







一、基本概念:
- Yolov5:基于PyTorch框架的目标识别算法
- PyTorch:FaceBook推出的深度学习框架
- Torch:PyTorch的Lua版本
- TorchVision:PyTorch的一个扩展库,专注于计算机视觉任务
- CUDA:NVIDIA推出的一种并行计算平台和编程模型
- cuDNN:一个GPU加速库,专门用于深度神经网络,基于CUDA
- Msnhnet:一个轻量级的PyTorch推理框架,专注于Yolo模型,及Unet等其他神经网络结构
二、模型文件格式
- TensorFlow:.pb
- PyTorch:.pt/.pth
- ONNX:.onnx
- Keras:.h5
- Scikit-learn:.pkl
三、软件安装
1、安装Anaconda3
下载路径:https://download.csdn.net/download/xiaolangyangyang/90373396
双击Anaconda3-2021.05-Windows-x86_64.exe一直默认下一步到最后,添加如下环境变量:
C:\ProgramData\anaconda3
C:\ProgramData\anaconda3\Scripts
C:\ProgramData\anaconda3\Library\mingw-w64\bin
C:\ProgramData\anaconda3\Library\bin查看安装路径:

查看python版本是否是安装版本:
![]()
接下来命令行或者Anaconda3得GUI窗口建conda环境,命令行下输入:
conda create -n yolo5_py38 python=3.8 //创建名为yolo5_py38,python版本3.8的虚拟环境2、安装cuda
下载路径:https://zhuanlan.zhihu.com/p/672526561
下载 cuda 12.1 :https://developer.nvidia.com/cuda-12-1-0-download-archive,选择系统下载安装即可,安装好了检查环境变量有没有更新上去(这里一般没问题)
3、安装torch和torchvision
阿里源手动下载地址:pytorch-wheels-cu121安装包下载_开源镜像站-阿里云
下载以下两个文件:
torch-2.3.0+cu121-cp38-cp38-win_amd64.whl
torchvision-0.18.0+cu121-cp38-cp38-win_amd64.whl
4、配置环境
yolov5源码下载路径:https://download.csdn.net/download/xiaolangyangyang/90373399
使用vscode打开,在requirements.txt里删除以下三行内容:
torch>=1.8.0
torchvision>=0.9.0
ultralytics>=8.0.232切到train.py,在vscode里 右下角选择解释器,里面选择我们之前搭建好的conda的python 3.8环境yolo5_py38,选择好之后重新打开vscode,输入python --version 看看是不是输出正确的python版本,接下来在终端窗口输入:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install (下载路径)\torch-2.3.0+cu121-cp38-cp38-win_amd64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install (下载路径)\torchvision-0.18.0+cu121-cp38-cp38-win_amd64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple全部安装好后记得 pip list 查看安装的依赖库,如果显示:
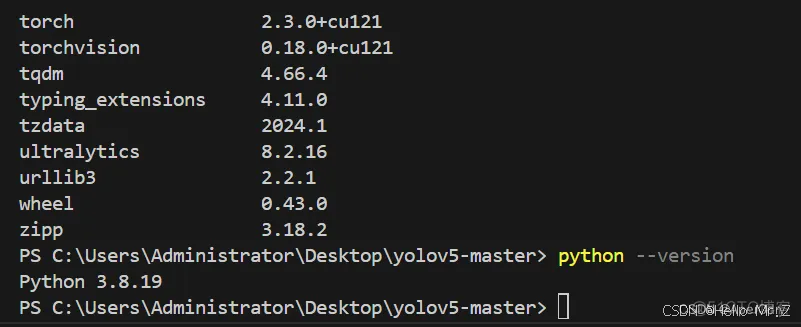
torch和torchvision版本后带CU121即是安装成功。
修改train.py里的内容如下:
parser.add_argument("--device", default="0", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")default="0",表示使用一块gpu(我使用的是13700K+4060ti8g)
5、开始训练
在vscode命令行里输入python train.py开始训练,训练过程出现出现显卡信息说明调用显卡成功:

