







在逛北邮人论坛python版时看到暖神推荐的python challenge这个编程通关小游戏,挺有意思的,还能用来练python。一直觉的自己会的太少,但是又不知道该从哪补起,该看些什么。这个编程小游戏对我这种菜鸟用来查漏补缺简直太好用了。按原计划五月得完成所有python练习和教程,下个月正式开始刷leetcode。时间很紧张啊。加油!
第0关
http://www.pythonchallenge.com/pc/def/0.html
尝试把0改成238会得到一个提示,再看图就会发现可能是2的38次方。python代码
math.pow(2, 38)或者用2**38均可得到
第1关
http://www.pythonchallenge.com/pc/def/map.html
由图找规律可得到每个字母都向后移了两位,所以给出的hint应该需要通过这个规则转换。
想到的方法一:用ord(char)获取字符的ASCII码,注意对于y和z得特殊处理,然后对ASCII码进行+2,之后用chr(int)再将数值还原为字符。另外对于.
方法二:也是通过方法一看到了hint才知道可以用maketrans()函数,语法大概是这样:
from string import maketrans # 必须调用 maketrans 函数。
intab = "abcdefghijklmnopqrstuvwxyz"
outtab = "cdefghijklmnopqrstuvwxyzab"
trantab = maketrans(intab, outtab)
str = "hello....wow!!!";
print str.translate(trantab);以上实例输出结果如下:
jgnnq....y4y!!!对url进行同样处理,map->ocr
第2关
http://www.pythonchallenge.com/pc/def/ocr.html
由提示可知需要去看网页源代码,于是发现了一大串注释掉的字符串。并且得到下一个提示,找出字符串中出现次数最少的字符。但是这么一大堆字符串直接复制进代码肯定不行。于是将之存储在txt文件中,通过readlines读取字符串。这里注意读取出来的是一个列表,还需要转为string。
代码如下:
file = open("ocr.txt")
s = file.readlines()
data = ""
for i in s:
data += i
count = {}
for i in data:
if i in count:
count[i] += 1
else:
count[i] = 1
for key, val in count.items():
print "%s:%d" % (key, val)结果:

但是这几个字母怎么组合呢?还得看字符串中这几个字母的顺序。因此将字符串中的字母过滤出来,去掉其他没用的字符。
代码:
import re
print "".join(re.findall("[a-z]", data)) 得到
第3关
http://www.pythonchallenge.com/pc/def/equality.html
hint的意思是说1个小写字母正好被3个大写字母包围,由图也可以看出1个小蜡烛正好被3个大蜡烛包围,可是没有字符串怎么做呢。由上一关的提示去看源代码,果然发现一大串字符串。写正则表达式即可,
代码如下:
import re
file = open("ocr.txt")
s = file.readlines()
data = ""
for i in s:
if i == '\n':
pass
else:
data += i
print re.findall(r'[a-z][A-Z]{3}([a-z])[A-Z]{3}[a-z]', data)结果:

