






在日常的学习中,为了提升模型的效果,我们经常会考虑将几个性能一般的模型集成起来形成一个性能较优的模型,而常见的模型集成的方法有bagging和boosting两种,在这里就这两种方式进行一定总结,供后续的研究和学习。
(一)bagging
Bagging的主要思想如下图所示,首先从数据集中有放回的采样出T个数据集,然后基于这T个数据集,每个训练出一个基分类器,再讲这些基分类器进行组合做出预测。Bagging在做预测时,对于分类任务,使用简单的投票法。对于回归任务使用简单平均法。若分类预测时出现两个类票数一样时,则随机选择一个。
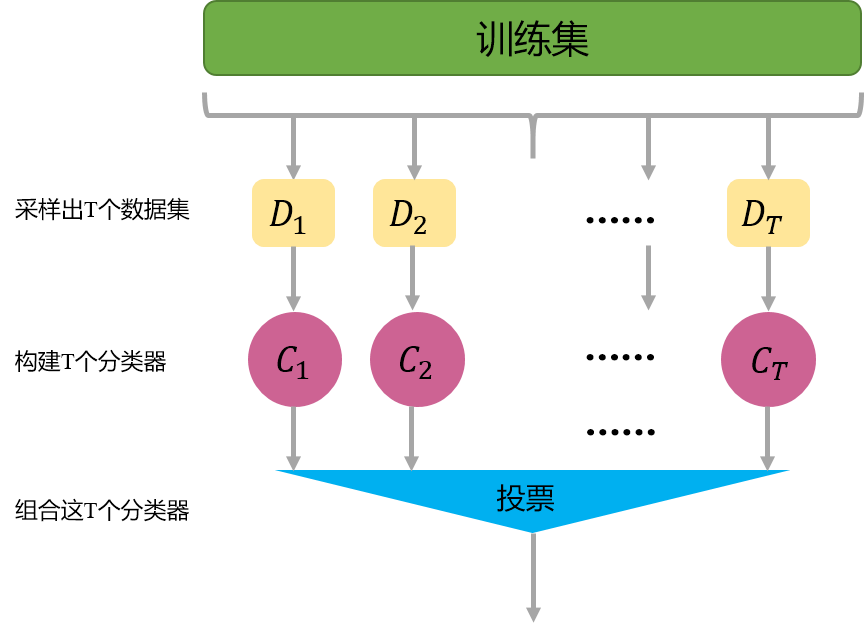
(二)boosting
与Bagging能够并行处理不同,Boosting由于各基学习器之间存在强依赖关系,因此只能串行处理,也就是说Boosting实际上是个迭代学习的过程。Boosting的工作机制为:先从初始训练集中训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整(比如增大被误分样本的权重,减小被正确分类样本的权重),使得先前基学习器做错的样本在后续的训练过程中受到更多关注,然后基于调整后的样本分布来训练下一个基学习器,如此重复,直到基学习器数目达到事先自定的值TTT,然后将这TTT个基学习器进行加权结合(比如错误率小的基学习器权重大,错误率大的基学习器权重小,这样做决策时,错误率小的基本学习器影响更大)。Boosting算法的典型代表有AdaBoost和XGBoost。Boosting算法可以用下图简略形象的描述下:
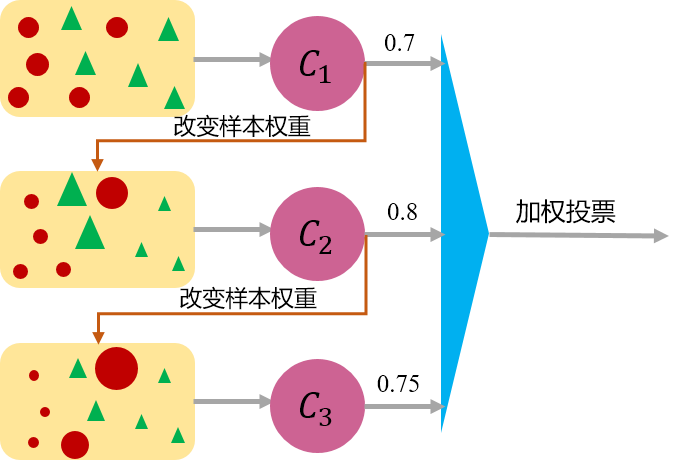
AdaBoosting方式每次使用的是全部的样本,每轮训练改变样本的权重。下一轮训练的目标是找到一个函数f 来拟合上一轮的残差。当残差足够小或者达到设置的最大迭代次数则停止。Boosting会减小在上一轮训练正确的样本的权重,增大错误样本的权重。(对的残差小,错的残差大),梯度提升的Boosting方式是使用代价函数对上一轮训练出的模型函数f的偏导来拟合残差。
比较总结:(https://www.cnblogs.com/earendil/p/8872001.html)
总之,Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;Bagging主要关注降低方差,因此它在不剪枝的决策树、神经网络等学习器上效用更为明显。Bagging算法是这样做的:每个分类器都随机从原样本中做有放回的采样,然后分别在这些采样后的样本上训练分类器,然后再把这些分类器组合起来。简单的多数投票一般就可以。其代表算法是随机森林。Boosting的意思是这样,他通过迭代地训练一系列的分类器,每个分类器采用的样本分布都和上一轮的学习结果有关。其代表算法是AdaBoost, GBDT。
机器学习算法来说,其泛化误差可以分解为两部分,偏差(bias)和方差(variance)。这个可由下图的式子导出(这里用到了概率论公式D(X)=E(X2)-[E(X)]2)。偏差指的是算法的期望预测与真实预测之间的偏差程度,反应了模型本身的拟合能力;方差度量了同等大小的训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。
(三)常见的变形模式
1、Adaboost
一般用于二分类,改进后可用于多分类。