能够正常完成训练,说明全部的软件安装成功。
四、训练样本集
people样本集part1下载地址:https://download.csdn.net/download/xiaolangyangyang/90373475
people样本集part2下载地址:https://download.csdn.net/download/xiaolangyangyang/90373492
训练过程参考这个链接:yolov5模型训练教程:从数据标注到预处理与训练-CSDN博客
注意安装labelimg时带上清华源:pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
为节省时间训练500张样本图片即可(13700K+4060ti耗时30分钟)
训练命令:
python train.py --epoch 300 --batch 4 --data ./data/myvoc.yaml --cfg ./models/yolov5s.yaml --weight ./weights/yolov5s.pt --workers 0其中涉及到的代码有split.py、xml_to_txt.py、myvoc.yaml:
# split.py
import os
import random
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--xml_path', default='data/dataset', type=str, help='input xml label path')
parser.add_argument('--txt_path', default='data/labels', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.8
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
# xml_to_txt.py
import xml.etree.ElementTree as ET
from tqdm import tqdm
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ['people'] # 这里改为你要训练的标签,否则会报错。比如你要识别“hand”,那这里就改为hand
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
# try:
in_file = open('data/dataset/%s.xml' % (image_id), encoding='utf-8')
out_file = open('data/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bb]) + '\n')
# except Exception as e:
# print(e, image_id)
wd = getcwd()
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/labels/%s.txt' %
(image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in tqdm(image_ids):
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
因为样本集是people,这里内容改为people:
# myvoc.yaml
train: data/train.txt
val: data/val.txt
nc: 1
names: ["people"]训练过程中查看CPU和GPU的消耗,我的13700K几乎占满,4060TI消耗一半
训练结果:
runs\train\xxx\weights\best.pt //最好的训练结果,用于部署
runs\train\xxx\weights\last.pt // 最后一次训练结果,用于继续训练
五、图片部署训练好模型文件
在vscode中打开detect.py,将训练好的best.pt文件复制到项目根目录下,修改以下两个地方:
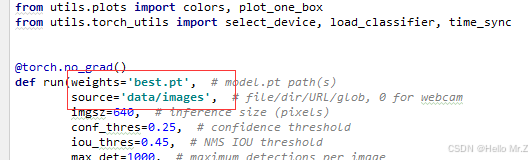
![]()
命令行里运行python detect.py
或者直接使用命令python detect.py --weights best.pt --source ./data/images
单张图片识别命令python detect.py --weights best.pt --source ./data/images/xxx.jpg
识别完成后的图片保存在以下路径:runs\detect\exp
六、视频部署训练好的模型文件
python detect.py --weights best.pt --source ./data/images/xxx.mp4
yolov5 配置环境,训练自己的数据集,实现识别图片,视频,视频流及代码注释
【计算机视觉开发(二)】: 基于yolov5实现调用视频、摄像头进行目标检测
疑问
模型文件由pytorch转换为cuda api已对GPU进行操作
yolov5如何在GPU下训练 yolov5怎么用gpu
Yolov5模型训练
全流程打通!YOLOV5标注&训练&部署:Windows/Linux/Jetson Nano
适合yolov5行人目标检测的数据集18000张,已标注!!!(免费取)
【YOLOv5】 02-标注图片,训练并使用自己的模型
目标检测 | YOLOv5 训练自标注数据集实现深度学习
YOLOv5训练自己的数据集及用训练模型进行测试
YOLOV5训练代码train.py训练参数解析
【Yolov系列】Yolov5学习(一):大致框架
【Yolov系列】Yolov5学习(一)补充2:Focus模块详解
3. 手写数字识别
8. YOLOv5(目标检测)
pytorch如何将模型放到GPU里

















 1974
1974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









