









![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RZaF7kF3-1653056252766)(https://secure2.wostatic.cn/static/81zY2K2svSWzMULfaLjkdM/image.png)]](https://img-blog.csdnimg.cn/1e6b25b25e064ecd80c01696a7b28a0f.png)
背景
作者开门见山说明了深度学习结构拥有越来越大的学习容量和性能的发展趋势,在一百万的图像数据上都很容易过拟合,所以常常需要获取几百万的标签数据用于训练,而这些数据公众通常是难以获取的。MAE的灵感来源是DAE(denosing autoencoder),去噪自编码器就是encoder的输入部分加上噪声作为输入,decoder还原真实的输入,其损失函数为decoder的输出与真实输入之间的均方误差,相比与原来的autoencoder,DAE必须去除噪声,学习到输入数据的重要特征。
在NLP领域中self-supervised pre-training 是解决对数据需求的成功方案,GPT(Decoder)中是基于自回归的语言模型,BERT(Encoder)中是基于masked autoencoding ,他们概念上很简单,都是移除一部分数据,然后预测移除部分的内容,在CV领域masked autoencoding 研究与NLP中区别:
- 过去十年,卷积是CV领域的主导,卷积操作无法直接讲mask-token 或者pos embeeding 集成到卷积网络中,这已经被VIT解决。(实际上卷积操作本身就是具有空间位置信息,不需要再引入位置信息)
- 信息密度不同。语言是人类生成的信号,具有高级语义和信息密集性,也就是一句话缺少一部分意思可能会发生变化,当预测极少数缺失的words时,显然需要引入复杂的语义理解。而图像是具有大量空间冗余的自然信号,缺失某个patch,并不影响对图像整体的理解。
- decoder部分在重建文本和图像之间,扮演不同的角色。在vision中,decoder重建像素级别,相比于识别来说,是一种低级别的语义。在language中,decoder预测缺失的words,其包含丰富的语义信息。虽然在BERT中,decoder是一个MLP,是微不足道的,但是在图像中,decoder的设计 决定着学到的潜在表征的语义级别。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8LNEoGXs-1653056252767)(https://secure2.wostatic.cn/static/sWtRobmyQdj9KaZUFTALN3/image.png)]](https://img-blog.csdnimg.cn/391428169f43405caad14941e7c4eb56.png)
图像来源于李宏毅2021 机器学习课程
通过以上分析,作者为视觉领域提出了一种简单、高效、可扩展的masked autoencoder。
设计特点:
- 不对称的encoder-decoder结构
- 随机mask一些image的patches
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kfqKXo1V-1653056252767)(https://secure2.wostatic.cn/static/ozNGUZstEfwzcHuToNaNcB/image.png)]](https://img-blog.csdnimg.cn/faa0598c0b0e420bbc0427e25b8a968c.png)
1.不对称设计
encoder部分遵循VIT的设计,但是仅仅作用在image没有被mask的patches上。其encoder patches也是通过线性映射得到,加上positional embeeding,然后输入transformer blocks。
decoder部分,decoder采用轻量化的设计,其输入是所有token的全集,包含两部分:encoder输出的visible patches以及 补齐位置的mask token ,通过unshuffle操作恢复原来的patch顺序,在送入decoder。decoder仅仅在预训练的时候使用用于重建图像的任务,只有encoder是用来产生识别任务的图像表征。因此decoder部分可以灵活设计,不必依赖于encoder。
note:
MAE中encoder与decoder的输入都增加了sin-cos位置编码,而且由于encoder与decoder部分的width不同,在encoder输出还使用了linear projection 匹配模型宽度。
VIT encoder输入还有一个class token ,为了迎合这种设计,MAE在encoder输入也增加一个用来辅助的虚拟token,这token被当做class token,在fintune和linear probing中用于训练分类器使用。
这种不对称设计大大减少了预训练的时间,同时也减少了内存消耗,可以轻易扩展MAE到大模型。
2.随机mask
