




香橙派5集成Rockchip公司的rk3588s芯片,其中含有一颗3核的自研rknn npu,可使用c/c++ api对其进行模型加载及推理运算,也可以通过rknn-toolkit使用python对其进行,本文使用rknn-toolkit+python。
一、环境介绍
PC:Vmware虚拟机安装ubuntu-22.04.2-desktop-amd64.iso
香橙派5:Orangepi5_1.1.10_ubuntu_jammy_desktop_xfce_linux5.10.160.img
二、安装Conda
PC和香橙派5都要安装
PC端ubuntu conda安装包:https://download.csdn.net/download/xiaolangyangyang/90392592
香橙派5端conda安装包:https://download.csdn.net/download/xiaolangyangyang/90392595
1. 安装:
bash Miniconda3-py310_23.11.0-2-Linux-x86_64.sh //pc ubuntu
bash Miniconda3-py310_23.11.0-2-Linux-aarch64.sh //orangepi5
2. 添加环境变量(~/.bashrc),添加后重启终端:
export PATH="/home/username/miniconda3/bin:$PATH" //pc ubuntu
export PATH="/home/orangepi/miniconda3/bin:$PATH" //orangepi5
3. 激活conda
bash
source ~/miniconda3/bin/activate
4. 添加清华源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
5. 更新conda:
conda update -n base -c defaults conda
6. 创建虚拟环境:
conda create -n rknn python=3.10
7. 激活虚拟环境:
conda activate rknn
8. 安装依赖包:
conda install numpy pandas matplotlib
9. 管理虚拟环境:
conda env list
conda deactivate
conda remove -n rknn --all三、在windows上生成yolov5.onnx
windows下环境搭建参考:在4060TI GPU上使用Yolov5
yolov5源码下载路径:https://download.csdn.net/download/xiaolangyangyang/90373399
修改以下部分:
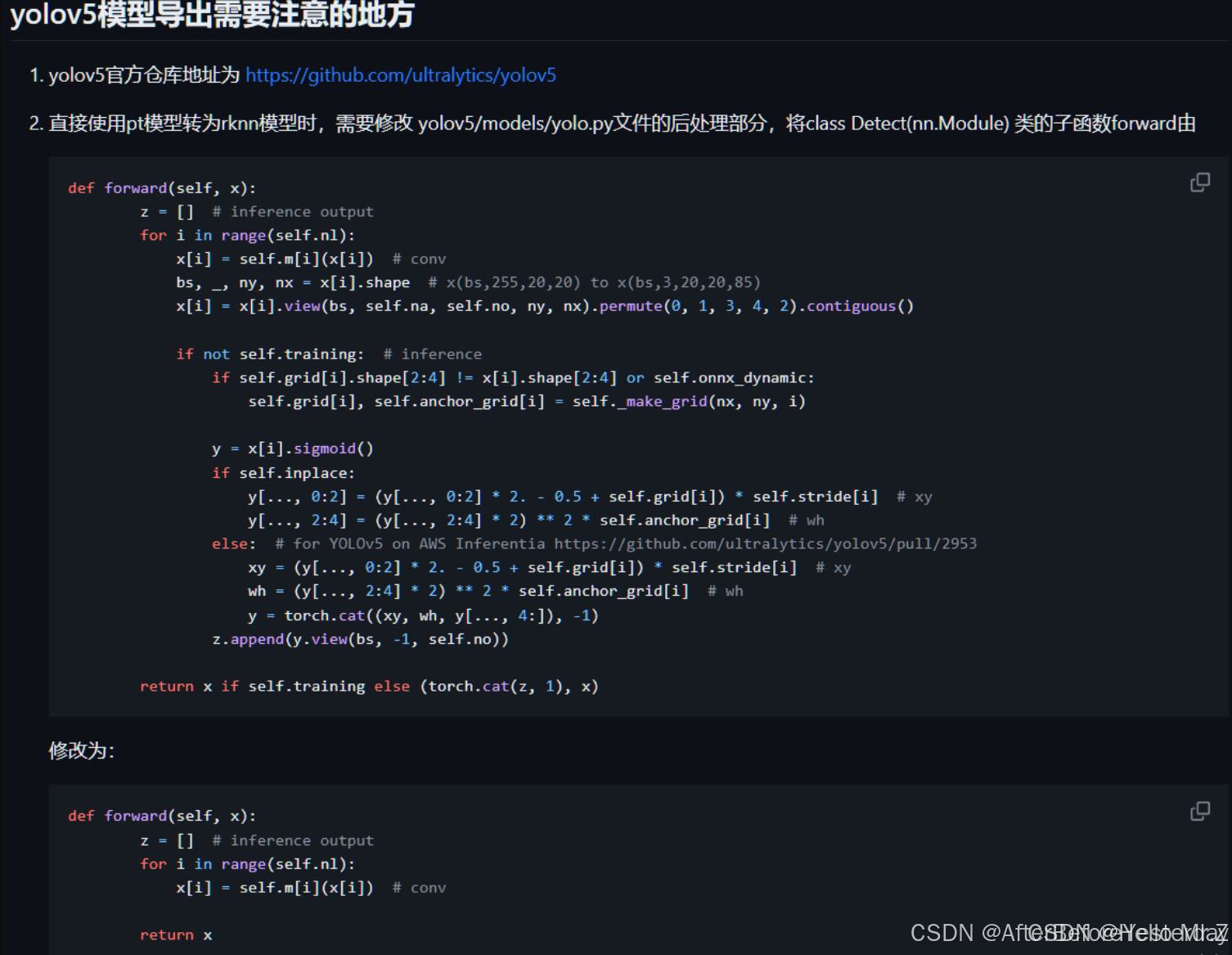
改为:
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
return x屏蔽yolov5/requirements.txt文件里的以下3行:
#torch>=1.8.0
