







- 论文题目: Mastering Complex Controlin MOBA Games with DeepReinforcement Learning

主要贡献
提出了一个深度强化学习框架,从系统和算法的角度来解决这个问题。提出的算法包括几种新颖的策略,包括control dependency decoupling,action mask,target action和dual-clip PPO,借助这些策略,可以在系统中有效地训练提出的actor-critic网络。经过MOBA游戏《王者荣耀》的测试,训练有素的AI agent可以在完整的1v1游戏中击败顶尖的职业人类玩家。
系统架构
考虑到复杂的Agent控制问题可能会引入随机梯度的高方差问题,在王者荣耀1V1中,大的batch size可以加速训练,所以文章所采用的强化学习架构由四部分构成:
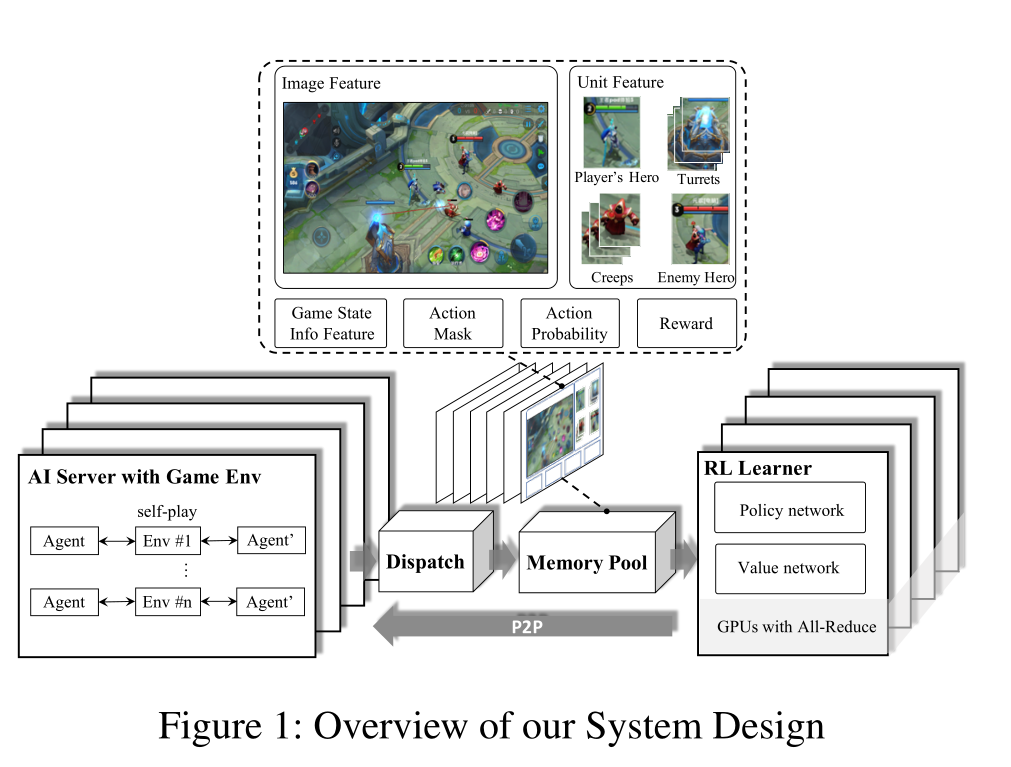
-
RL Learner:是一个分布式训练环境,并行从pool采样得到梯度,同步全部梯度取均值,更新策略后将策略传给AI Server。
-
AI Server:涵盖了游戏环境和AI之间的交互逻辑,用来产生数据。即从游戏中收集state,预测英雄行为。在使用中,一台AI服务器绑定一个cpu内核。我们构建了快速推断库FeatherCNN,以来更有效的生成推断模型。开源地址:https://github.com/Tencent/FeatherCNN
-
Dispatch Module:从多个AI server搜集数据并压缩、打包奥、传送到Memory
-
