






GenAI Stack
GenAI 栈将帮助你迅速开始构建自己的GenAI应用。演示应用可以作为灵感来源或起点。在技术博客文章[19]中了解更多详情。
配置
从环境模板文件 env.example 创建一个 .env 文件
可用变量:
| 变量名 | 默认值 | 描述 |
|---|---|---|
| OLLAMA_BASE_URL | http://host.docker.internal:11434 | 必需 - Ollama LLM API的URL |
| NEO4J_URI | neo4j://database:7687 | 必需 - Neo4j数据库的URL |
| NEO4J_USERNAME | neo4j | 必需 - Neo4j数据库的用户名 |
| NEO4J_PASSWORD | password | 必需 - Neo4j数据库的密码 |
| LLM | llama2 | 必需 - 可以是任何Ollama模型标签,或者gpt-4 或 gpt-3.5 或 claudev2 |
| EMBEDDING_MODEL | sentence_transformer | 必需 - 可以是sentence_transformer, openai, aws 或 ollama |
| AWS_ACCESS_KEY_ID | 必需 - 仅当LLM=claudev2 或 embedding_model=aws时 | |
| AWS_SECRET_ACCESS_KEY | 必需 - 仅当LLM=claudev2 或 embedding_model=aws时 | |
| AWS_DEFAULT_REGION | 必需 - 仅当LLM=claudev2 或 embedding_model=aws时 | |
| OPENAI_API_KEY | 必需 - 仅当LLM=gpt-4 或 LLM=gpt-3.5 或 embedding_model=openai时 | |
| LANGCHAIN_ENDPOINT | "https://api.smith.langchain.com" | 可选 - Langchain Smith API的URL |
| LANGCHAIN_TRACING_V2 | false | 可选 - 启用Langchain跟踪v2 |
| LANGCHAIN_PROJECT | 可选 - Langchain项目名称 | |
| LANGCHAIN_API_KEY | 可选 - Langchain API密钥 |
LLM配置
MacOS 和 Linux 用户可以使用通过Ollama提供的任何LLM。在https://ollama.ai/library 上你想使用的模型页面的“标签”部分查看,并将环境变量 LLM= 的值写为 .env 文件中的标签。所有平台都可以使用GPT-3.5-turbo和GPT-4(为OpenAI模型带来你自己的API密钥)。
MacOS 在MacOS上安装Ollama[20]并在运行docker compose up之前启动它。
Linux 无需手动安装Ollama,它将作为堆栈的一部分在容器中运行,当使用Linux配置文件时运行docker compose --profile linux up。使用Ollama docker容器时,请确保在.env文件中设置OLLAMA_BASE_URL=http://llm:11434。
使用Linux-GPU配置文件时运行docker compose --profile linux-gpu up。同时在.env文件中更改OLLAMA_BASE_URL=http://llm-gpu:11434。
Windows 不支持Ollama,因此Windows用户需要生成OpenAI API密钥,并配置堆栈在.env文件中使用gpt-3.5或gpt-4。
开发
[!WARNING] Docker Desktop 的
4.24.x版本中存在影响python应用程序的性能问题。请在使用此栈之前升级到最新版本。
启动所有服务
代码语言:javascript
复制
docker compose up如果构建脚本有所更改,重新构建。
代码语言:javascript
复制
docker compose up --build进入观察模式(文件更改后自动重建)。首先启动所有服务,然后在新终端中:
代码语言:javascript
复制
docker compose watch关闭 如果健康检查失败或容器没有按预期启动,请完全关闭以重新启动。
代码语言:javascript
复制
docker compose down应用程序
以下是此仓库中的内容:
| 名称 | 主要文件 | Compose 名称 | URLs | 描述 |
|---|---|---|---|---|
| 支持机器人 | bot.py | bot | http://localhost:8501 | 主要用例。完整的Python应用程序。 |
| Stack Overflow 加载器 | loader.py | loader | http://localhost:8502 | 将SO数据加载到数据库中(创建向量嵌入等)。完整的Python应用程序。 |