#torchvision>=0.9.0
#ultralytics>=8.0.232然后执行:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple // 安装依赖
pip install onnx==1.15.0 -i https://pypi.tuna.tsinghua.edu.cn/simple // 安装依赖
pip install protobuf==5.27.3 -i https://pypi.tuna.tsinghua.edu.cn/simple // 安装依赖
pip install onnxconverter-common==1.13.0 -i https://pypi.tuna.tsinghua.edu.cn/simple // 安装依赖
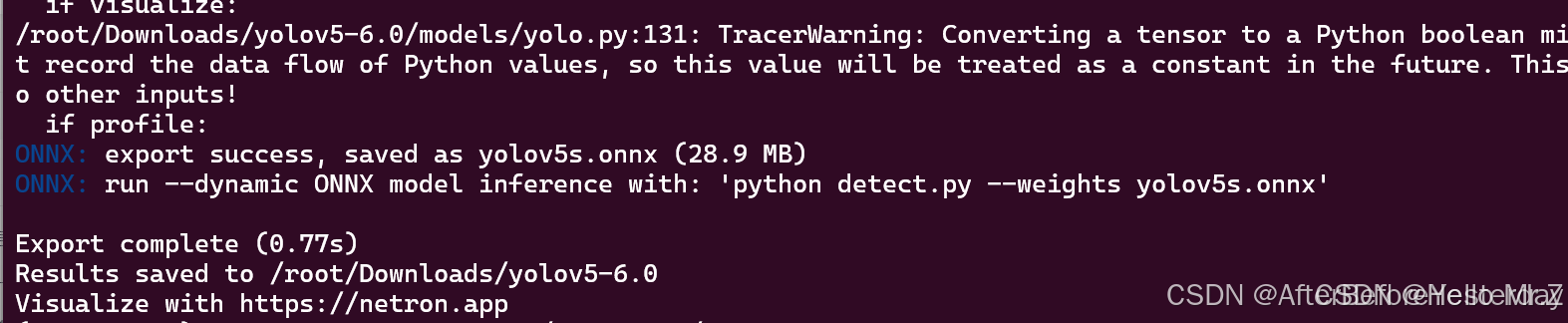
python export.py --weights yolov5n.pt --data data/coco128.yaml --include onnx --opset 12 --batch-size 1 // --opset一定要为12,不然后面onnx转rknn会报错weights自己选你训练完成的best.pt,data选你自己设置的,这里会生成一个yolov5.onnx文件
四、在PC端ubuntu将yolov5.onnx转换为yolov5.rknn
下载rknn-toolkit2-1.5.2:https://download.csdn.net/download/xiaolangyangyang/90392596
将rknn-toolkit2-1.5.2.zip复制到PC上的ubuntu并解压,安装依赖包:
pip install -r rknn-toolkit2-1.5.2/doc/requirements_cp310-1.5.2.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install rknn-toolkit2-1.5.2/packages/rknn_toolkit2-1.5.2+b642f30c-cp310-cp310-linux_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple安装过程中遇到如下问题,则换个源安装,以下提供两个安装源,再安装一下yolov5的依赖:

pip install -i https://pypi.doubanio.com/simple/ tf-estimator-nightly==2.8.0.dev2021122109
pip install -i https://mirrors.aliyun.com/pypi/simple/ tf-estimator-nightly==2.8.0.dev2021122109安装成功后输入命令检查是否安装成功,如果像下图一样没有报错则说明安装成功:
python
>>> from rknn.api import RKNN
