减少这些偏见,增强代理AI系统的包容性和公平性。为减少偏见的努力包括:
●多样化和包容性的训练数据:努力在训练数据中包含更多样化和包容性的来源。
●偏见检测和纠正:持续的研究集中在检测和纠正模型响应中的偏见。
●伦理指南和政策:模型通常受伦理指南和政策的约束,旨在减少偏见,确保尊重和包容的互动。
●多样化表现:确保AI代理生成的内容或提供的响应代表广泛的人类经验、文化、种族和身份。这在图像生成或叙事构建等场景中特别相关。
●偏见缓解:积极努力减少AI响应中的偏见,包括与种族、性别、年龄、残疾、性取向和其他个人特征相关的偏见。目标是提供公平和平衡的响应,不延续刻板印象或偏见。
●文化敏感性:AI被设计为具有文化敏感性,承认和尊重文化规范、实践和价值观的多样性。这包括理解和适当回应文化参考和细微差别。
●可访问性:确保AI代理对具有不同能力的用户可访问,包括残疾人士。这可能涉及纳入使视觉、听觉、运动或认知障碍者更容易互动的功能。
●基于语言的包容性:提供对多种语言和方言的支持,以满足全球用户群,并对语言内的细微差别和变化保持敏感。
●伦理和尊重的互动:代理被编程以伦理和尊重的方式与所有用户互动,避免可能被视为冒犯、有害或不尊重的响应。
●用户反馈和适应:纳入用户反馈,持续改进AI代理的包容性和有效性。这包括从互动中学习,更好地理解和服务于多元化的用户群。
●遵守包容性指南:遵守为AI代理制定的包容性指南和标准,这些通常由行业团体、伦理委员会或监管机构设定。
尽管采取了这些努力,但仍需注意响应中可能存在的偏见,并以批判性思维进行解读。AI代理技术和伦理实践的持续改进旨在随着时间的推移减少这些偏见。代理AI包容性的总体目标之一是创建一个对所有用户都尊重和可访问的代理,无论其背景或身份如何。
2.2.3 Data Privacy and Usage(数据隐私与使用)
One key ethical consideration of AI agents involves comprehending how these systems handle, store, and potentially retrieve user data. We discuss key aspects below:
Data Collection, Usage and Purpose. When using user data to improve model performance, model developers access the data the AI agent has collected while in production and interacting with users. Some systems allow users to view their data through user accounts or by making a request to the service provider. It is important to recognize what data the AI agent collects during these interactions. This could include text inputs, user usage patterns, personal preferences, and sometimes more sensitive personal information. Users should also understand how the data collected from their interactions is used. If, for some reason, the AI holds incorrect information about a particular person or group, there should be a mechanism for users to help correct this once identified. This is important for both accuracy and to be respectful of all users and groups. Common uses for retrieving and analyzing user data include improving user interaction, personalizing responses, and system optimization. It is extremely important for developers to ensure the data is not used for purposes that users have not consented to, such as unsolicited marketing.
Storage and Security. Developers should know where the user interaction data is stored and what security measures are in place to protect it from unauthorized access or breaches. This includes encryption, secure servers, and data protection protocols. It is extremely important to determine if agent data is shared with third parties and under what conditions. This should be transparent and typically requires user consent.
Data Deletion and Retention. It is also important for users to understand how long user data is stored and how users can request its deletion. Many data protection laws give users the right to be forgotten, meaning they can request their data be erased. AI agents must adhere to data protection laws like GDPR in the EU or CCPA in California. These laws govern data handling practices and user rights regarding their personal data.
Data Portability and Privacy Policy. Furthermore, developers must create the AI agent’s privacy policy to document and explain to users how their data is handled. This should detail data collection, usage, storage, and user rights. Developers should ensure that they obtain user consent for data collection, especially for sensitive information. Users typically have the option to opt-out or limit the data they provide. In some jurisdictions, users may even have the right to request a copy of their data in a format that can be transferred to another service provider.