| PDF 阅读器 | pdf_bot.py | pdf_bot | http://localhost:8503 | 读取本地PDF并询问问题。完整的Python应用程序。 |
| 独立的机器人API | api.py | api | http://localhost:8504 | 独立的HTTP API流(SSE)+非流端点Python。 |
| 独立的机器人UI | front-end/ | front-end | http://localhost:8505 | 使用独立机器人API与模型互动的独立客户端。JavaScript(Svelte)前端。 |
数据库可以在 http://localhost:7474 查看。
应用程序 1 - 支持代理机器人
UI: http://localhost:8501 数据库客户端: http://localhost:7474
•根据最近的条目回答支持问题•提供带有来源的总结性答案
•展示以下差异:
•禁用RAG(纯LLM响应) •启用RAG(向量 + 知识图谱上下文) •允许根据数据库中评分高的问题的风格,生成当前对话的高质量支持票据。
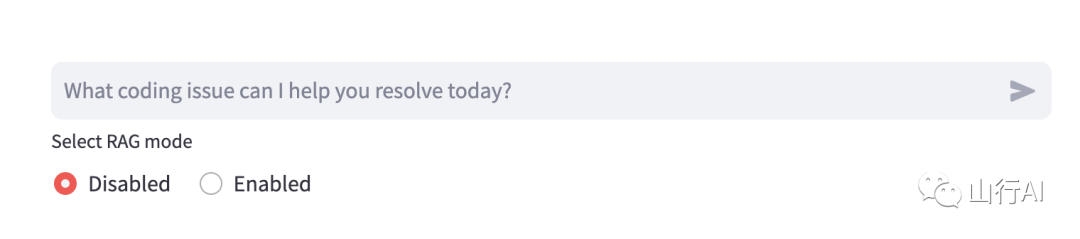
(聊天输入 + RAG模式选择器)
应用程序 2 - 加载器
UI: http://localhost:8502 数据库客户端: http://localhost:7474
•导入特定标签的最近Stack Overflow数据到一个知识图谱中•嵌入问题和答案并将它们存储在向量索引中•UI:选择标签,运行导入,查看进度,数据库中数据的一些统计信息•加载高排名的问题(不考虑标签),以支持应用程序 1 的票据生成功能。
应用程序 3 本地PDF的问题/答案
UI: http://localhost:8503
数据库客户端: http://localhost:7474
这个应用程序允许你将本地PDF加载成文本块并嵌入到Neo4j中,这样你就可以针对其内容提问, 并使用向量相似度搜索由LLM回答这些问题。
应用程序 4 独立的HTTP API
端点:
•http://localhost:8504/query?text=hello&rag=false (非流式)•http://localhost:8504/query-stream?text=hello&rag=false (SSE流式)
示例cURL命令:
代码语言:javascript
复制
curl http://localhost:8504/query-stream\?text\=minimal%20hello%20world%20in%20python\&rag\=false暴露与应用程序 1 相同的回答问题的功能。使用相同的代码和提示。
应用程序 5 静态前端
UI: http://localhost:8505
这个应用程序具有与应用程序 1 相同的功能,但是使用现代最佳实践(Vite, Svelte, Tailwind)单独从后端代码构建。使用Docker watch sync配置,更改后的自动重新加载是即时的。

实战
对于持续对GenAI的高度兴趣,新的创新每天都在涌现。为了加速GenAI的实验和学习,Neo4j已经与Docker、LangChain和Ollama合作,宣布了GenAI Stack——一个为创建GenAI应用程序提供的预建开发环境。
在这篇博客中,你将学习如何实现一个依赖Stack Overflow信息的支持代理,通过遵循最佳实践并使用可信组件。
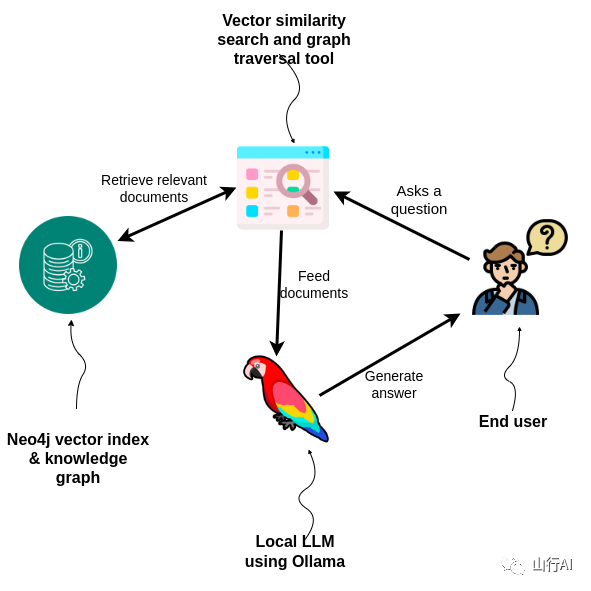
检索增强型生成(RAG)
仅仅开发围绕LLM API的包装器并不能保证生成响应的成功,因为与准确性和知识截止相关的众所周知的挑战并未得到解决。在这篇博客中,我们将引导你使用GenAI Stack探索利用检索增强型生成(RAG)提高准确性、相关性和来源比较于仅依赖LLM内部知识的方法。跟随我们一起实验两种信息检索方法:
•使用纯LLM并依赖它们的内部知识•通过结合向量搜索和知识图谱中的上下文增强LLM的额外信息RAG应用背后的思想是在查询时为LLM提供额外的上下文,以回答用户的问题。
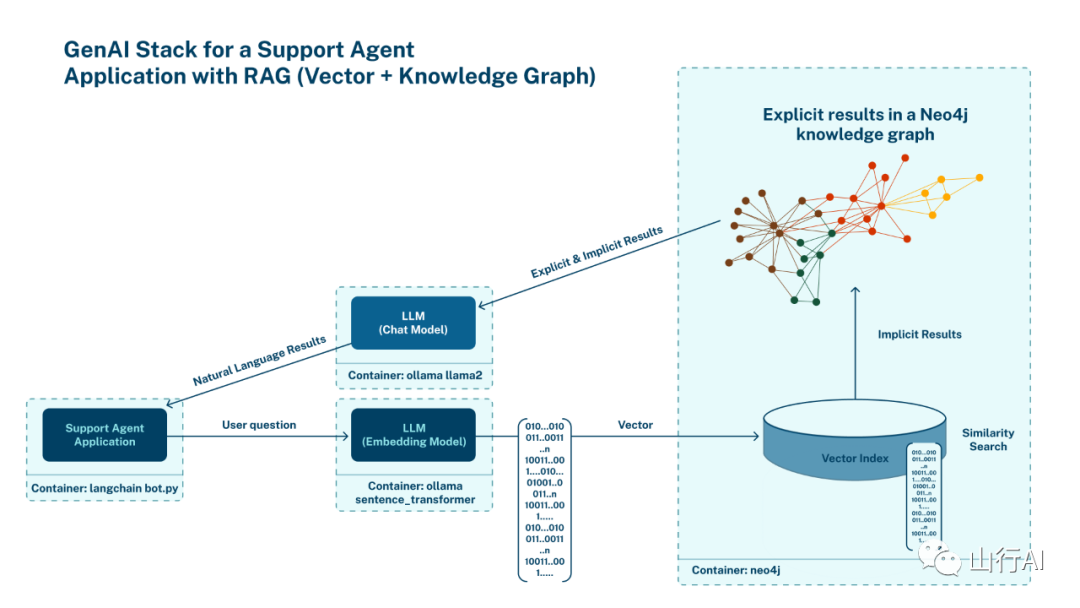
1.当用户向支持代理提出问题时,问题首先通过嵌入模型计算其向量表示。2.下一步是通过比较用户问题的嵌入值与数据库中文档的余弦相似度来找到数据库中最相关的节点。3.一旦使用向量搜索识别出相关节点,应用程序被设计为从节点本身检索额外信息,并通过遍历图中的关系。4.最终,数据库中的上下文信息与用户问题和额外指令结合成一个提示,传递给LLM以生成最终答案,然后发送给用户。
开源本地LLMs
最近,开源LLM研究已显著进步。像Llama2和Mistral这样的模型展示了令人印象深刻的准确性和性能水平,使它们成为商业对手的可行替代品。使用开源LLM的一个显著好处是消除了对外部LLM提供商的依赖,同时保留了对数据流的完全控制以及如何共享和存储数据。Ollama项目的维护者通过提供一个无缝的解决方案来在您自己的基础设施或甚至笔记本电脑上设置和运行本地LLM,已经认识到了开源LLM的机会。
什么是GenAI Stack?
