







The k-means clustering algorithm
在聚类问题中,我们给定一组训练集{x(1), . . . , x(m)},要把这些数据归到几个内部联系紧密的簇(cluster)里,其中x(i)∈ Rn,但是并没有事先给出每个样本点的分类,所以这是一个非监督学习的问题。K-means聚类算法如下
1. 随机初始化聚类的质心(centroids) µ1, µ2, . . . , µk∈ Rn
2.重复下面的步骤直至收敛 {
对每个i,令


在上述算法中,k是我们想找到的簇的数量,质心µj 代表我们当前对每个簇的中心的估计值。在初始化(第一步中)时,我们可以随机选择k个训练样本作为质心。
在此算法的循环中有两个步骤: (i) 给每个样本分配到离它距离最短的质心µj所代表的簇。(ii)移动簇的质心,把新簇中所有成员的均值当做质心,赋值给µj。
图一展示了k-means演算的过程。
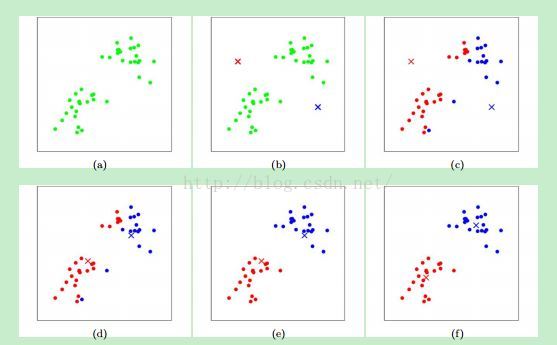
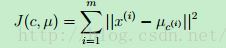
畸变方程J是一个非凸方程(?),所以J在下降过程中不能保证其能收敛到一个全局最优解。或者说,k-means得到的可以说是一个local的最优化。尽管如此,在通常情况下,k-means都能得到不错的结果。但是如果你担心你得到的局部最优解并不完美,一种通用的弥补颁发就是以不同的初值多运行几次k-means,然后从几个不同的聚类结果中找出一个畸变函数值最低的解。
以上是翻译内容,翻译内容来自Andrew Ng的机器学习笔记 CS229 Lecture Notes
以下是我自己的一些理解:
对于收敛性,我的理解是在这个聚类问题中,其实和畸变函数单调下降的性质是等价的。因为畸变函数值显然有0这个下界。所以只要单调下降,必然能保证收敛到一个范围或者在一个允许范围内波动,这只是我的一个直观感觉,我并没有找到有关收敛的严格证明。
对于全局最优解和局部解以及几组解间震荡的问题,我的一个想法是这可能代表聚类个数的选择上有问题,假设样本点是二维的,在图像上组成了两个全等不相交圆,只要样本个数与位置恰好处在某个范围内,那么显然当k为3时就会出现两个J值相等但聚类结果不等的情况。同样,找到特殊的个例是很容易的,但怎么严格阐述并证明这个问题,我并没有找到答案。
另外,关于能否找到最优解的问题,我在stackoverflow上看到一篇很好的回答,转载如下:
First, there are at most kN ways to partition N data points into k clusters; each such partition can be called a "clustering". This is a large but finite number. For each iteration of the algorithm, we produce a new clustering based only on the old clustering. Notice therefore that if the old cluster is the same as the new, then the next clustering will again be the same. Also notice that if the new clustering is different from the old then the newer one has a lower cost. Also notice that since the algorithm iterates a function over a finite set, the iteration must eventually enter a cycle. The cycle can not have length greater than 1 because then otherwise you would have some clustering which has a lower cost than itself which is impossible. Hence the cycle must have length exactly 1 . Hence k-means converges in a finite number of iterations.
原文链接:http://stats.stackexchange.com/questions/188087/proof-of-convergence-of-k-means
对于循环中两个修正过程的问题,我觉得这本质上就是不断求一个参数对另一个的条件期望的问题。而最有意思的一点是尽管迭代是一步一步进行的,但整个过程中可用到的信息总量是不变的,迭代的过程仿佛是对样本信息的挖掘过程。














 7097
7097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









