






Deep Algorithm Unrolling for Blind Image Deblurring
https://blog.csdn.net/qq_38235017/article/details/109909258
这是一篇CVPR2020的去模糊论文,主要是通过传统与深度相结合,将迭代次数变成神经网络的层数,使网络结构的网络结构更加具有解释性。
主要贡献:
Deep Unrolling for Blind Image Deblurring (DUBLID):提出一种可解释的神经网络结构叫做DUBLID,首先提出一种迭代算法,该算法被认为是梯度域中传统的广义全变分正则方法(generalized TV-regularized algorithm)的推广。
算法步骤的每次迭代都表示为网络的一层,连接这些层形成一个深层神经网络。通过网络相当于执行有限次数的迭代算法。此外,算法参数(例如模型参数和正则化系数)转移到网络参数。可以使用反向传播来训练网络,从而产生从真实世界训练集中学习的模型参数。这样,训练后的网络可以自然地解释为参数优化算法,有效地克服了大多数传统神经网络缺乏可解释性的问题。传统的迭代算法与流行的神经网络相比通常需要的参数更少。因此,展开的网络具有很高的参数效率,并且需要较少的训练数据。此外,展开的网络自然继承了先前的结构和领域知识,而不是从密集的训练数据中学习它们。因此,它们倾向于比一般网络更好地推广,并且只要每次算法迭代(或相应的层)不太昂贵,计算速度就会更快。
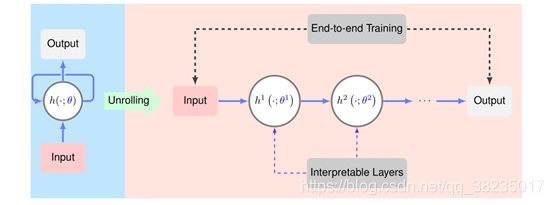
算法展开的概述:给定迭代算法(左),可以通过级联其迭代h来生成相应的深层网络(右)。迭代步骤h(左)被执行多次,生成网络层h1、h2…(右)。每次迭代h取决于算法参数θ,这些参数被转换成网络参数θ1、θ2...我们学习θ1、θ2…,而不是通过交叉验证或分析推导来确定这些参数,从训练数据集到端到端训练。这样,最终得到的网络可以获得比原始迭代算法更好的性能。
网络结构如下图:
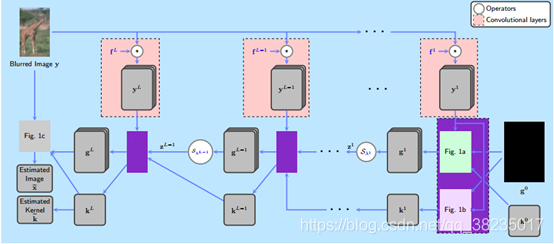
半二次分裂方法(HQS):一般是将正则项中的原始变量进行变量替换,然后增加拉格朗日乘子项和二次惩罚项,这么做的目的是,去耦合的同时,简化计算。
基于半二次分裂方法(HQS)解决梯度域去模糊,开发了一个新的迭代优化展开算法。
线性核训练数据集:Berkeley Segmentation Data Set 500 (BSDS500)【是一个边缘检测数据集】
非线性核数据集:Microsoft COCO dataset 【是一个物体检测、分割和字幕数据集】
使用级联3×3小滤波器代替大滤波器,降低了参数的维度,并且网络可以更容易训练,
模糊的图像是通过将清晰的图像与模糊内核进行卷积合成,还添加了高斯白噪声(标准差为0.01)
这个方法用在作者自己所创造的数据集里效果还不错,但是真实的模糊图像不会这么简单,作者也提出在GO_PRO训练集中效果不是很好,代码还未开源。















 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