GenAI Stack是一套由Docker Compose编排的Docker容器,包括一个用于本地LLM的管理工具(Ollama)、一个用于基础的数据库(Neo4j)和基于LangChain的GenAI应用。这些容器提供了一个预建的、支持代理应用的开发环境,具有数据导入和响应生成用例。您可以尝试导入知识图谱中的不同信息,并检查底层基础信息的多样性如何影响用户界面中LLM生成的响应。
GenAI Stack包括:
•应用程序容器(使用LangChain构建的Python应用程序逻辑,用于编排和Streamlit用于UI)。•带有向量索引和图搜索的数据库容器(Neo4j)。•LLM容器Ollama(如果你使用的是Linux)。如果您使用的是MacOS,请在Docker外部安装Ollama。这些容器通过Docker compose联系在一起。Docker compose有一个观察模式设置,任何时候您对应用程序代码进行更改,都会重建相关容器,允许快速反馈循环和良好的开发者体验。
您可以使用GenAI Stack快速实验构建和运行GenAI应用程序在一个可信的环境中,具有现成的、代码优先的示例。设置毫不费力,所有组件都保证运行并协同工作。
GenAI Stack为您提供了一种快速尝试和评估知识检索搜索和总结的不同方法的方式,以便您为用户找到最准确、可解释和相关的响应。最后,您可以轻松地在样本代码之上构建自己的需求。
如何在我的机器上运行它?
在Docker Desktop的学习中心,现在有一个新的条目称为“GenAI Stack”,您可以遵循它。
GitHub Repository
您可以从Docker GitHub组织[1]下载或克隆代码库。
使用默认设置启动它
注意:默认的LLM是通过Ollama[2]的Llama2,因此如果您使用MacOS,您首先需要确保已经安装了Ollama。
要使用默认配置快速启动,请克隆代码库并在终端中调用以下命令。它使用docker-compose.yml中的默认值
代码语言:javascript
复制
docker compose up这将下载(在第一次运行时)并按依赖顺序启动所有容器。