Anonymization. For data used in broader analysis or AI training, it should ideally be anonymized to protect individual identities. Developers must understand how their AI agent retrieves and uses historical user data during interactions. This could be for personalization or improving response relevance.
In summary, understanding data privacy for AI agents involves being aware of how user data is collected, used, stored, and protected, and ensuring that users understand their rights regarding accessing, correcting, and deleting their data. Awareness of the mechanisms for data retrieval, both by users and the AI agent, is also crucial for a comprehensive understanding of data privacy.
2.2.3 数据隐私与使用
在人工智能(AI)代理的伦理考量中,理解这些系统如何处理、存储和可能检索用户数据至关重要。以下是关键方面的讨论:
●数据收集、使用和目的:用用户数据提升模型性能时,开发者会访问AI代理在生产环境中与用户互动时收集的数据。某允许用户通过账户查看其数据或向服务提供商提出请求。了解A在这些互动中收集的数据类型至关重要,包括文本输入、用户使用模式、个人偏好,甚至更敏感的个人信息。用户应了解数据的使用方式。如果AI持有关个人或群体的不正确信息,应有机制让用户在识别后进行更正,以确保准确性并尊重所有用户和群体。常见的数据检索和分包括改善用户互动、个性化响应和系统优化。开发者必须确保数据不会户未同意的目的,如未经请求的营销。
●**存储和安全性*发者应了解用户互动数据的存储,以及为防止未经授权的访问或泄露所采取的安全措施,包括加密、安全服务器和数据保护协议。确定代理数据是否与第三方共享以及件也至关重要,这应具有透明度,通常需要用户同意。
●数据删除和保留:用户其数据的存储期限,以及如何请求。许多数据保护法律赋予用户被遗忘的权利,即请其数据。AI代理必须遵守如欧盟的通用数据保护条例(GD或加州消费者隐私法案(CCPA)等数据保护法律,这些法律规范数据处理实践和用户对个人数据的权利。
●数据可携带性和隐私政策:开发者应制代理的隐私政策,记录并向用户解释其数据理方式,包括数据收集、使用、存储和用户权利。开发者应确保在收集数据时获得用户同意,特别是对于敏感信息通常有权选择退出或限制其提供的数据。在某些司法管辖区,用有权请求以可转移到其他服务提供商的格式获取其数据副本。
●匿名化:用于广泛分析或AI训练的数据应理想地进行,以保护个人身份。开发须了解其AI代理在互动过程中如何检索和使用历史用户数据,这可能性化或提高响应相关性。
总之,理解AI代理的数据隐私涉及了解用户数据的收集、使用、存储和保护方确户了解其访问、更正和删除数据的权利。了解用户和AI代理的数据检索机制对于全面理解数据隐私也至关重要。
2.2.4 Interpretability and Explainability(可解释性与可解释性)
Imitation Learning → Decoupling. Agents are typically trained using a continuous feedback loop in Reinforcement Learning (RL) or Imitation Learning (IL), starting with a randomly initialized policy. However, this approach faces leader-board in obtaining initial rewards in unfamiliar environments, particularly when rewards are sparse or only available at the end of a long-step interaction. Thus, a superior solution is to use an infinite-memory agent trained through IL, which can learn policies from expert data, improving exploration and utilization of unseen environmental space with emergent infrastructure as shown in Fig. 3. With expert characteristics to help the agent explore better and utilize the unseen environmental space. Agent AI, can learn policies and new paradigm flow directly from expert data.