将第三章生成yolov5.onnx文件复制到rknn-toolkit2-1.5.2/examples/onnx/yolov5目录,修改该目录里下的test.py文件,如下所示:
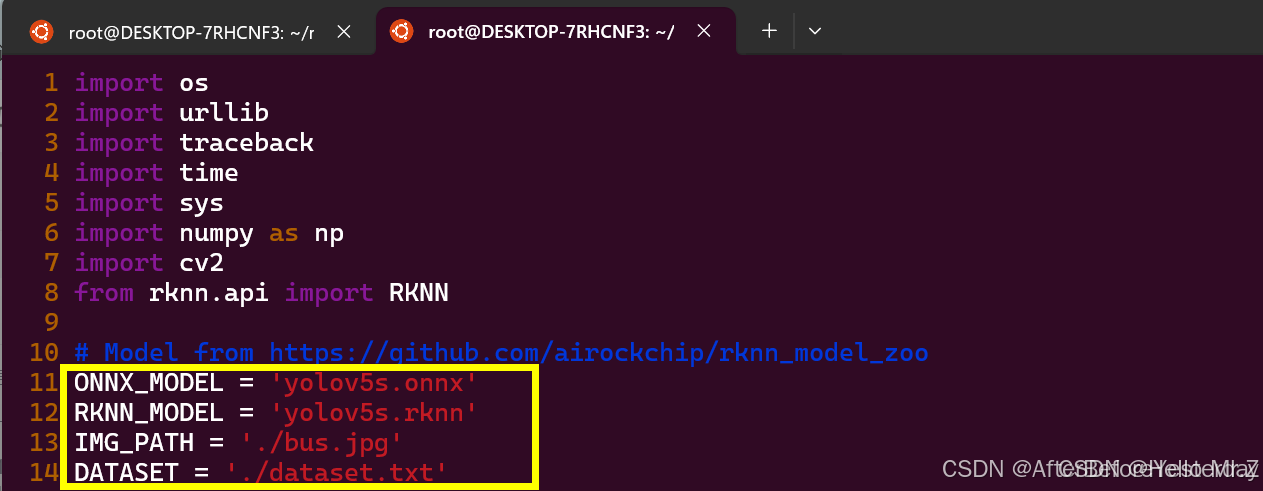

运行test.py脚本,如下图所示生成yolov5.rknn:
python test.py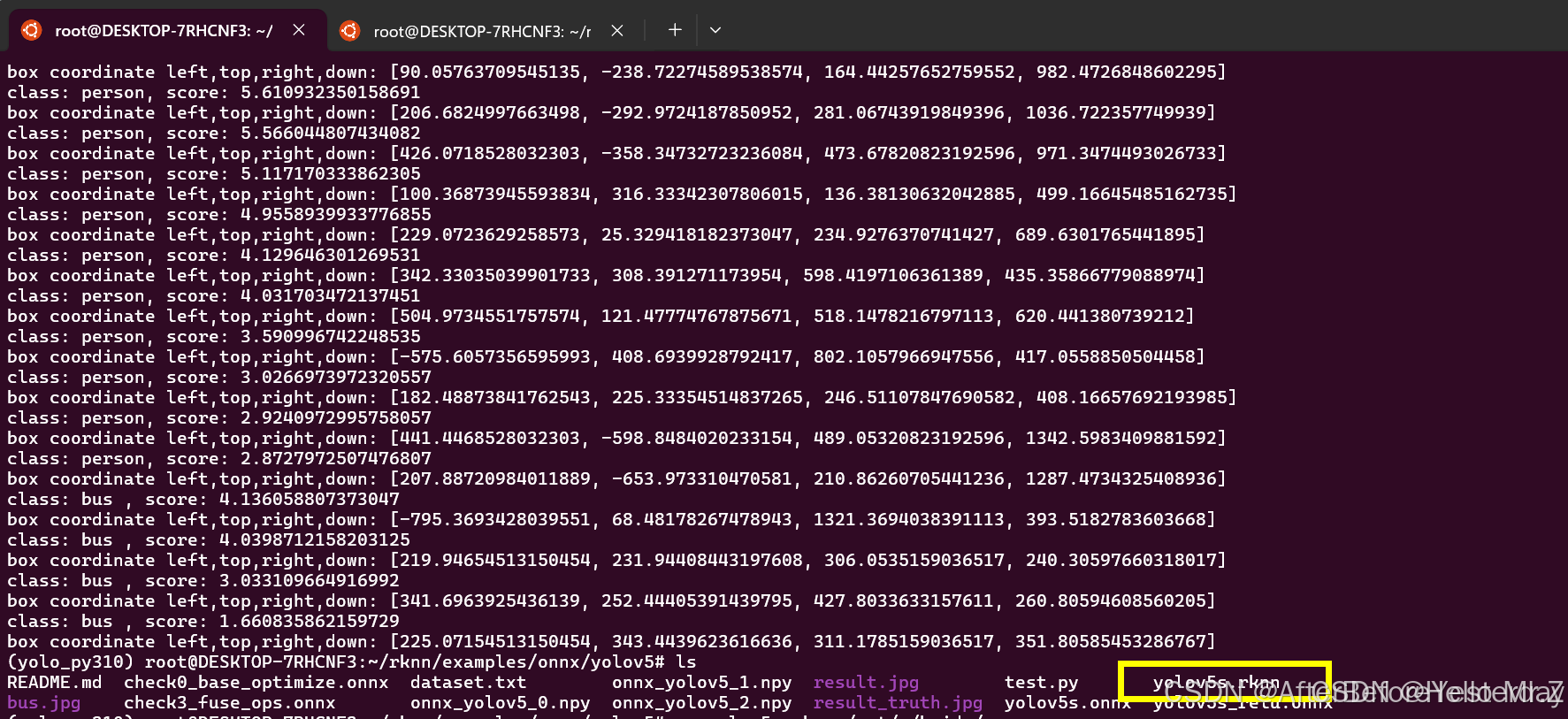
创建deploy.py脚本如下:
#deploy.py
import numpy as np
import cv2
from rknnlite.api import RKNNLite
RKNN_MODEL = 'yolov5.rknn'
IMG_PATH = 'bus.jpg'
QUANTIZE_ON = True
OBJ_THRESH = 0.25
NMS_THRESH = 0.45
IMG_SIZE = 640
CLASSES = ("people")
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def xywh2xyxy(x):
# Convert [x, y, w, h] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def process(input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = sigmoid(input[..., 4])
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = sigmoid(input[..., 5:])
box_xy = sigmoid(input[..., :2])*2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(IMG_SIZE/grid_h)
box_wh = pow(sigmoid(input[..., 2:4])*2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with box threshold. It's a bit different with origin yolov5 post process!
# Arguments
boxes: ndarray, boxes of objects.
box_confidences: ndarray, confidences of objects.
box_class_probs: ndarray, class_probs of objects.
# Returns
boxes: ndarray, filtered boxes.
classes: ndarray, classes for boxes.
scores: ndarray, scores for boxes.
"""
boxes = boxes.reshape(-1, 4)
box_confidences = box_confidences.reshape(-1)