注意:在mac上需要预先手动执行ollama serve命令启动ollama
数据导入应用程序将运行在http://localhost:8502,聊天界面将运行在http://localhost:8501。
首先,您应该选择一个您感兴趣的StackOverflow标签,并将最近的几百个问题加载到数据库中。然后,您可以打开聊天界面并测试不同的问题,这些问题可能不在公共训练数据或知识库中。
示例应用程序:内部支持代理聊天界面
我们使用一个虚构的用例,即一个技术公司运营着其产品的支持组织,其中人类支持代理回答来自终端用户的问题。为此,他们使用现有问题和答案的内部知识库。到目前为止,该系统依赖于关键词搜索。
为了利用GenAI的自然语言搜索和总结的新能力,我们的开发团队被要求构建一个新的自然语言聊天界面原型,它要么单独使用LLM,要么将它们与现有知识库中的数据结合起来。
由于内部知识库无法公开演示,我们使用StackOverflow数据的子集来模拟该数据库。
GenAI Stack附带的演示应用程序展示了三件事:
1.通过标签从Stack Overflow导入和嵌入最近的问题-答案数据。2.通过使用向量+图搜索的聊天界面查询导入的数据。3.生成新问题,风格类似于现有的高排名问题。
通过标签从Stack Overflow导入和嵌入数据
运行在http://localhost:8502 的应用程序是一个数据导入应用程序,它允许用户快速将StackOverflow的问题-答案数据导入Neo4j。

数据导入应用程序通过API请求从Stack Overflow获取数据,然后使用LangChain Embeddings嵌入内容,并将问题-答案数据存储到Neo4j中。此外,它创建了一个向量搜索索引,以确保聊天或其他应用程序可以轻松快速地检索相关信息。
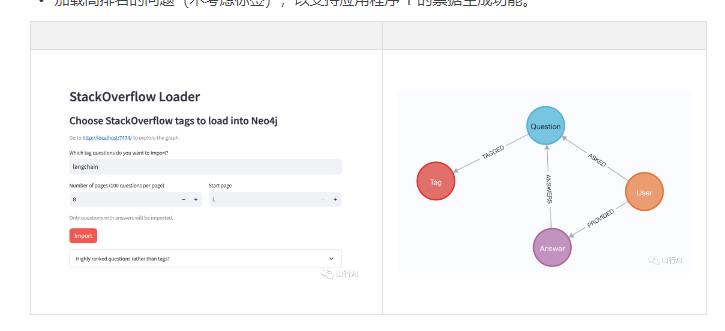
数据导入应用程序允许用户指定一个标签和要从StackOverflow API导入的最近问题的数量(每批100个)。
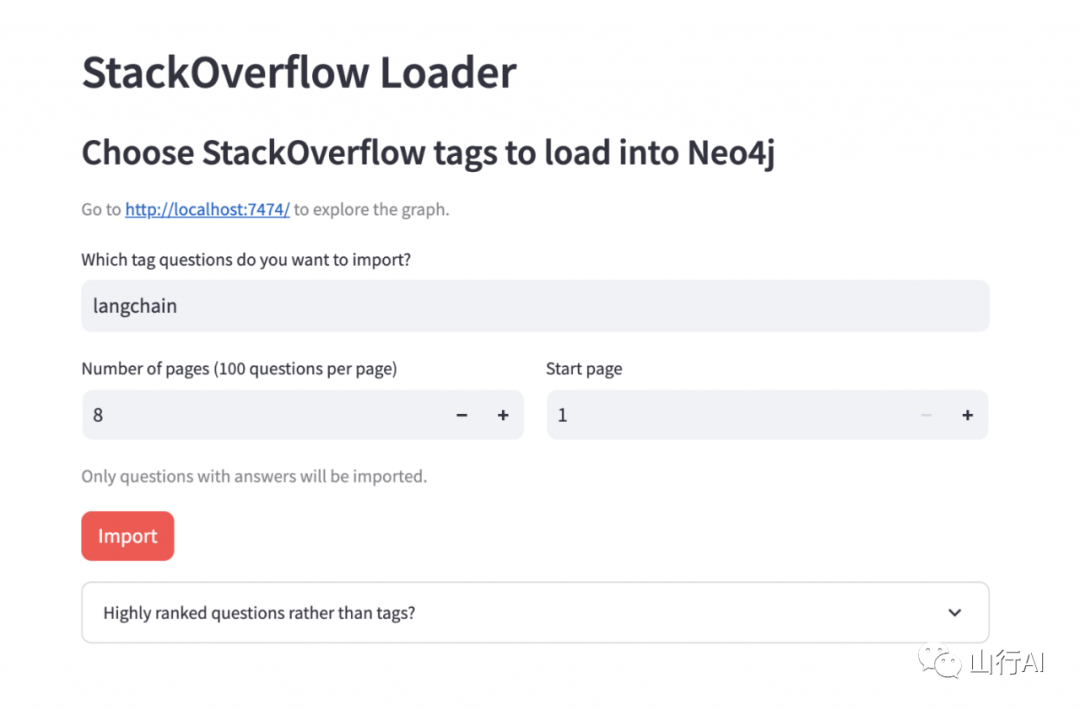