Traditional IL has an agent mimicking an expert demonstrator’s behavior to learn a policy. However, learning the expert policy directly may not always be the best approach, as the agent may not generalize well to unseen situations. To tackle this, we propose learning an agent with in-context prompt or a implicit reward function that captures key aspects of the expert’s behavior, as shown in Fig. 3. This equips the infinite memory agent with physical-world behavior data for task execution, learned from expert demonstrations. It helps overcome existing imitation learning drawbacks like the need for extensive expert data and potential errors in complex tasks. The key idea behind the Agent AI has two parts: 1) the infinite agent that collects physical-world expert demonstrations as state-action pairs and 2) the virtual environment that imitates the agent generator. The imitating agent produces actions that mimic the expert’s behavior, while the agent learns a policy mapping from states to actions by reducing a loss function of the disparity between the expert’s actions and the actions generated by the learned policy.
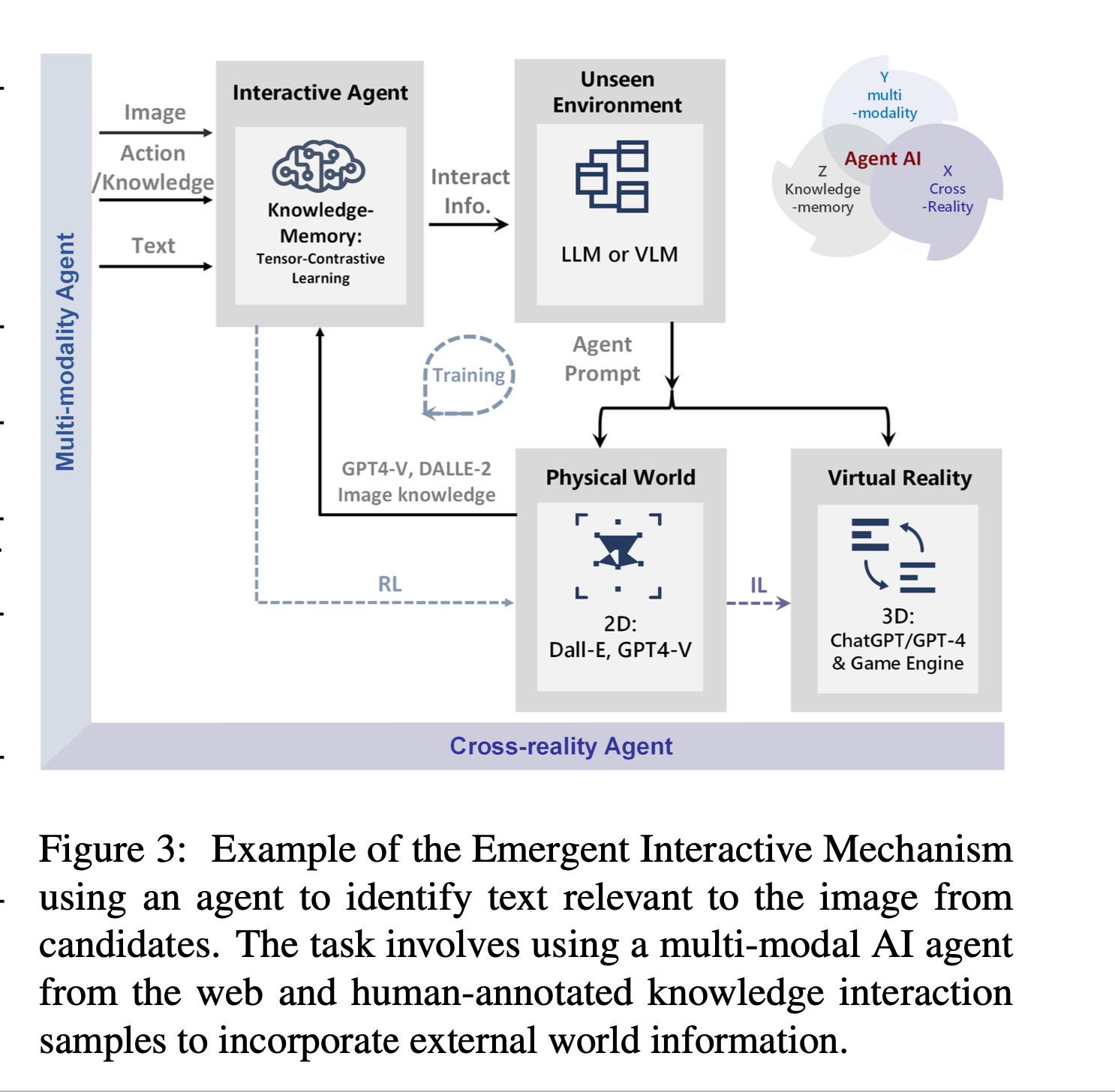
Decoupling → Generalization. Rather than relying on a task-specific reward function, the agent learns from expert demonstrations, which provide a diverse set of state-action pairs covering various task aspects. The agent then learns a policy that maps states to actions by imitating the expert’s behavior. Decoupling in imitation learning refers to separating the learning process from the task-specific reward function, allowing the policy to generalize across different tasks without explicit reliance on the task-specific reward function. By decoupling, the agent can learn from expert demonstrations and learn a policy that is adaptable to a variety of situations. Decoupling enables transfer learning, where a policy learned in one domain can adapt to others with minimal fine-tuning. By learning a general policy that is not tied to a specific reward function, the agent can leverage the knowledge it acquired in one task to perform well in other related tasks. Since the agent does not rely on a specific reward function, it can adapt to changes in the reward function or environment without the need for significant retraining. This makes the learned policy more robust and generalizable across different environments. Decoupling in this context refers to the separation of two tasks in the learning process: learning the reward function and learning the optimal policy.