遵循VIT,把图片分为规则的不重叠的patch,首先对输入的patch进行linear projection得到patch embeddings,并加上positional embeddings(采用sine-cosine版本);然后对tokens列表进行random shuffle,根据masking ratio去掉列表中后面的一部分tokens,然后送入encoder中。作者介绍采用均匀抽样的原因是为了阻止潜在的center bias(例如绝大部分masked patched围绕在图像中心)。
计算损失只计算unmask patch,不同于传统的DAE基于像素计算全部损失,这是因为计算全部像素的损失会导致精度下降大约0.5%
实验
作者在imageNet1K 数据集上进行预训练,采用ViT Large(ViT-L/16)作为消融实验研究的backbone,然后用两种方式进行监督训练评估其表征能力。
- finetune
- linear probing
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3AW0J7Ns-1653056252767)(https://secure2.wostatic.cn/static/kJkNF4KNkXYiTnAv9T4TCQ/image.png)]](https://img-blog.csdnimg.cn/97fe128e02584e2d985a4e2316a890f3.png)
上图是ViT-L(原始论文与作者复现)与MAE的比较top1-accuaracy
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y1yktO5g-1653056252768)(https://secure2.wostatic.cn/static/f3icf2rPf71sa7mwk8USTR/image.png)]](https://img-blog.csdnimg.cn/3a8e1d066b0541849795a08938bf0531.png)
上图是不同mask ratio下模型表现,可以发现fine-tune的效果整体要比linear probing好,但随着ratio的提升,linear probing的差距变化比较明显(54.6—73.5),而fine-tune(83.2-85)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KHacQ3bZ-1653056252768)(https://secure2.wostatic.cn/static/tpMHZEpwktrZoaZDnCtayX/image.png)]](https://img-blog.csdnimg.cn/63a64d9006914e8a80ff605e5339491e.png)
上图是decoder设计时,block深度和模型宽度(number of channel)的影响。灰色部分表示默认设置。可见深度对于linear probing是比较重要的,这可以解释为重建任务和识别任务的不同导致,在autoencoder的最后几层更偏向于重建,与识别关系不大。一个合适深度的decoder就可以实现重建任务,将潜在表征留在更抽象层次。这种设计可以在linear probing中提升8%(65.5→73.3)的精度。如果使用fine-tune,encoder的最后几层可以调整适应识别任务,decoder的深度影响就没有那么大。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-94Sq8srZ-1653056252768)(https://secure2.wostatic.cn/static/ERC6rrKP4eqr29o4PVesY/image.png)]](https://img-blog.csdnimg.cn/6a1fabc361a847888b2e603353b6de7c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KfJnmHJE-1653056252769)(https://secure2.wostatic.cn/static/4dUacVZaV3LN97JJESrmJs/image.png)]](https://img-blog.csdnimg.cn/445ad8893f5940adaa4dd956edeef0e7.png)
mask token,这里探讨的是encoder是否处理mask tokens带来的影响,从对比实验来看,encoder不处理mask tokens不仅效果更好而且训练更高效,首先linear probing的效果差异非常大,如果encoder也处理mask tokens,此时linear probing的效果较差,这主要是训练和测试的不一致带来的,因为测试时都是正常的图像,但经过finetune后也能得到较好的效果。最重要的是,不处理mask tokens模型的FLOPs大大降低(3.3x),而且训练也能加速2.8倍,这里也可以看到采用较小的decoder可以进一步加速训练
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R9DX8Ojl-1653056252769)(https://secure2.wostatic.cn/static/h1y1eLZnnUAAax9jRK26Uh/image.png)]](https://img-blog.csdnimg.cn/fe939b1ef37840b78fd9cb30d7728121.png)
