






 AdetailedexplanationofGANs,theircomponents,lossfunctions,andasimplePyTorchimplementationusingMNISTdataset.
AdetailedexplanationofGANs,theircomponents,lossfunctions,andasimplePyTorchimplementationusingMNISTdataset.
GAN网络的简单实现
GAN原文:https://proceedings.neurips.cc/paper_files/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf
一、GAN的原理简单说明
生成对抗网络 (GAN) 是一种深度学习模型,由两个主要部分组成:生成器(Generator)和判别器(Discriminator)。它们通过对抗的方式一起训练,使生成器能够生成逼真的数据,而判别器则学会区分真实数据和生成器生成的数据。
GAN的核心思想是通过两个网络之间的博弈来提高生成器的性能,达到生成更真实数据的目的。生成器尝试欺骗判别器,而判别器则努力辨别真实数据和生成数据之间的差异。
1. 生成器(Generator)
生成器的损失函数通常使用生成数据被判别器误认为真实数据的概率来定义。损失函数记为 (J_G):
\[ J_G = -\frac{1}{m} \sum_{i=1}^{m} \log(D(G(z^{(i)}))) \]
其中:
- (m) 是批次大小
- (z^{(i)}) 是从潜在空间中抽样的噪声向量
- (G(z^{(i)})) 是生成器生成的样本
- (D) 是判别器
2. 判别器(Discriminator)
判别器的损失函数包括对真实数据和生成数据的分类损失,记为 (J_D):
\[ J_D = -\frac{1}{2m} \sum_{i=1}^{m} \left[ \log(D(x^{(i)})) + \log(1 - D(G(z^{(i)}))) \right] \]
其中:
- (x^{(i)}) 是真实数据样本
- (D(x^{(i)})) 是判别器对真实数据的概率输出
- (G(z^{(i)})) 是生成器生成的样本
- (D(G(z^{(i)}))) 是判别器对生成数据的概率输出
通过交替地训练生成器和判别器,GAN的目标是找到一个平衡点,使得生成器能够生成逼真的数据,判别器无法轻松区分真实数据和生成数据。
二、代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
from torch.utils import data
#对数据做标准化(-1,1),在gan中,训练技巧,因为生成器最后通过tanh激活
transform = transforms.Compose([
transforms.ToTensor(),#0-1; channel,h,w; 转为tensor
transforms.Normalize(0.5,0.5)#从(0,1)==》(-1,1)
])
#不需要数据集的标签,测试集
train_ds = torchvision.datasets.MNIST("data_mnist",
train=True,
transform=transform,
download=True)
dataloader = torch.utils.data.DataLoader(train_ds,batch_size=128,shuffle=True)
#region可视化数据集,需要将dataloader的batch_size改为对应的16
# x,y = next(iter(dataloader))#x是图片,y是对应标签
# x = x.reshape(16,28,28)
# fig = plt.figure(figsize=(4,4))
# for i in range(16):
# plt.subplot(4,4,i+1)
# plt.imshow(x[i])#将输出由-1~1拉回0~1
# plt.axis('off')
# plt.show()
#endregion
#生成器输入为长度为100的随机噪声,生成于mnist一样大小的图片28*28(1,28,28)
class Generator(nn.Module):
def __init__(self):
super(Generator,self).__init__()
self.main = nn.Sequential(
nn.Linear(100,256),nn.ReLU(),
nn.Linear(256,512),nn.ReLU(),
nn.Linear(512,28*28),nn.Tanh()
)
def forward(self,x): #x是输入的随机噪声
img = self.main(x)
img = img.view(-1,28,28)#待定
return img
#判别器输入为(1,28,28)图片,输出的是二分类的概率,通过sigmod激活,中间层激活是leakyrelu
#BCEloss计算交叉熵损失
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator,self).__init__()
self.main = nn.Sequential(
nn.Linear(28*28,256),nn.LeakyReLU(),#nn.Dropout(p=0.6),
nn.Linear(256,512),nn.LeakyReLU(),#nn.Dropout(p=0.6),
nn.Linear(512,1),nn.Sigmoid(),
)
def forward(self,x):
x = x.view(-1,28*28)#x是图片
result = self.main(x)
return result
#初始化模型,优化器,损失函数
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