box_class_probs = box_class_probs.reshape(-1, box_class_probs.shape[-1])
_box_pos = np.where(box_confidences >= OBJ_THRESH)
boxes = boxes[_box_pos]
box_confidences = box_confidences[_box_pos]
box_class_probs = box_class_probs[_box_pos]
class_max_score = np.max(box_class_probs, axis=-1)
classes = np.argmax(box_class_probs, axis=-1)
_class_pos = np.where(class_max_score >= OBJ_THRESH)
boxes = boxes[_class_pos]
classes = classes[_class_pos]
scores = (class_max_score* box_confidences)[_class_pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Arguments
boxes: ndarray, boxes of objects.
scores: ndarray, scores of objects.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def yolov5_post_process(input_data):
masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
[59, 119], [116, 90], [156, 198], [373, 326]]
boxes, classes, scores = [], [], []
for input, mask in zip(input_data, masks):
b, c, s = process(input, mask, anchors)
b, c, s = filter_boxes(b, c, s)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes)
boxes = xywh2xyxy(boxes)
classes = np.concatenate(classes)
scores = np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
def draw(image, boxes, scores, classes):
"""Draw the boxes on the image.
# Argument:
image: original image.
boxes: ndarray, boxes of objects.
classes: ndarray, classes of objects.
scores: ndarray, scores of objects.
all_classes: all classes name.