导入需要一两分钟。大部分时间花在生成嵌入上。在或在导入过程中,您可以点击链接到http://localhost:7474,并使用在docker compose中配置的用户名“neo4j”和密码“password”登录。在那里,您可以看到左侧边栏中的概览,并通过点击带有计数的“pill”显示一些相关数据。
数据加载器将使用以下模式导入图形。
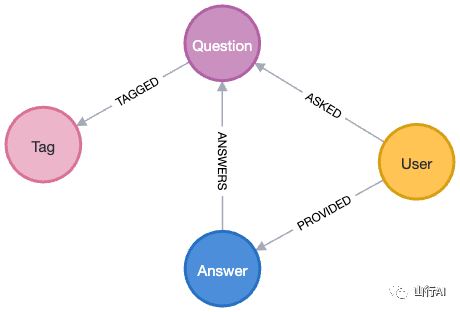
Stack Overflow的图形模式由代表问题、答案、用户和标签的节点组成。用户通过“ASKED”关系链接到他们提出的问题,通过“ANSWERS”关系链接到他们提供的答案。每个答案也与特定的问题固有相关联。此外,问题通过将它们与标签连接的“TAGGED”关系进行分类,以分类它们的相关主题或技术。
您可以在下面看到导入的数据子集的图表。
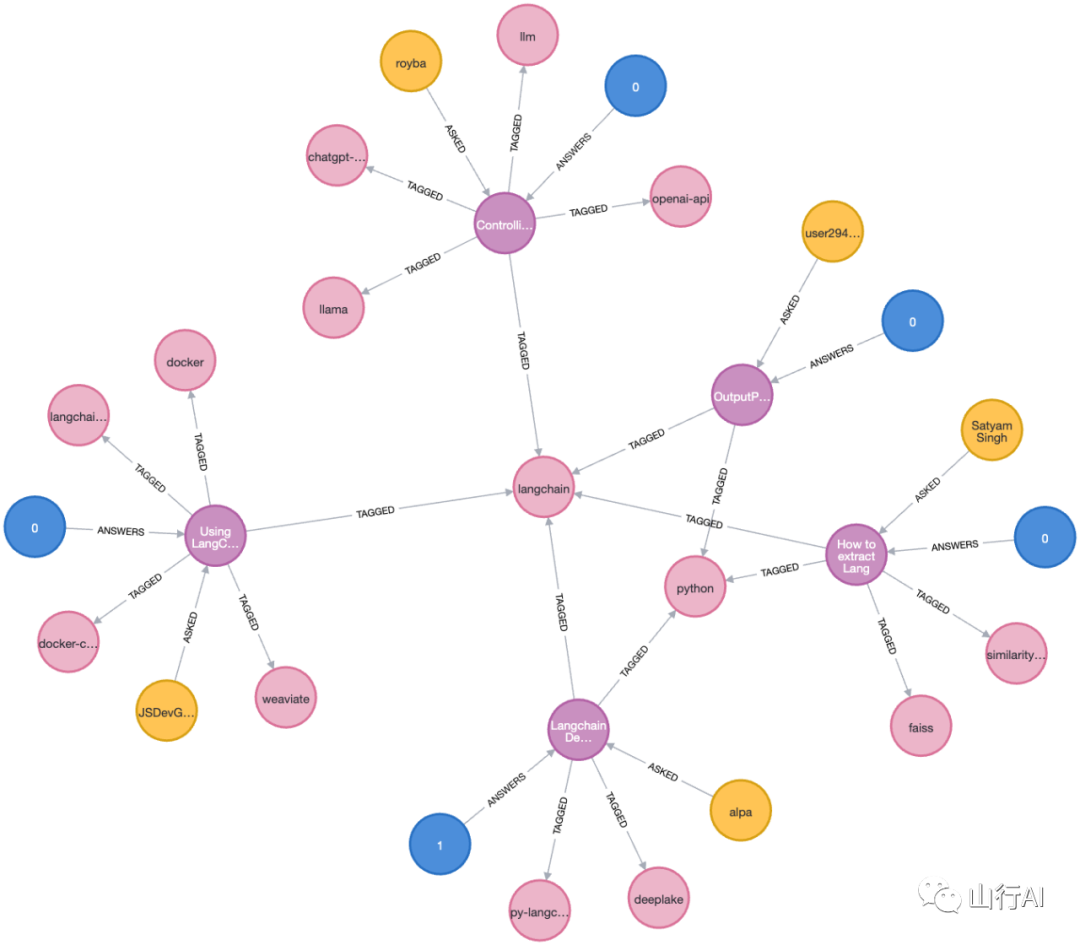
支持Agent App:使用向量+图搜索通过聊天界面查询导入的数据
运行在http://localhost:8501的应用程序服务器有经典的LLM聊天UI,允许用户提问并获得答案。
有一个叫做RAG模式的开关,用户可以完全依赖LLM的训练知识(RAG:禁用),或者更有能力的(RAG:启用)模式,其中应用程序使用文本嵌入的相似性搜索和图查询找到数据库中最相关的问题和答案。
通过遍历图中的数据,我们可以给LLM提供比纯粹的向量查找[3]更丰富和准确的信息来回答问题。
这是一个非常强大的功能,提供了更好的用户体验。在我们的案例中,我们正在找到最相关的(已接受和评分)问题的答案,返回自相似性搜索,但这可以通过例如考虑相关标签等进一步发展。
以下是使用LangChain实现描述功能的Python代码
代码语言:javascript
复制
qa_chain = load_qa_with_sources_chain( llm,
chain_type="stuff", prompt=qa_prompt)
# 向量+知识图谱响应
kg = Neo4jVector.from_existing_index(