详情可参考:https://blog.csdn.net/guyuealian/article/details/70995333
2、GBDT(gradient boosting)
Gradient Boosting一般用于回归任务,设定阈值后也可用于分类任务。主体思路是,根据梯度下降的启发,把学习器f(x)当作一个整体进行求导,具体如下:

算法过程:

而常见的GBDT是GB + DT,即将弱学习器固定为决策树(CART回归树)的GB算法。
算法过程:

(3)XGBT
XGBoost是一种比较特殊的GB方法,引入了二阶导的信息,并加入了正则项的约束。
理论推导很多:
- 目标函数增加正则项Ω(ft)
- 将式子通过泰勒公式展开到二阶导部分
- 将对所有样本的遍历变成对所有叶子节点的遍历,这样可以将每个叶子的值/一阶导/二阶导都用一个很优美的式子结合。最终得到目标函数的形式
- 最后叶子节点的w值为目标函数对w求导,令其为0的w值,使目标函数最小
与GBDT比较
- XGBoost引入了二阶导信息,并且不需要进行线搜,仅仅靠叶节点分裂得到树(复杂的推导保证了分裂的同时是沿着二阶+一阶导方向使loss降低);GBDT只使用了一阶导,并且需要进行线搜。
- XGBoost对目标函数做了正则化;GBDT没有
算法实现:

一些trick
- Shrinkage
其实就是在得到的www上乘上一个系数,让每一棵树学的东西不要太多,给之后的树学习空间;
这个方法在GBDT中也有用到。可以对应于传统机器学习中的学习率参数,xgb.train()函数中的eta参数
- 行列采样
其实就是Random Forest的方法,两个随机性的体现。
行采样(样本随机性bootstrap)xgb.train()中的subsample参数;
列采样(随机选择属性) xgb.train()中的colsample_bytree参数 防止过拟合
这是xgb.train()函数中最关键且不易理解的参数,更具体地可以看官方文档,或XGBoost参数详解
参考资料:
https://www.jianshu.com/p/005a4e6ac775(GBDT:梯度提升决策树)
https://blog.csdn.net/Wzz_Liu/article/details/90265893(Boosting方法入门)















 6731
6731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