"""
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
top = int(top)
left = int(left)
right = int(right)
bottom = int(bottom)
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 2)
cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(top, left - 6),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
if __name__ == '__main__':
# Create RKNN object
rknn = RKNNLite()
# load RKNN model
print('--> Load RKNN model')
ret = rknn.load_rknn(RKNN_MODEL)
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime(core_mask=RKNNLite.NPU_CORE_0_1_2) #使用0 1 2三个NPU核心
# ret = rknn.init_runtime('rk3566')
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Set inputs
img = cv2.imread(IMG_PATH)
# img, ratio, (dw, dh) = letterbox(img, new_shape=(IMG_SIZE, IMG_SIZE))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (IMG_SIZE, IMG_SIZE))
# Inference
outputs = rknn.inference(inputs=[img])
# post process
input0_data = outputs[0]
input1_data = outputs[1]
input2_data = outputs[2]
input0_data = input0_data.reshape([3, -1]+list(input0_data.shape[-2:]))
input1_data = input1_data.reshape([3, -1]+list(input1_data.shape[-2:]))
input2_data = input2_data.reshape([3, -1]+list(input2_data.shape[-2:]))
input_data = list()
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, classes, scores = yolov5_post_process(input_data)
img_1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
if boxes is not None:
draw(img_1, boxes, scores, classes)
# show output
cv2.imshow("post process result", img_1)
cv2.waitKey(0)
cv2.destroyAllWindows()
rknn.release()
创建rknn_yolov5_test目录,将如下文件拷贝到该目录下,将rknn_yolov5_test导出并拷贝到香橙派5下的任意路径下:
五、在香橙派5上部署(在香橙派5上操作)
1、升级香橙派5上的rknn驱动
rknn驱动下载路径:https://download.csdn.net/download/xiaolangyangyang/90392602
下载驱动后解压并拷贝驱动文件到香橙派5,然后重启香橙派5:
sudo cp rknpu2-master/runtime/RK3588/Linux/rknn_server/aarch64/usr/bin/rknn_server /usr/bin/rknn_server
sudo cp rknpu2-master/runtime/RK3588/Linux/librknn_api/aarch64/librknnrt.so /usr/lib/librknnrt.so
sudo cp rknpu2-master/runtime/RK3588/Linux/librknn_api/aarch64/librknn_api.so /usr/lib/librknn_api.so2、安装rknn-toolkit2-1.5.2依赖
将第四章下载的rknn-toolkit2-1.5.2复制到香橙派5并解压,然后执行如下命令:
pip install -r rknn-toolkit2-1.5.2/doc/requirements_cp310-1.5.2.txt -i https://pypi.tuna.tsinghua.edu.cn/simple // 安装依赖,此处有报错可以不予理会
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple // 安装依赖
pip install rknn-toolkit2-1.5.2/rknn_toolkit_lite2/packages/rknn_toolkit_lite2-1.5.2-cp310-cp310-linux_aarch64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple // 安装rknn-toolkit2-1.5.23、运行第三章拷贝的rknn_yolov5_test目录下的deploy.py,执行结果如下图说明部署成功
python deploy.py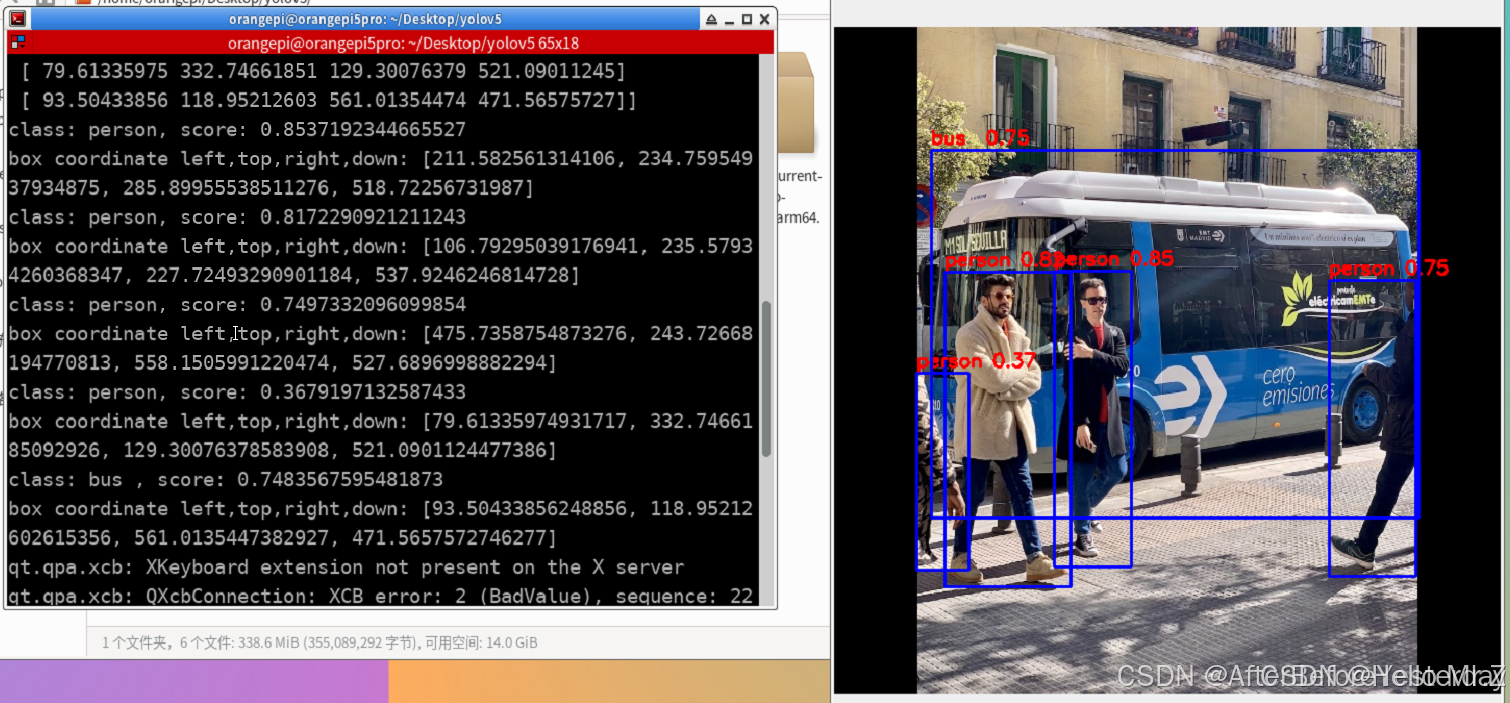
R329 NPU API接口
// Linux driver user interface - Standard API
aipu_status_t aipu_init_context(aipu_ctx_handle_t** ctx);