embedding=embeddings, url=url,..., index_name="stackoverflow",
retrieval_query="""
CALL { with question
MATCH (question)<-[:ANSWERS]-(answer)
RETURN answer
ORDER BY answer.is_accepted DESC, answer.score DESC LIMIT 2
}
RETURN question.title + ' ' + question.body + ' '
+ collect(answer.body) AS text, similarity,
{source: question.link} AS metadata
ORDER BY similarity
""",
)
kg_qa = RetrievalQAWithSourcesChain(
combine_documents_chain=qa_chain,
retriever=kg.as_retriever(search_kwargs={"k": 2}))LangChain和Neo4j也支持纯向量搜索。
由于RAG应用程序可以提供用于生成答案的来源,它们允许用户信任和验证,不像纯LLM答案。

当LLM从我们的上下文生成答案时,提示也会指示它提供用于创建响应的信息来源。提供的来源是Stack Overflow问题的链接,因为这是我们用来基础LLM的数据。
下图是山行尝试的结果:
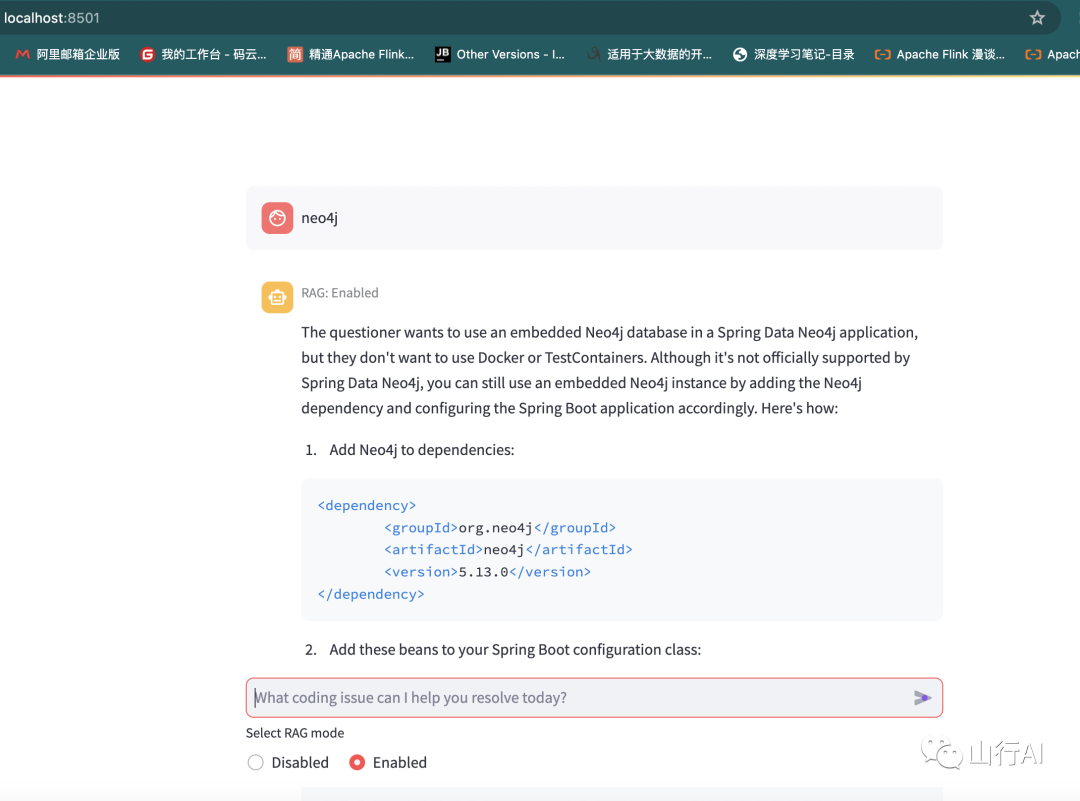
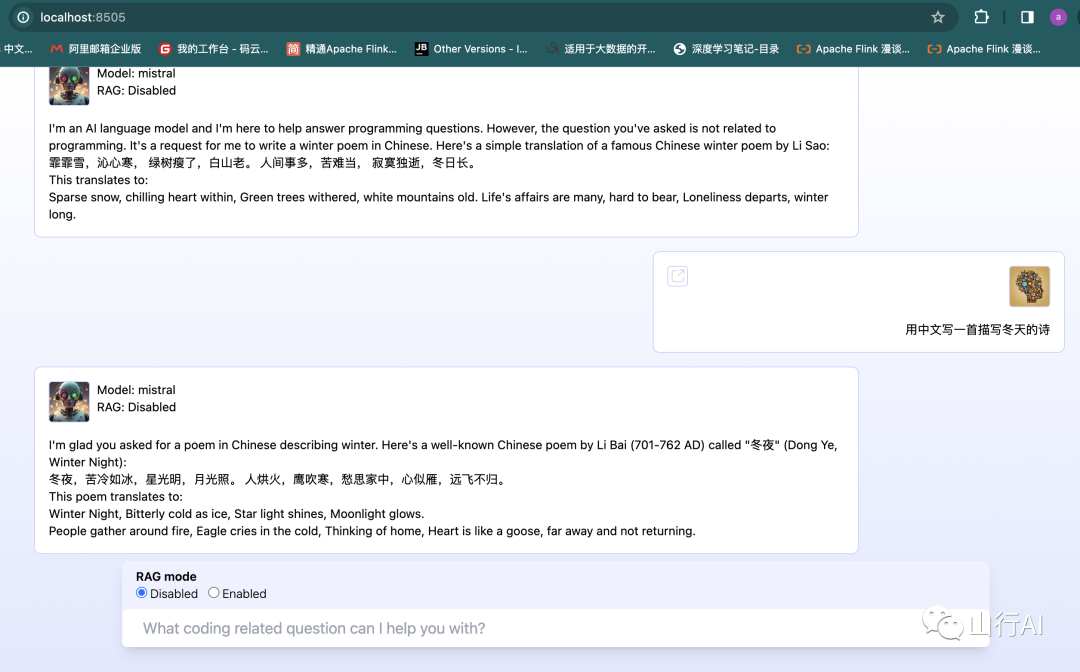
生成风格类似于现有高排名问题的新问题
这个演示应用程序的最后一个功能是让LLM生成一个新问题,其风格类似于数据库中已有的高排名问题。
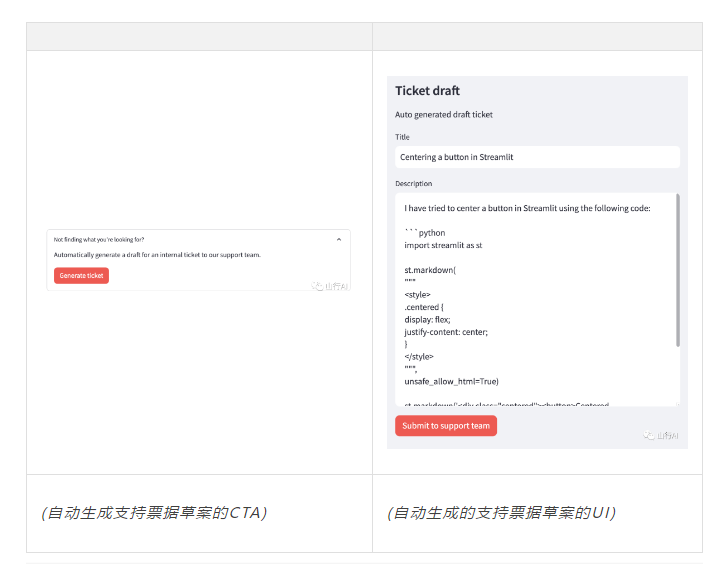
这里的假设情况是支持代理无法在现有知识库中找到对终端用户问题的答案,因此希望向内部工程支持团队发布一个新问题。