Generalization → Emergent Behavior. Generaliza- tion explains how emergent properties or behaviors can arise from simpler components or rules. The key idea lies in identifying the basic elements or rules that govern the behavior of the system, such as individual neurons or basic algorithms. Consequently, by observ- ing how these simple components or rules interact with one another. These interactions of these components of- ten lead to the emergence of complex behaviors, which are not predictable by examining individual compo- nents alone. Generalization across different levels of complexity allows a system to learn general princi- ples applicable across these levels, leading to emergent properties. This enables the system to adapt to new situations, demonstrating the emergence of more com- plex behaviors from simpler rules. Furthermore, the ability to generalize across different complexity levels facilitates knowledge transfer from one domain to an- other, which contributes to the emergence of complex behaviors in new contexts as the system adapts.
2.2.4 可解释性与可解释性
模仿学习 → 去耦合
通常通过强化学习(RL)或模仿学习(IL)在连续反馈循环中进行训练,从随机初始化的策略开始。然而,这种方法在获取陌生环境中的初始奖励时面临挑战,特别是当奖励稀疏或仅在长时间交互结束时可用时。 ,更优的解决方案是使用通过模仿学习训练的无限记忆代理,它可以从专家数据中学习策略,改善对未知环境空间的探索和利用,如图3所示。
传统学代理模仿专家演示者的行为来学习策略。然而,直接学习专家策略可能并非最佳方法,因为代理可能无法很好地泛化到未见过的情况。为了解决这个问题,我们提出了通过上下文提示或隐式奖励函数来学习代理,这些方法捕捉了专家行为的关键方面,如图3所示。
这使得无限理了从专家演示中学习的物理世界行为数据,用于任务执行。它有助于克服现有模仿学习的缺点,如对大量专家数据的需求和在复杂任务中的潜在错误。代理AI的关键思想包括:1)无限代理收集物理世界专家演示作为状态-动作对;2)虚拟环境模仿代理生成器。模仿代理生成模仿专家行为的动作,而代理通过减少专家动作与学习策略生成的动作之间差异的损失函数,学习从状态到动作的策略映射。
**去耦合 → 泛化 *
代理通过模仿专家演示来学而不是依赖于特定任务的奖励函数,专家演示提供了涵盖各种任务方面的多样化状态-动作对。代理然后通过模仿专家行为来学习从状态到动作的策略。模仿学习中的去耦合指的是将学习过程与特定任务的奖励函数分离,使策略能够在不同任务之间泛化,而无需明确依赖于特定任务的奖励函数。通过去耦合,代理可以从专家演示中学习,并学习适应各种情况的策略。去耦合使得迁移学习成为可能,即在一个领域中学习的策略可以通过最小的微调适应其他领域。通过学习不依赖于特定奖励函数的通用策略,代理可以利用在一个任务中获得的知识,在其他相关任务中表现良好。由于代理不依赖于特定的奖励函数,它可以在奖励函数或环境发生变化时适应,而无需进行大量的重新训练。这使得学习的策略在不同环境中更具鲁棒性和泛化能力。
**泛化 → 涌现行为 泛化解释了如何从更简单的组件或中涌现出复杂的特性或行为。关键在于识别支配系统行为的基本元素或规则,如单个神经元或基本算法。通过观察这些简单组件或规则如何相互作用,这些相互作用通常导致复杂行为的涌现,而这些行为无法仅通过检查单个组件来预测。不同复杂性层次之间的泛化使系统能够学习适用于这些层次的通用原则,从而导致涌现特性。这使得系统能够适应新情况,展示从更简单规则中涌现出更复杂行为的能力。此外,跨不同复杂性层次的泛化能力促进了知识从一个领域到另一个领域的转移,这有助于系统在适应新环境时涌现出复杂行为。
2.2.5 Inference Augmentation(推理增强)
The inference ability of an AI agent lies in its capacity to interpret, predict, and respond based on its training and input data. While these capabilities are advanced and continually improving, it’s important to recognize their limitations and the influence of the underlying data they are trained on. Particularly, in the context of large language models, it refers to its capacity to draw conclusions, make predictions, and generate responses based on the data it has been trained on and the input it receives. Inference augmentation in AI agents refers to enhancing the AI’s natural inference abilities with additional tools, techniques, or data to improve its performance, accuracy, and utility. This can be particularly important in complex decision-making scenarios or when dealing with nuanced or specialized content. We denote particularly important sources for inference augmentation below:
Data Enrichment. Incorporating additional, often external, data sources to provide more context or background can help the AI agent make more informed inferences, especially in areas where its training data may be limited. For example, AI agents can infer meaning from the context of a conversation or text. They analyze the given information and use it to understand the intent and relevant details of user queries. These models are proficient at recognizing patterns in data. They use this ability to make inferences about language, user behavior, or other relevant phenomena based on the patterns they’ve learned during training.
Algorithm Enhancement. Improving the AI’s underlying algorithms to make better inferences. This could involve using more advanced machine learning models, integrating different types of AI (like combining NLP with image recognition), or updating algorithms to better handle complex tasks. Inference in language models involves understand- ing and generating human language. This includes grasping nuances like tone, intent, and the subtleties of different linguistic constructions.
Human-in-the-Loop (HITL). Involving human input to augment the AI’s inferences can be particularly useful in areas where human judgment is crucial, such as ethical considerations, creative tasks, or ambiguous scenarios. Humans can provide guidance, correct errors, or offer insights that the agent would not be able to infer on its own.
Real-Time Feedback Integration. Using real-time feedback from users or the environment to enhance inferences is another promising method for improving performance during inference. For example, an AI might adjust its recommendations based on live user responses or changing conditions in a dynamic system. Or, if the agent is taking actions in a simulated environment that break certain rules, the agent can be dynamically given feedback to help correct itself.
Cross-Domain Knowledge Transfer. Leveraging knowledge or models from one domain to improve inferences in another can be particularly helpful when producing outputs within a specialized discipline. For instance, techniques developed for language translation might be applied to code generation, or insights from medical diagnostics could enhance predictive maintenance in machinery.
Customization for Specific Use Cases. Tailoring the AI’s inference capabilities for particular applications or industries can involve training the AI on specialized datasets or fine-tuning its mod
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2318
2318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