得到linkedlist
PS:一开始始终没搞清为什么是xXXXxXXXx的格式,我写的正则表达式是XXXxXXX的。后来才想清楚,正好三个大写字母说明第4个就是小写字母了,所以大写字母的外围要包含一个小写字母。
第4关
http://www.pythonchallenge.com/pc/def/linkedlist.php
没有hint,按惯例去看源代码。果然
点击图片会发现url变化,使用网页里面的nothing值修改url,会到另一个页面。显然是用urllib做一个小爬虫,自动抓取网页,抽取给出的nothing值一层一层找到最后那个网页。
代码:
import re
import urllib2
import time
x = 400
url = "http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=12345"
while x:
request = urllib2.Request(url)
response = urllib2.urlopen(request)
str = response.read()
print str
s = re.findall(r'the next nothing is (\d+)', str)
url = "http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=" + s[0]
print url
x -= 1
time.sleep(3)
# read方法,返回获取到的网页内容 最后得到信息Yes. Divide by two and keep going.
http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=16044
于是除以2进入网页,提示nothing值25357,还要再来一次!好吧,将代码的url改一下再继续运行,…..最后得到peak.html
第5关
http://www.pythonchallenge.com/pc/def/peak.html
看源代码,peak hell发音相似???我读了半天都没想到是什么,看了一下别人的攻略。好吧,合起来读就是pickle,python中的pickle模块,这个我确实没学过也没听过,涨知识了。于是谷歌之教程。序列化的一个东西,再仔细看源代码。
首先,我们尝试把一个对象序列化并写入文件:
>>>d = dict(name='Bob', age=20, score=88)
>>>pickle.dumps(d)
"(dp0\nS'age'\np1\nI20\nsS'score'\np2\nI88\nsS'name'\np3\nS'Bob'\np4\ns."
pickle.dumps()方法把任意对象序列化成一个str,然后,就可以把这个str写入文件
pickle.load()方法的作用正好相反。
代码:
import pickle
file = open("pickle.txt", 'r')
line = file.readlines()
str = ""
for i in line:
str += i
# print str
d = pickle.loads(str)
print d # 是一个列表的列表
file.close()
for list1 in d:
for list2 in list1:
print list2[0]*list2[1],
print ""最后打印出来是这样:
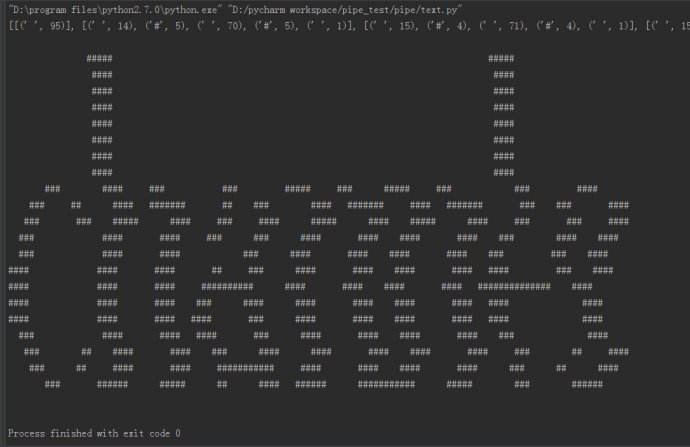
这个单词是channel?
第6关
http://www.pythonchallenge.com/pc/def/channel.html
没有hint,看源代码。最显眼的地方是让大家给python challenge捐款的。恩。这个挺好。我以为到这关就终止了?没看到啥有用的消息啊。。。百思不得其解,原谅我又看了一点点点别人的攻略,哦!!原来在源代码最上面一行
收集comments?comments在哪?瞬间蒙圈了。。
这里又学习到了新的知识,zip文件里面有很多隐藏的信息,其中就包括comment。谷歌之…学习zipfile模块,通过getinfo方法得到comment
代码:
import zipfile,re
zf = zipfile.ZipFile('channel.zip', 'r', zipfile.ZIP_DEFLATED)
# 打开已存在的zip文件
num = '90052'
comments = []
while True:
text = zf.read(num + '.txt')
num = re.findall('Next nothing is (\d+)', text)
print num
try:
num = num[0]
comments.append(zf.getinfo(num + '.txt').comment)
except:
break
for i in comments:
print i,结果:
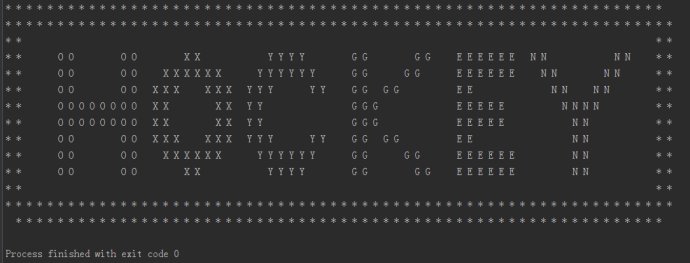
得到hockey,跳转url得到提示:it's in the air. look at the letters.















 2500
2500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