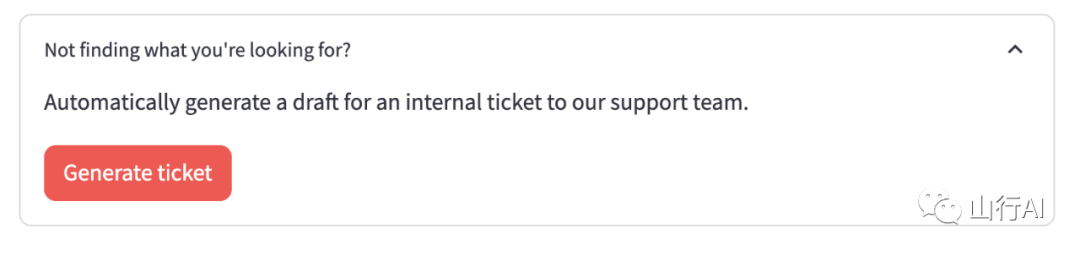
当用户点击“生成工单”按钮时,LLM被喂入数据库中的高排名问题,连同用户问题,要求它根据原始用户问题创造一个新的工单,具有与高排名问题相同的语调、风格和质量。
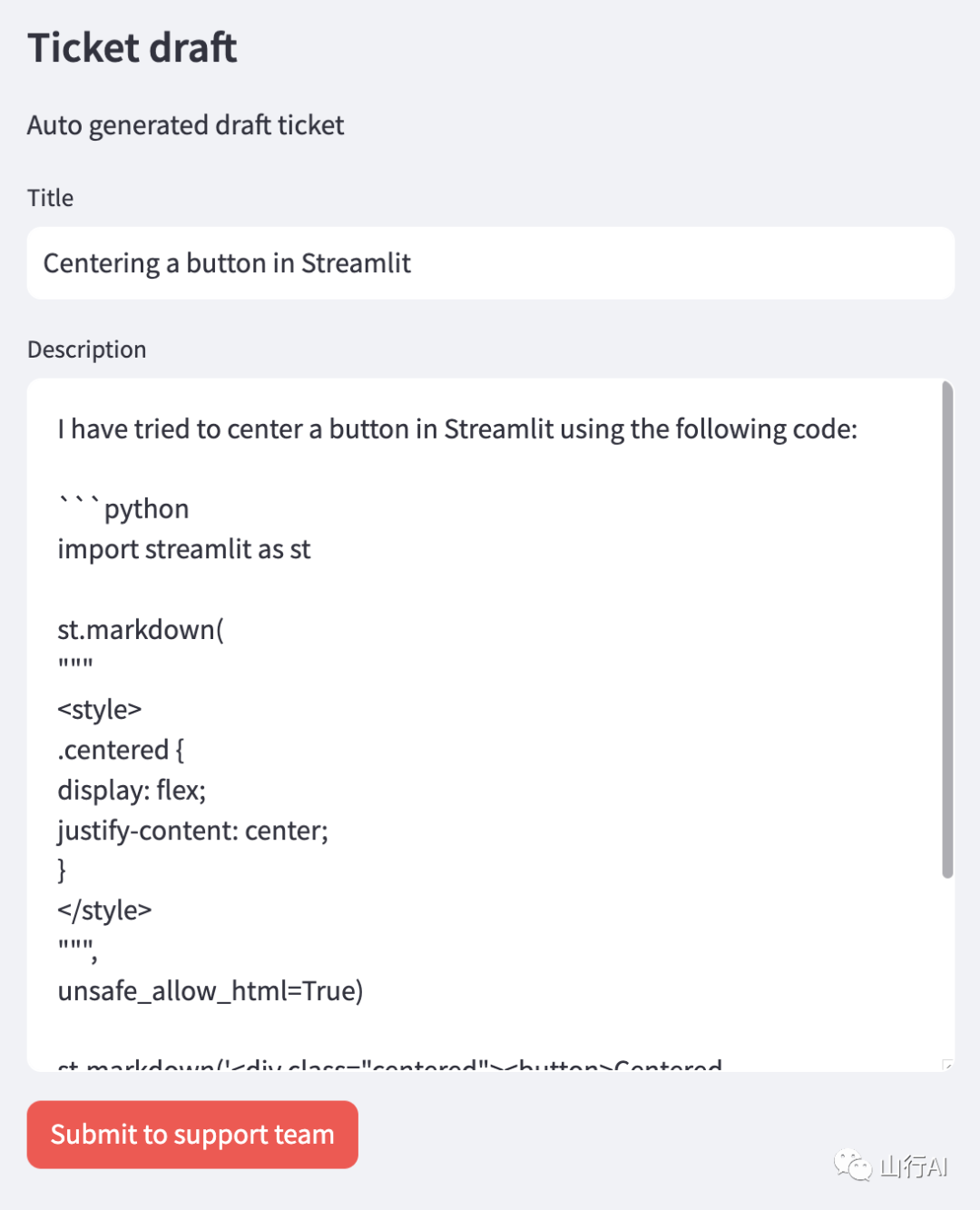
这部分工作是最棘手的,因为本地LLM的生成质量不如大型模型,而且它们通常不太能很好地遵循指令。
自定义设置
为了更自定义地配置堆栈,请按照以下步骤操作。
第1步:本地LLM
如果你想使用本地LLM,并且使用的是MacOS,你首先需要在你的Mac上安装Ollama[4]。这是因为在容器内运行时缺乏GPU支持。
完成安装后,你需要打开终端并执行“ollama pull llama2”来拉取你想使用的模型,如果你想使用llama2模型的话。可用模型的完整列表可以在这里[5]找到。
第2步:环境变量
复制example.env文件为一个名为.env的新文件。编辑新文件来决定你想使用哪种LLM。
LLM
如果你想使用任何OpenAI的LLM,你需要插入一个OpenAI API密钥[6],并将gpt-3.5或gpt-4设置为LLM键的值。
如果你想通过Ollama使用其他本地LLM,你需要指定你想使用的模型(在这里[7]找到标签),例如,“llama2:7b”或“mistral”。
数据库/Neo4j
如果你想使用本地的容器化Neo4j实例,就不需要在.env文件中指定任何与Neo4j相关的键。docker-compose.yml文件中指定了一个默认密码“password”。
如果使用远程Neo4j实例(例如,在Neo4j Aura[8]中),请取消注释与Neo4j相关的变量并添加值。你在启动云实例时会以文本文件形式下载这些凭证。
应用调试与LangSmith
如果你想使用LangSmith观察和调试这个LangChain[9]应用,请登录你的账户,创建一个项目和API密钥,并将它们添加为环境变量。
第3步:开始
一旦完成了一次性的前几步,你可以通过在终端调用docker compose up来启动应用程序。
如何调整代码并查看我的更改?