aipu_status_t aipu_get_error_message (const aipu_ctx_handle_t* ctx, aipu_status_t status, const char** msg);
aipu_status_t aipu_deinit_context(const aipu_ctx_handle_t* ctx);
aipu_status_t aipu_config_global(const aipu_ctx_handle_t* ctx, uint64_t types, void* config)
aipu_status_t aipu_load_graph(const aipu_ctx_handle_t* ctx, const char* graph, uint64_t* id)
aipu_status_t aipu_load_graph_helper(const aipu_ctx_handle_t* ctx, const char* graph_buf, uint32_t graph_size, uint64_t* id)
aipu_status_t AIPU_unload_graph(const aipu_ctx_handle_t* ctx, uint64_t id);
aipu_status_t aipu_create_job(const aipu_ctx_handle_t* ctx, uint64_t graph, uint64_t* job, aipu_create_job_cfg_t *config = nullptr)
aipu_status_t aipu_finish_job(const aipu_ctx_handle_t* ctx, uint64_t job_id, int32_t time_out)
aipu_status_t aipu_flush_job(const aipu_ctx_handle_t* ctx, uint64_t job_id)
aipu_status_t aipu_get_job_status(const aipu_ctx_handle_t* ctx, uint64_t job_id, aipu_job_status_t* status)
aipu_status_t aipu_clean_job(const aipu_ctx_handle_t* ctx, uint64_t id)
aipu_status_t aipu_get_tensor_count(const aipu_ctx_handle_t* ctx, uint64_t id, aipu_tensor_type_t type, uint32_t* cnt)
aipu_status_t aipu_get_tensor_descriptor(const aipu_ctx_handle_t* ctx, uint64_t id, aipu_tensor_type_t
type, uint32_t tensor, aipu_tensor_desc_t* desc)
aipu_status_t aipu_load_tensor(const aipu_ctx_handle_t* ctx, uint64_t id, uint32_t tensor, const void* data)
aipu_status_t aipu_get_tensor(const aipu_ctx_handle_t* ctx, uint64_t job, aipu_tensor_type_t type, uint32_t tensor, void* buf);
aipu_status_t aipu_config_job(const aipu_ctx_handle_t* ctx, uint64_t id, uint64_t types, void* config)
aipu_status_t aipu_get_partition_count(const aipu_ctx_handle_t* ctx, uint32_t* cnt)
aipu_status_t aipu_get_cluster_count(const aipu_ctx_handle_t* ctx, uint32_t partition_id, uint32_t* cnt)
aipu_status_t aipu_get_core_count(const aipu_ctx_handle_t* ctx, uint32_t partition_id, uint32_t cluster, uint32_t* cnt)
aipu_status_t aipu_debugger_get_core_info(const aipu_ctx_handle_t* ctx, uint32_t core_id, aipu_core_info_t* info)
aipu_status_t aipu_debugger_get_job_info(const aipu_ctx_handle_t* ctx, uint64_t job, aipu_debugger_job_info_t* info)
aipu_status_t aipu_debugger_bind_job(const aipu_ctx_handle_t* ctx, uint32_t core_id, uint64_t job_id)
aipu_status_t aipu_debugger_run_job(const aipu_ctx_handle_t* ctx, uint32_t job_id);
aipu_status_t aipu_debugger_malloc(const aipu_ctx_handle_t* ctx, uint32_t size, void** va)
aipu_status_t aipu_debugger_free(const aipu_ctx_handle_t* ctx, void* va)
aipu_status_t aipu_printf(char* printf_base, char* redirect_file)
aipu_status_t aipu_get_target(const aipu_ctx_handle_t *ctx, char *target);
aipu_status_t aipu_get_device_status(const aipu_ctx_handle_t* ctx, device_status_t *status);
