







 本文介绍了一种尺度感知Fast R-CNN(SAF R-CNN)的行人检测方法,包括模型概述、行人提案提取、SAF R-CNN架构、尺度感知加权和优化策略。
本文介绍了一种尺度感知Fast R-CNN(SAF R-CNN)的行人检测方法,包括模型概述、行人提案提取、SAF R-CNN架构、尺度感知加权和优化策略。
1.Introduction
行人检测旨在预测图像中所有行人实例的bounding box。近年来,它已经引起了计算机视觉界的广泛关注[5],[38],[40],[7],[46],[6],[45],[10],[21],作为许多以人为中心的应用的重要组成部分,如无人驾驶汽车,人员重新识别,视频监控和机器人技术[20],[39]。
最近,很多研究工作[35],[46],[24],[32]用于行人检测。然而,他们通常会留下一个未解决的关键问题,由图像中不同尺度的行人引起的问题,在自然场景中这显示出相当大的影响行人检测的性能。我们在图1中提供本文动机的图示。
最近,很多研究工作[35],[46],[24],[32]用于行人检测。然而,他们通常会留下一个未解决的关键问题,由图像中不同尺度的行人引起的问题,在自然场景中这显示出相当大的影响行人检测的性能。我们在图1中提供本文动机的图示。
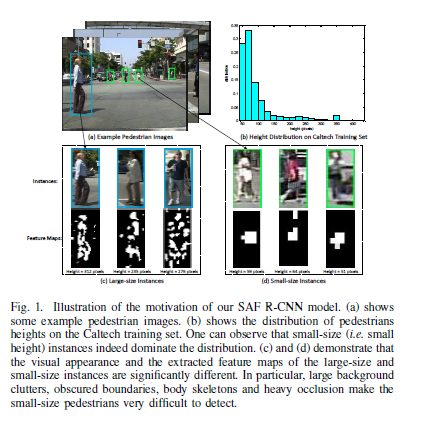
视频监控图像中的行人实例(例如,Caltech数据集[8])通常具有非常小的尺寸。从统计学角度来说,超过60%的Caltech训练集的实例的高度小于100像素。由于以下困难,准确地对这些小尺寸的行人实例进行定位是非常具有挑战性的。首先,大多数小尺寸实例出现带有边框模糊,外观模糊。将它们与杂乱的背景和其他重叠实例区分开很难。其次,大尺寸的行人实例通常表现出与小尺寸实例显着不同的视觉特征。例如,大尺寸实例的身体骨骼可以为行人检测提供丰富的信息,而小尺寸实例的骨骼无法如此容易地识别。这些差异也可以通过比较生成的大尺寸和小尺寸行人特征图来验证,如图1所示。对于大尺寸实例显示了详细身体骨骼的高特征响应,而仅获的小尺寸实例的粗糙特征图。
现有的工作主要从两个方面解决尺度差异问题。首先,使用强力的数据增强(例如,多尺度[12]或调整大小[13])来提高尺度不变能力。其次,在具有多尺度滤波器的单个模型[14] [42]中,使用各种尺寸的所有实例。然而,由于大尺寸和小尺寸实例的类内差异,很难处理它们与单个模型的特征响应的显着不同。为了利用各种尺度的实例的显着不同的特征,我们采用分治理念来解决这个关键的尺度变化问题。基于这一理念,统一的框架可以包括多个单一模型,每个模型专门通过捕获尺度特定的视觉模式来检测特定范围尺度的实例。

受上述想法的驱动,我们开发了一种基于fast R-CNN流程的新型Scale-Aware Fast R-CNN(SAF R-CNN)框架[12]。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









