









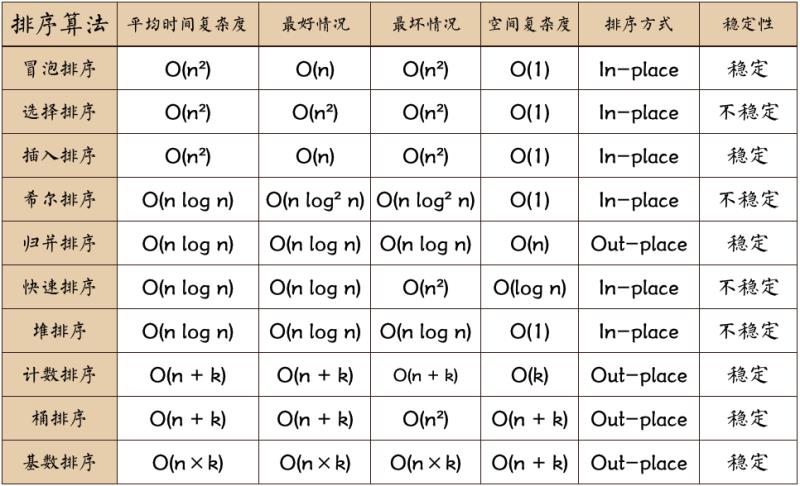
先来一张总结的图如下:
一、插入排序
原理:从第二个元素开始和之前的元素一个一个进行比较,如果比前面的元素小就与之交换,大于等于则继续下一个数的循环。
稳定性:稳定
时间代价:o(n*n)
最好—正序—时间代价o(n)
最差—倒序—时间代价o(n*n)
平均—乱序—时间代价o(n*n)
辅助存储空间:o(1)
总结:插入排序的时间复杂度最好的情况是已经是正序的序列,只需比较(n-1)次,时间复杂度为o(n),最坏的情况是倒序的序列,要比较n(n-1)/2次,时间复杂度为o(n*n),平均的话时间复杂度为o(n*n)插入排序使一种稳定的排序方法,排序元素比较少的时候很好,大量元素便会效率低下。
c++代码:
void InsertSort(int* pData, int length){
if(pData==NULL || length<=1)
return;
int iTemp;
int iPos;
for(int i=1;i<length;i++){
iPos=i-1;
iTemp=pData[i];
while(iPos>=0 && iTemp<pData[iPos]){
pData[iPos+1]=pData[iPos];
iPos--;
}
pData[iPos+1]=iTemp;
}
}
Python代码:
def insert_sort(lists):
count = len(lists)
for i in range(1, count):
key=lists[i]
j = i-1
while j>=0 and lists[j]>key:
lists[j+1]=list[j]
j-=1
lists[j+1]=key
return listsc++实现链表的插入排序:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* insertionSortList(ListNode* head) {
//链表的插入排序
if(NULL == head){
return NULL;
}
ListNode* helper = new ListNode(0);
ListNode* cur = head;
ListNode* pre = helper;
ListNode* nextptr = NULL;
while(cur != NULL){
nextptr = cur->next;
if(pre->next != NULL && pre->next->val >= cur->val){
pre = helper;
}
while(pre->next != NULL && pre->next->val < cur->val){
pre = pre->next;
}//while
cur->next = pre->next;
pre->next = cur;
cur = nextptr;
}//while
return helper->next;
}
};二、冒泡排序(交换排序)
原理:把小的元素往前调或者把大的元素往后调,一趟得到一个最大值或最小值。比较相邻的元素,如果反序则交换,过程也是分为有序区和无序区,所有元素都在无序区,经过第一趟后就能找出最大的元素,然后重复便可。
稳定性:稳定
时间代价:
最好—正序、无交换—时间代价o(n)
最差—倒序、循环次数=交换次数—时间代价o(n*n)
平均—乱序、中间状态—时间代价o(n*n)
辅助存储空间:o(1)
总结:时间复杂度最坏的情况是反序序列,要比较n(n-1)/2次,时间复杂度为o(n*n),最好的情况是正序,只进行(n-1)次比较,不需要移动,时间复杂度为o(n),而平均的时间复杂度为o(n*n)。冒泡排序也是一种稳定的排序算法,也是元素较少时效率比较高。
c++代码:
voidBubbleSort(int arr[], int length){
for(int i=0;i<length-1;i++){
for(int j=0;j<length-i-1;j++){
if(arr[j]>arr[j+1]){
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
}优化版本:如果第一次比较完没有交换即说明已经有序,不应该进行下一次遍历。还要已经遍历出部分有序的序列后,那部分也不用进行遍历,即发生交换的地方之后的地方不用遍历。
优化版本的c++代码:
voidBubbleSort(int arr[], int len){
int i,temp; //记录位置,当前所在位置和最后发生交换的地方
int current, last=len-1;
while(last>0){
for(i=current=0;i<last;i++){
if(arr[i]>arr[i+1]){
temp=arr[i];
arr[i]=arr[i+1];
arr[i+1]=temp;
//记录当前的位置,如果没有发生交换current值即for循环初始化的0
current= i;
}
}
//若current=0即已经没有可以交换的元素了即已经有序了
last=current;
}
}python代码:
def bubble_sort(lists):
count = len(lists)
for i in range(0, count):
for j in range(i+1, count):
if lists[i]>lists[j]:
lists[i],lists[j]=lists[j],lists[i]
return lists三、快速排序
原理:首先选一个轴值(pivot,也有叫基准的),将待排序记录划分成独立的两部分,左侧的元素均小于轴值,右侧的元素均大于或等于轴值,然后对这两部分再重复,直到整个序列有序。过程和二叉搜索树相似,就是一个递归的过程。
稳定性:不稳定