aipu_status_t aipu_create_batch_queue(const aipu_ctx_handle_t *ctx, uint64_t graph_id, uint32_t *queue_id);
aipu_status_t aipu_clean_batch_queue(const aipu_ctx_handle_t *ctx, uint64_t graph_id, uint32_t queue_id);
aipu_status_t aipu_config_batch_dump(const aipu_ctx_handle_t *ctx, uint64_t graph_id, uint32_t queue_id, uint64_t types, aipu_job_config_dump_t *dump_cfg);
aipu_status_t aipu_add_batch(const aipu_ctx_handle_t *ctx, uint64_t graph_id, uint32_t queue_id, char *inputs[], char *outputs[]);
aipu_status_t aipu_finish_batch(const aipu_ctx_handle_t *ctx, uint64_t graph_id, uint32_t queue_id, aipu_create_job_cfg_t *create_cfg);
aipu_status_t aipu_ioctl(aipu_ctx_handle_t *ctx, uint32_t cmd, void *arg = nullptr);
// Linux driver user interface - Python API
OpenDevice()
LoadGraph(bin_file)
SetX2JobConfig
GetInputTensorNumber()
GetOutputTensorNumber()
LoadInputTensor(index, data)
Run()
GetOutputTensor(index)
UnloadGraph()
// QNX-based driver (for customized solutions only)
aipu_status_t aipu_init_ctx(aipu_ctx_handle_t** ctx);
aipu_status_t aipu_get_error_message(const aipu_ctx_handle_t* ctx, aipu_status_t status, const char** msg);
aipu_status_t aipu_deinit_ctx(const aipu_ctx_handle_t* ctx);
aipu_status_t aipu_config_global(const aipu_ctx_handle_t* ctx, uint64_t types, void* config)
aipu_status_t aipu_load_graph(const aipu_ctx_handle_t* ctx, const char* graph, uint64_t* id)
aipu_status_t aipu_load_graph_helper(const aipu_ctx_handle_t* ctx, const char* graph_buf, uint32_t graph_size, uint64_t* id)
aipu_status_t aipu_load_graph_helper(const aipu_ctx_handle_t* ctx, const char* graph_buf, uint32_t graph_size, uint64_t* id)
aipu_status_t aipu_load_graph_helper(const aipu_ctx_handle_t* ctx, const char* graph_buf, uint32_t graph_size, uint64_t* id)
aipu_status_t aipu_finish_job(const aipu_ctx_handle_t* ctx, uint64_t job_id, int32_t time_out)
aipu_status_t aipu_flush_job(const aipu_ctx_handle_t* ctx, uint64_t job_id, void* priv)
aipu_status_t aipu_get_job_status(const aipu_ctx_handle_t* ctx, uint64_t job_id, aipu_job_status_t* status)
aipu_status_t aipu_clean_job(const aipu_ctx_handle_t* ctx, uint64_t id)
aipu_status_t aipu_get_tensor_count(const aipu_ctx_handle_t* ctx, uint64_t id, aipu_tensor_type_t type, uint32_t* cnt)
aipu_status_t aipu_get_tensor_descriptor(const aipu_ctx_handle_t* ctx, uint64_t id, aipu_tensor_type_t type, uint32_t tensor, aipu_tensor_desc_t* desc)
aipu_status_t aipu_load_tensor(const aipu_ctx_handle_t* ctx, uint64_t id, uint32_t tensor, const void* data)
aipu_status_t aipu_get_tensor(const aipu_ctx_handle_t* ctx, uint64_t job, aipu_tensor_type_t type, uint32_t tensor, void* buf);
aipu_status_t aipu_config_job(const aipu_ctx_handle_t* ctx, uint64_t id, uint64_t types, void* config)
aipu_status_t aipu_get_partition_count(const aipu_ctx_handle_t* ctx, uint32_t* cnt)
