







静下心来读源码,给想要了解spark sql底层解析原理的小伙伴们!
【本文大纲】
1、执行计划回顾
2、遍历过程概述
3、遍历过程详解
4、思考小问题
执行计划回顾
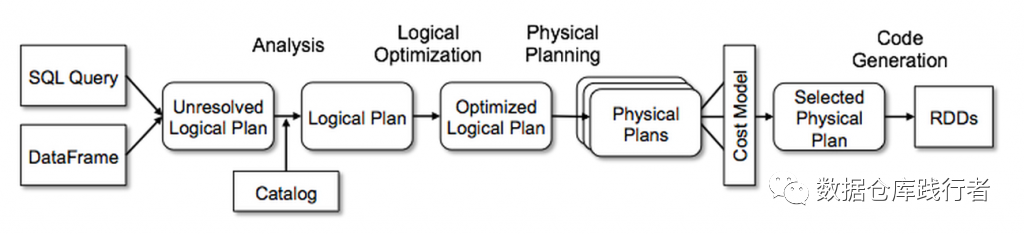
Spark sql执行计划的生成过程:
-
接收 sql 语句,初步解析成 logical plan
-
分析上步生成的 logical plan,生成验证后的 logical plan
-
对分析过后的 logical plan,进行优化
-
对优化过后的 logical plan,生成 physical plan
-
根据 physical plan,生成 rdd 的程序,并且提交运行
SELECT A,B FROM TESTDATA2 WHERE A>2结合上图,写测试用例,每一步生成的执行计划如下:

Spark sql解析会生成四种plan:
Parsed Logical Plan, Analyzed Logical Plan, Optimized Logical Plan, Physical Plan
上面这四种plan,无论是 LogicalPlan 还是 PhysicalPlan,都是通过树的形式表示。每一步都是对树进行操作,生成新的树。在这个过程中,对树的遍历非常重要。
遍历过程概述
最常用到的有 后序遍历 和 前序遍历 两种
后序遍历
TreeNode 中的 transformUp方法以及AnalysisHelper 中的 resolveOperatorsUp方法 等
这两个方法类似,以TreeNode 中的 transformUp为例:
def transformUp(rule: PartialFunction[BaseType, BaseType]): BaseType = {
// 先遍历子节点,得到叶子节点
val afterRuleOnChildren = mapChildren(_.transformUp(rule))
//对节点执行规则
val newNode = if (this fastEquals afterRuleOnChildren) {
CurrentOrigin.withOrigin(origin) {
//这里用到了PartialFunction的applyOrElse方法,用来避免undefined的情况发生。如果当前节点应用rule没有匹配的话,则返回默认的当前节点本身
rule.applyOrElse(this, identity[BaseType])
}
} else {
CurrentOrigin.withOrigin(origin) {
rule.applyOrElse(afterRuleOnChildren, identity[BaseType])
}
}
// If the transform function replaces this node with a new one, carry over the tags.
newNode.copyTagsFrom(this)
newNode
}递归逻辑:
-
递归结束条件:如果是子节点,那么使用该规则执行该节点,并且返回执行规则后的节点
-
递归继续条件:如果有子节点,那么先根据遍历子节点的结果,生成新节点。最后在使用该规则执行新节点
前序遍历
TreeNode 中的 transformDown方法以及AnalysisHelper 中的 resolveOperatorsDown方法 等
TreeNode 中的 transformDown为例:
def transformDown(rule: PartialFunction[BaseType, BaseType]): BaseType = {
// 对当前节点,调用rule函数。
val afterRule = CurrentOrigin.withOrigin(origin) {
// 这里rule函数有可能会生成新的节点,新节点的子节点可能不一样
rule.applyOrElse(this, identity[BaseType])
}
// Check if unchanged and then possibly return old copy to avoid gc churn.
//再遍历子节点
if (this fastEquals afterRule) {
// 如果当前节点没有变化,则继续遍历它的子节点
mapChildren(_.transformDown(rule))
} else {
// 如果当前节点发生改变,需要对改变后的节点进行遍历
afterRule.copyTagsFrom(this)
afterRule.mapChildren(_.transformDown(rule))
}
}递归逻辑:
-
递归结束条件:如果是叶子节点,那么使用规则对该节点操作,并且返回操作后的节点。
-
递归继续条件:如果不是叶子节点,那么先使用该规则对该节点操作。对操作后的该节点,继续遍历其子节点,用子节点的返回结果,来构建成新的节点。
遍历中的通用方法
上面几种方法中,都用到了TreeNode中的mapChildren、mapProductIterator方法
mapChildren
mapChildren 会依次调用函数对子节点操作,根据返回的结果生成一个新的节点。
def mapChildren(f: BaseType => Ba 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