最好情况下—时间复杂度o(nlog2 n)
最坏情况下—时间复杂度o(n*n)
平均情况—时间复杂度o(nlog2 n)
空间复杂度o(nlog2 n)
总结:快速排序适用于元素多的情况
c++代码:
void quick_sort(int arr[], int left, int right){
if(left>=right){
return;
}
int key=arr[left];
//将第一个元素作为轴值
int low=left;
int high=right;
while(left<right){
while(left<right && arr[right]>=key){
right--;
}
if(left<right){
arr[left]=arr[right];
left++;
}
while(left<right &&arr[left]<=key){
left++;
}
if(left<right){
arr[right]=arr[left];
right--;
}
}
arr[right]=key;
quick_sort(arr, low, left-1);
quick_sort(arr, left+1, high);
}
python代码:
def quick_sort(lists, left, right):
if left>=right:
return lists
key = lists[left]
low = left
high = right
while left<right:
while left<right and lists[right]>=key:
right-=1
lists[left]=lists[right]
while left<right andlists[left]<=key:
left+=1
lists[right]=lists[left]
lists[right]=key
quick_sort(lists, low, left-1)
quick_sort(lists, left+1, high)
return lists四、堆排序
原理:堆的结构类似于完全二叉树,每个结点的值都小于或者等于其左右孩子结点的值,或者每个结点的值都大于或等于其左右孩子的值。堆排序过程将待排序的序列构造成一个堆,选出堆中最大的移走,再把剩余的元素调整成堆,找出最大的元素调整成堆,找出最大的再移走,重复直至有序。
稳定性:不稳定
时间复杂度:最好到最坏都是o(nlogn)
总结:较多元素的时候效率比较高
c++代码:(最大堆)
void Heapfy(int arr[], int i, int size){
int lchild=2*i+1;
int rchild=2*i+2;
int largest = i;
if(lchild<size &&arr[lchild]>arr[largest])
largest=lchild;
if(rchild<size &&arr[rchild]>arr[largest])
largest=rchild;
if(largest!=i){
int temp=arr[i];
arr[i]=arr[largest];
arr[largest]=temp;
Heapfy(arr,largest, size); //递归遍历
}
}
void buildHeap(int arr[], int size){
//建立最大堆,将堆中最大的值交换到根节点
for(int i=size/2-1;i>=0;i--){
Heapfy(arr,i, size);
}
//进行堆排序打印
for(int i=size-1;i>=0;i--){
cout<<arr[0]<<endl;
int temp=arr[0];
arr[0]=arr[i];
arr[i]=temp;
Heapfy(arr,0, i); //建立下一次的最大堆
}
}
python代码:(最大堆)
def adjust_heap(lists, i, size):
# 调整堆
lchild = 2*i+1
rchild = 2*i+2
max=i
if i<size/2:
if lchild<size andlists[lchild]>lists[max]:
max=lchild
if rchild<size andlists[rchild]>lists[max]:
max=rchild
if max!=i:
lists[max], lists[i] = lists[i],lists[max]
adjust_heap(lists, max, size)
def build_heap(lists, size):
# 构建堆
for i in range(0, (size/2))[::-1]:
# 从最后一个父节点开始搭建
adjust_heap(lists, i, size)
def heap_sort(lists):
# 堆排序
size = len(lists)
build_heap(lists, size)
# 打印排序后的元素
for i in range(0, size)[::-1]:
print lists[0]
# 在每次输出大数堆后的最大数后,把最后一个数移到根节点并调整堆
lists[0], lists[i] = lists[i], lists[0]
adjust_heap(lists, 0, i)
五、归并排序
原理:将若干个序列进行两两归并,直到所有待排序记录都在一个有序序列为止。
稳定性:稳定
时间复杂度:
最好—o(nlogn)
最差—o(n)
平均—o(nlogn)
总结:适用于元素较多时的排序
c++代码:
void Merge(intarr[], int reg[], int start, int end){
if(start>=end)
return;
//分成两部分
int len=end-start,mid=(len>>1)+start;