aipu_status_t aipu_get_cluster_count(const aipu_ctx_handle_t* ctx, uint32_t partition_id, uint32_t* cnt)
aipu_status_t aipu_get_core_count(const aipu_ctx_handle_t* ctx, uint32_t partition_id, uint32_t cluster, uint32_t* cnt)
aipu_status_t aipu_get_target(const aipu_ctx_handle_t *ctx, char *target)
aipu_status_t aipu_get_device_status(const aipu_ctx_handle_t* ctx, uint32_t *status)
aipu_status_t aipu_printf(char* printf_base, char* redirect_file)
// Bare-metal-based driver
void aipu_config_address(unsigned long ctrl_reg_base_addr, unsigned long memory_addr_offset);
aipu_status_t aipu_init_ctx(void);
aipu_status_t aipu_deinit_ctx(void);
aipu_status_t aipu_load_graph(void *graph, aipu_graph_desc_t *graph_desc);
aipu_status_t aipu_unload_graph(int graph_id);
aipu_status_t aipu_alloc_tensor_buffer(int graph_id, int io_buff_num);
aipu_status_t aipu_get_tensor_desc(int graph_id, int io_buff_handle, aipu_tensor_io_type_t io_type, aipu_tensor_desc_t* tdesc);
aipu_status_t aipu_start(int graph_id , int io_buff_handle);
aipu_status_t aipu_get_status(int graph_id, aipu_task_status_t *status);
aipu_status_t aipu_free_tensor_buffer(int graph_id);
// RTOS-based driver (for customized solutions only)
void aipu_config_address(unsigned long ctrl_reg_base_addr, unsigned long memory_addr_offset);
aipu_status_t aipu_init_ctx(void);
aipu_status_t aipu_deinit_ctx(void);
aipu_status_t aipu_load_graph(void *graph, aipu_graph_desc_t *graph_desc);
aipu_status_t aipu_unload_graph(int graph_id);
aipu_status_t aipu_alloc_tensor_buffer(int graph_id, int io_buff_num);
aipu_status_t aipu_get_tensor_desc(int graph_id, int io_buff_handle, aipu_tensor_io_type_t io_type, aipu_tensor_desc_t* tdesc);
aipu_status_t aipu_start(int graph_id , int io_buff_handle);
aipu_status_t aipu_get_status(int graph_id, aipu_task_status_t *status);
aipu_status_t aipu_free_tensor_buffer(int graph_id);R329 NPU SDK
https://download.csdn.net/download/xiaolangyangyang/90573764
《Zhouyi_Compass_AIPUv3_Assembly_Programming_Guide_61010020_0106_00_en.pdf》
《Zhouyi_Compass_Assembly_Programming_Guide_61010014_0117_00_en.pdf》
《Zhouyi_Compass_C_Programming_Guide_61010015_0117_00_en.pdf》
《Zhouyi_Compass_OpenCL_Programming_Guide_61010021_0106_00_en.pdf》
《Zhouyi_NPU_X2_IIM_70200002_0000_01_en.pdf》
《Zhouyi_NPU_X2_TRM_70200001_0000_01_en.pdf》
【香橙派】使用NPU部署Yolov5的完整解决方案
Ubuntu 22.04 上配置 Conda 虚拟环境
Orangepi 5 Pro(香橙派5pro)部署yolov5
RKNPU2学习
[嵌入式linux]手册上新 |迅为RK3568开发板NPU例程测试
RK3588实战:调用npu加速,yolov5识别图像、ffmpeg发送到rtmp服务器
NPU开发简介
R329芯片及开发板技术
【R329开发板评测】R329开发板部署aipu模型
探游·R329·AI部署实战(二)移植搭建AI环境
【R329开发板评测】开箱及Debian系统上手体验
矽速科技
R329教程一|周易 AIPU 部署及仿真教程
R329开发板教程之三|视觉模型实时运行
R329开发板系列教程之二|实机运行aipu程序
【嵌入式AI】全志 R329 板子跑 mobilenetv2

















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









