







 本文通过线性回归模型分析波士顿房价数据集,详细探讨了包括CRIM、ZN、INDUS等13个特征与房价的关系,并进行数据处理,为建立预测模型做准备。
本文通过线性回归模型分析波士顿房价数据集,详细探讨了包括CRIM、ZN、INDUS等13个特征与房价的关系,并进行数据处理,为建立预测模型做准备。
LinearRegression中文叫做线性回归,是一种基础、常用的回归方法。
2018年8月22日笔记
sklearn官方英文用户使用指南:https://sklearn.org/user_guide.html
sklearn翻译中文用户使用指南:http://sklearn.apachecn.org/cn/0.19.0/user_guide.html
0.打开jupyter notebook
不知道怎么打开jupyter notebook的朋友请查看我的入门指南文章:https://www.jianshu.com/p/bb0812a70246
1.载入数据集
波士顿房价数据集详细中文解释链接:http://sklearn.apachecn.org/cn/0.19.0/datasets/index.html#boston-house-prices
网页中内容截图如下:
查看数据集对象的属性和方法,代码如下:
from sklearn.datasets import load_boston
dir(load_boston())
上面一段代码的运行结果如下:
['DESCR', 'data', 'feature_names', 'target']
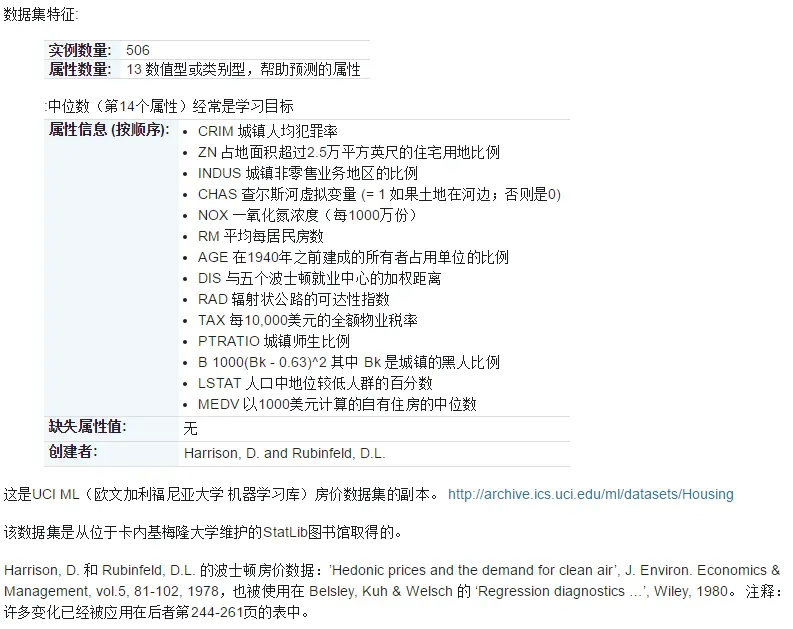
查看数据集的描述,即打印数据集对象的DESCR属性,代码如下:
from sklearn.datasets import load_boston
print(load_boston().DESCR)
与上图中文文档的图对照阅读,可以加强对数据集的理解。
上面一段代码的运行结果如下图所示:
将506个样本13个特征组成的矩阵赋值给变量X,变量X为大写字母的原因是数学中表示矩阵使用大写字母。
将506个样本1个预测目标值组成的矩阵赋值给变量y。
载入数据集的代码如下:
from sklearn.datasets import load_boston
X = load_boston().data
y = load_boston().target
2.数据观察
使用pandas库完成数据分析阶段的任务。
首先实例化1个DataFrame对象赋值给变量df,DataFrame对象类似于Excel表格。
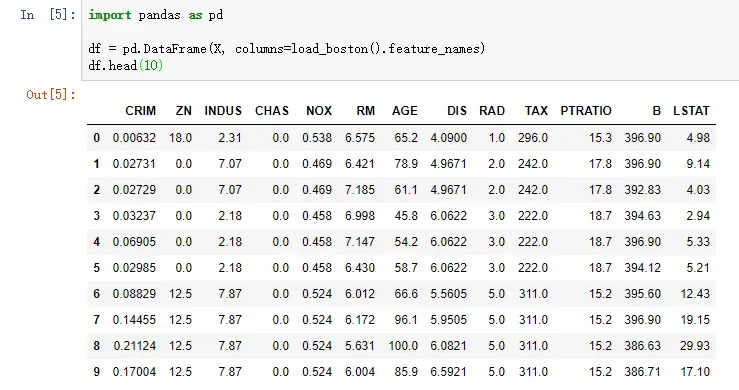
查看变量df的前10行,代码如下:
import pandas as pd
df = pd.DataFrame(X, columns=load_boston().feature_names)
df.head(10)
上面一段代码的运行结果如下图所示:
查看变量df中是否有空值,如果有空值,则需要对其进行处理,代码如下:
df.info()
上面一段代码的运行结果如下图所示:
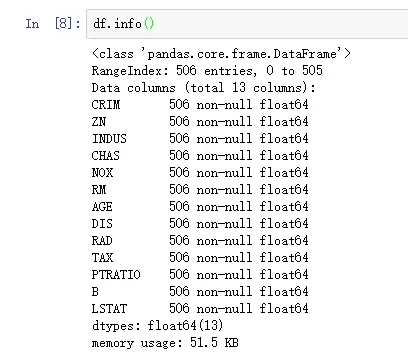
从上图的结果我们可以看出,数据总共有506行,13列。
在数据科学领域中,一般称事物的属性为 字段,13个字段中都有506个非空的float64类型的数值,即没有空值。
从上图的最后1行可以看出,该表格总共占用内存51.5KB。
在计算机科学中,B表示Byte,中文叫做 字节,b表示bit,中文叫做比特, 1Byte = 8bit。
占用内存的计算也并不复杂,1个float64类型的数值占用64bit,即8Byte,则总共
13*506*8/1024=51.39KB。
占用内存51.5KB比51.39KB略大,原因是表格中除了数据还得存储一些描述信息。
表格聚合运算的中文与英文简写对照如下表所示:
| 中文名 | 英文名 |
|---|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