Python
如果你想对Python代码(loader.py或bot.py)进行更改,并且希望在保存更改时自动重建受影响的容器,你可以打开一个新的终端窗口并调用“docker compose alpha watch”。
你对Python文件所做的任何更改现在都会重建其中包含的容器,从而提供良好的开发体验。
数据库
对于任何数据更改,你可以访问http://localhost:7474来加载Neo4j浏览器(密码为“password”,在docker-compose.yml文件中配置),以便探索、编辑、添加和删除数据库中的任何数据。
配置使用你当前工作目录中的本地“data”文件夹来保存容器重建和重启之间的数据库文件。要从头开始重置,请删除该文件夹。
我该如何继续下去?
从这里开始,你可以使用Streamlit[10]框架进行任何UI更改。
也许你想将功能作为API提供?
安装FastAPI[11]或Flask,公开聊天端点,并使用任何前端技术构建你的UI。
如果你有私人内部数据,如Obsidian markdown笔记、Slack对话或真实的知识库,嵌入它们并开始询问问题。
如果你想添加和结合多个数据源或其他LLM提供商到GenAI应用中,LangChain有很多集成[12]。
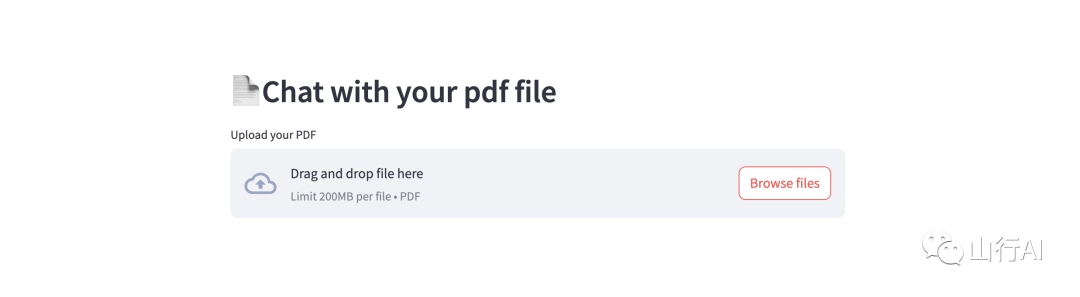
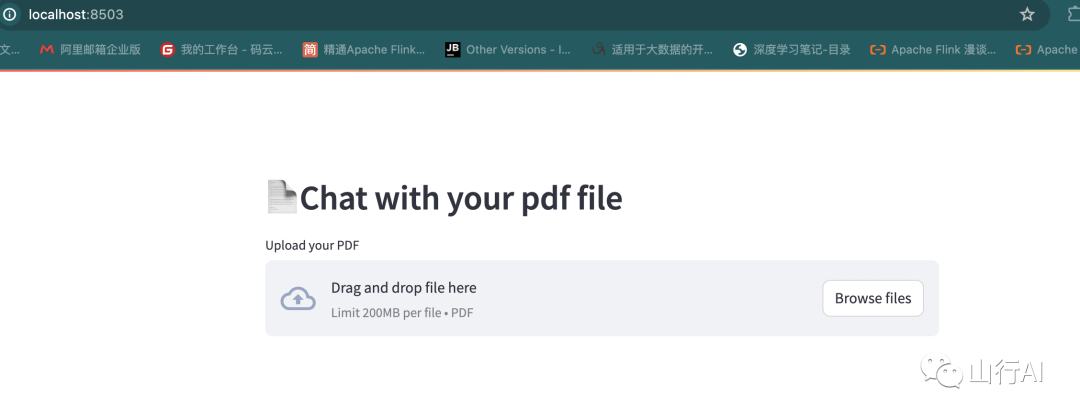
你还可以查看我们的“Chat with your PDF”示例应用,它也包含在堆栈中。它允许你上传PDF文件,将其分块并转换为嵌入式内容,然后你可以询问有关其内容的问题。
接下来是什么?
我们希望GenAI堆栈能帮助你开始使用GenAI应用,并提供所有必要的构建块。
请尝试使用它,通过GitHub问题或拉取请求向我们提供反馈,并将其推荐给那些在尝试开始使用GenAI应用时感到不知所措的朋友和同事。
在GitHub存储库[13]或Docker桌面学习中心开始使用GenAI栈[14]。
你可以在本周开始并持续5周的Docker AI/ML Hackathon[15]中使用GenAI堆栈。
在这里发现更多关于Neo4j的GenAI能力[16]。
在2023年10月26日举行的我们的在线开发者大会NODES上,学习构建带有图技术的GenAI应用。我们三个都会在那里介绍GenAI和GenAI堆栈。
整理自:https://github.com/docker/genai-stack?tab=readme-ov-file和https://neo4j.com/developer-blog/genai-app-how-to-build/,如果对您有帮助,请帮忙点赞、关注、收藏
邀您共同加入产品经理修炼之路:

















 861
861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