不同的重建目标对效果的影响,从对比实验看,如果对像素值做归一化处理(用patch所有像素点的mean和std),效果有一定提升,采用PCA处理效果无提升。这里也实验了BEiT采用的dVAE tokenizer,此时训练loss是交叉熵,从效果上看比baseline有一定提升(finetune有提升,但是linear probing下降),但不如归一化处理的结果。注意的是dVAE tokenizer需要非常大的数据来单独训练,这是非常不方便的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HbQEXKs9-1653056252769)(https://secure2.wostatic.cn/static/p4aEdvBVXAKzwT33yoxJJc/image.png)]](https://img-blog.csdnimg.cn/cb646e6bd34541c7b8ff6fb66c2182ac.png)
数据增强的影响,MAE在无数据增强下(center crop)依然可以表现出好的效果,如果采用random crop(fixed size或random size)+random horizontal flipping(其实也属于轻量级)效果有微弱的提升,加上color jit效果反而有所下降。相比之下,对比学习往往强烈依赖于数据增强。这差异的背后主要是因为MAE采用的random mask patch扮演了数据增强的角色,每一次迭代的mask都是不同的因此可以产生新的训练样本。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4SCnxpFP-1653056252770)(https://secure2.wostatic.cn/static/54tCsRHJnd9caxUW35uUxo/image.png)]](https://img-blog.csdnimg.cn/e99c79cc8fcf4fd581ed00abb7d91e6f.png)
采用随机抽样的方法效果最好。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8qyF6abO-1653056252770)(https://secure2.wostatic.cn/static/4HMs4uzA7D9nyEpAdufQs5/image.png)]](https://img-blog.csdnimg.cn/c197b9346b6d4861879dd71bc7efbc4e.png)
上图展示了epoch长度的影响。作者发现即使在1600epoch+之后也没有发现饱和的迹象,这与对比学习完全不同,MoCV3基于ViT-L 300个epoch之后就饱和了。MAE在75%的masking ratio下每个epoch其实只相当于见了25%的数据,而对比学习往往学习two-crop和multi-crop,每个epoch见到的数据在200%以上,这也意味着MAE可以训练更多的epoch。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gQKnJuiq-1653056252770)(https://secure2.wostatic.cn/static/wcjUtm2d8SCowsjgnKtUcd/image.png)]](https://img-blog.csdnimg.cn/09c0e016316a445f84e4d26c07fcbba0.png)
MAE与其它无监督方法的对比,可以看到在同样条件下MAE要比BEiT更好,而且也超过有监督训练,其中ViT-H在448大小finetune后在ImageNet上达到了87.8%的top1 acc。不过MAE的效果还是比谷歌采用JFT300M训练的ViT要差一些,这说明训练数据量可能是一个瓶颈。 在linear probing方面,MAE要比其它的MIMI方法要好很多,前面已经说过,这主要归功于encoder不处理mask tokens。
同时在table3中,MAE训练了1600epoch(图7),在128TPUV3上仅仅31hours,而同样的硬件,MoCoV3花费36 hours 仅仅训练了300 epochs。
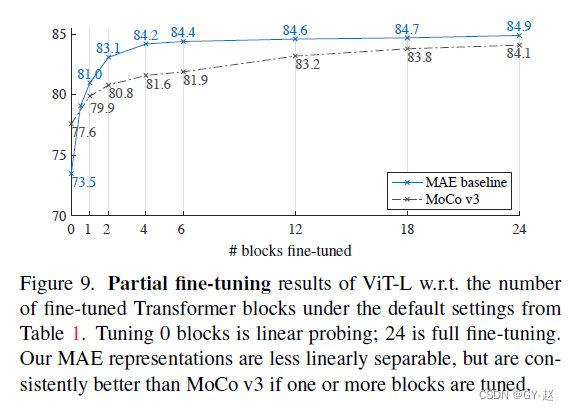
Figure9 展示了微调Transformer block 的结果,仅仅微调一个block,精度就可以从73.5提升到81.0.如果仅仅调整最后一个block的一半,也能得到79.1%,仍好于linear probing。
一些实现细节
- ViT encoder与decoder之间维度不匹配,使用一个线性映射调整维度
- 为了迎合ViT的设计,也增加了一个辅助训练的class token,用于分类器的训练,作者说实际上没有也可以很work,其实ViT论文中最后也提到,class token 与GAP两种方法用于分类都可以达到差不多的效果,只是需要的学习率不一样。
- 无论是encoder的输入还是decoder的输入都增加了positonal embeeding ,也就是使用了两次位置编码。
- 迁移学习主要使用encoder,后续也有论文(imted)使用了encoder-decoder结构。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