int start1=start, end1=mid;
int start2=mid+1, end2=end;
//然后合并
Merge(arr, reg, start1, end1);
Merge(arr, reg, start2, end2);
int k=start;
//两个序列一一比较,哪的序列的元素小就放进reg序列中,然后位置+1再与另一个序列原来位置的元素比较
//如此反复,可以把两个有序的序列合并成一个有序的序列
while(start1<=end1 &&start2<=end2){
reg[k++]= arr[start1]<arr[start2]?arr[start1++]:arr[start2++];
}
//然后分情况,如果序列的已经全部放进reg序列了就跳出循环
while(start1<=end1)
reg[k++]= arr[start1++];
while(start2<=end2_
reg[k++] = arr[start2++];
//把已经有序的reg序列放回arr序列中
for(k=start;k<=end;k++)
arr[k] = reg[k];
}voidMergeSort(int arr[], const int len){
//创建一个同样长度的序列,用于临时存放
int reg[len];
Merge(arr, reg, 0, len-1);
}python代码:
def merge(left, right):
i,j=0,0
result=[]
while i<len(left) and j<len(right):
if left[i] <=right[j]
result.append(left[i])
i+=1
else:
result.append(right[j])
j+=1
result += left[i:]
result += right[j:]
return result
def merge_sort(lists):
if len(lists)<=1:
return lists
num = len(lists)/2
left = merge_sort(lists[:num])
right = merge_sort(lists[num:])
return merge(left, right)六、希尔排序
原理:先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-1<...<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
稳定性:不稳定
时间复杂性:
最坏:o(n*n)
平均:o(n^1.2)
总结:希尔排序比冒泡排序快5倍,比插入排序大致快2倍。希尔排序比起QuickSort,MergeSort,HeapSort慢很多。但是它相对比较简单,它适合于数据量在5000以下并且速度并不是特别重要的场合。它对于数据量较小的数列重复排序是非常好的。
例子:
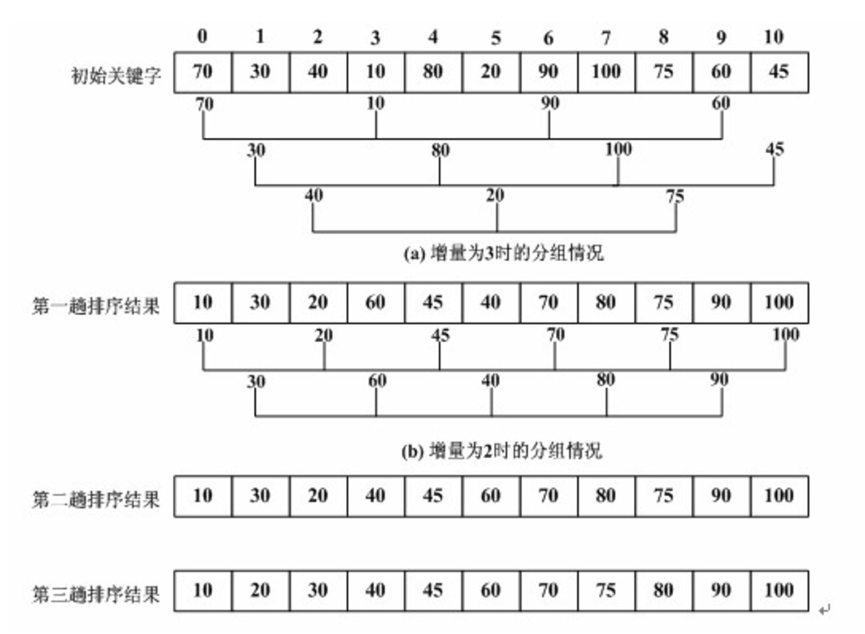
(1)初始增量为3,该数组分为三组分别进行排序。(初始增量值原则上可以任意设置(0<gap<n),没有限制)。
(2)将增量改为2,该数组分为2组分别进行排序。
(3)将增量改为1,该数组整体进行排序。
c++代码:
void shellSort(int arr[], int n){
int i,j,gap;
//gap为步长,每次减为原来的一半
for(gap=n/2; gap>0; gap/=2){
//共gap个组,对每一组都执行直接插入排序
for(i=0; i<gap; i++){
for(j=i+gap;j<n; j+=gap){
//如果a[j]<a[j-gap],则寻找a[j]位置,并将后面数据的位置都后移
if(a[j]<a[j-gap]){
int tmp=a[j];
int k=j-gap;
while(k>=0&& a[k]>tmp){
a[k+gap]=a[k];
k-=gap;
}
a[k+gap]=tmp;
}
}
}
}
}python代码:
def shell_sort(lists):
count=len(lists)
step=2
group = count/step
while group>0:
for i in range(0, group):
j=i+group
while j<count:
k=j-group
key = lists[j]
while k>=0:
if lists[k]>key:
lists[k+group] = lists[k]
lists[k]=key
k-=group
j+=group
group/=step
return lists七、计数排序
算法步骤:
代码:
#include <iostream>
using namespace std;
const int MAXN = 100000;
const int k = 1000; // range
int a[MAXN], c[MAXN], ranked[MAXN];
int main() {
int n;
cin >> n;
for (int i = 0; i < n; ++i) {
cin >> a[i];
++c[a[i]];
}
for (int i = 1; i < k; ++i)
c[i] += c[i-1];
for (int i = n-1; i >= 0; --i)
ranked[--c[a[i]]] = a[i];//如果是i表达的是原数标号,a[i]就是排序后的正确序列
for (int i = 0; i < n; ++i)
cout << ranked[i] << endl;
return 0;















 2497
2497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