generator = Generator().to(device)
discriminator = Discriminator().to(device)
d_optim = torch.optim.Adam(discriminator.parameters(),lr=0.0001)
g_optim = torch.optim.Adam(generator.parameters(),lr=0.0001)#一开始的问题在generator写错成discriminator
loss_fun = torch.nn.BCELoss()#计算二元交叉熵
#绘图函数
def gen_img_plot(model,test_input):
prediction = np.squeeze(model(test_input).detach().cpu().numpy())
fig = plt.figure(figsize=(4,4))
for i in range(16):
plt.subplot(4,4,i+1)
plt.imshow((prediction[i] + 1)/2)#将输出由-1~1拉回0~1
plt.axis('off')
plt.show()
#随机输入的噪声
test_input = torch.randn(16,100,device=device)
#gan的训练
D_loss = []
G_loss = []
train_num = 100
#训练循环
for epoch in range(train_num):#训练多少轮
d_epoch_loss = 0
g_epoch_loss = 0
count = len(dataloader)
for step, (img,_) in enumerate(dataloader):
img = img.to(device)
size = img.size(0)
random_noise = torch.randn(size,100,device=device)
#对判别器的优化
d_optim.zero_grad()
real_output = discriminator(img) #判别器输入真实图片,输出的是判别器对真实图片的预测结果
d_real_loss = loss_fun(real_output,torch.ones_like(real_output))#对真实图片的真实输出与预期输出1的loss
d_real_loss.backward()
gen_img = generator(random_noise)
fake_output = discriminator(gen_img.detach())#注意:优化对象是判别器不是生成器,所以要截断梯度#判别器输入生成图片,得到对生成图片的预测结果
d_fake_loss = loss_fun(fake_output,torch.zeros_like(fake_output))#得到判别器对生成图片的loss
d_fake_loss.backward()
d_loss = d_real_loss + d_fake_loss
d_optim.step()#更新优化
#对生成器的优化
g_optim.zero_grad()
fake_output = discriminator(gen_img)
g_loss = loss_fun(fake_output,torch.ones_like(fake_output))#得到生成器的loss
g_loss.backward()
g_optim.step()
with torch.no_grad():
d_epoch_loss += d_loss
g_epoch_loss += g_loss
with torch.no_grad():
d_epoch_loss /= count
g_epoch_loss /= count
D_loss.append(d_epoch_loss)
G_loss.append(g_epoch_loss)
print('Epoch:',epoch)
print("D_loss:\t",D_loss[epoch],"\nG_loss:\t",G_loss[epoch])
gen_img_plot(generator,test_input)#显示最后的结果就可
环境依赖说明
pytorch、matplotlib以及numpy即可,pytorch可以去官网找到合适自己电脑或者服务器的版本安装即可,网上教程也很多(pytorch官网),matplotlib、numpy直接使用以下命令即可,会自动安装最新版本。
pip insttall matplotlib numpy
三、简单说明
- 这里的数据集是mnist,也就是说生成的是手写数字
- GAN包括生成器和判别器两部分,GAN的主要优势是:如果只用生成模型,那么很难表征生成的效果怎么样,这里引入判别器,将对生成器生成效果的表征用判别器来进行二分类来表征生成效果如何。
- loss主要包括两部分,一部分是判别器损失,一部分是生成器损失。判别器的损失包括了判别真图像的损失,判别假图像的损失,真图像被判定为假的,假图像被判定为真的,这两者之和就是判别器的损失。生成器的损失也是利用判别器来表征,生成的图像被判定为假就是生成器的损失。
- 生成器,判别器的架构:这里只是使用简单的神经网络来搭建,其实如果对于更加复杂的数据集,也就是要生成较为复杂的图像,可以使用CNN来搭建生成器和判别器。
- GAN网络较难训练
四、结果展示
这是训练20个epoch的效果
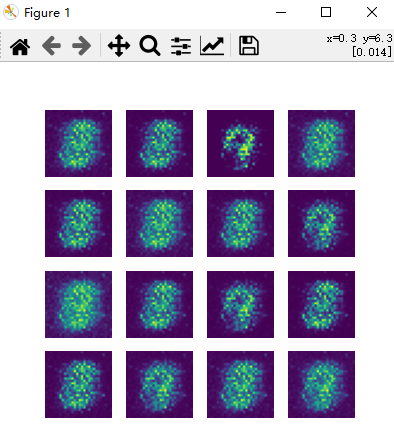
这是重新训练了100个epoch的效果

可以看出,生成的结果会是单个或者某几个数字,这是模型崩溃的结果,为了骗过判别器,生成器只生成某少数几种数字来降低损失。















 183
183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