Memory Pool:也是服务器。它的内部实现为内存高效的循环队列,用于数据存储。它支持各种长度的样本以及基于生成时间的数据样本
算法设计
Reinforcement Learning用的还是熟悉的actor-critic网络,具体如下图所示:
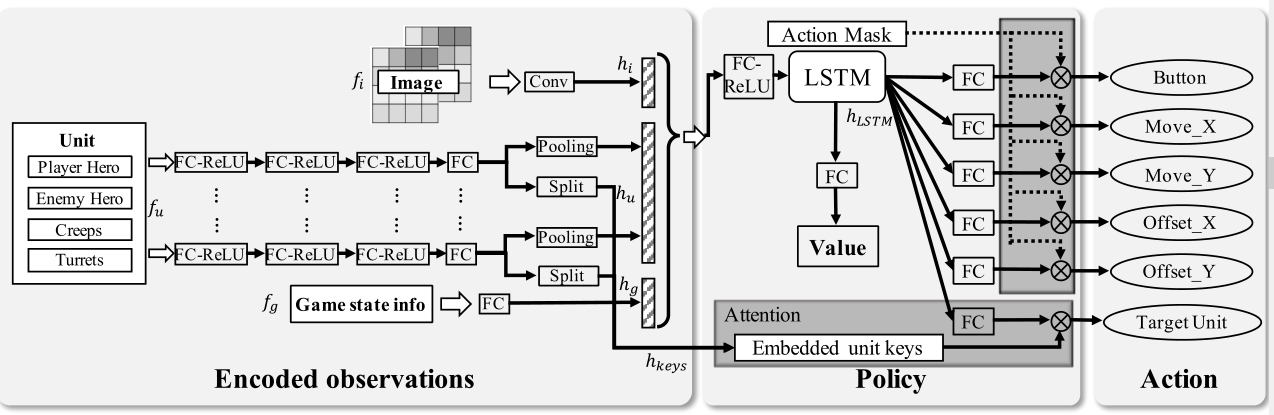
- 状态设计:如上图;将图像特征fi,向量特征fu和游戏状态信息fg(可观察到的游戏状态)分别通过卷积层、最大池化层和全连接层编码。LSTM输出动作按钮和移动方向。
- 动作解耦:认为动作之间独立,目标为最终几个策略累积奖励之和;
- 初始随机动作产生数据;
- action mask:根据专家经验去掉明显不合理、受限制的动作;
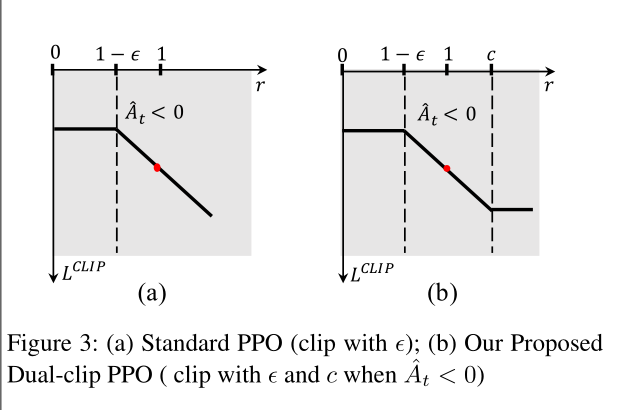
- dual-PPO:原始PPO在Advantage小于0的时候也容易产生大的策略梯度,作者改进了PPO,使其支持大范围的数据训练。
dual-PPO公式:
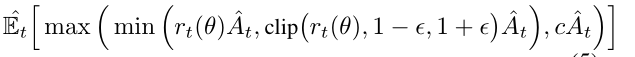
实验部分
实验运用了大量的CPU和GPU资源。框架运行在封装在Dockers和1,064个Nvidia GPU(Tesla P40和V100的混合物)中的总共600,000个CPU内核上。我们框架的数量允许并行实验。数据用float16存储,训练时转成float32。minibatch为4096。每个epoisode从游戏开始到结束。每天的数据量相当于人类玩500年的数据。PPO的eps=0.2,c=3,折扣因子是0.997,half-life大概46秒。GAE的lambda=0.97。游戏时按顶级玩家的133ms反应时间进行预测。训练时间跟Elo的曲线如下:
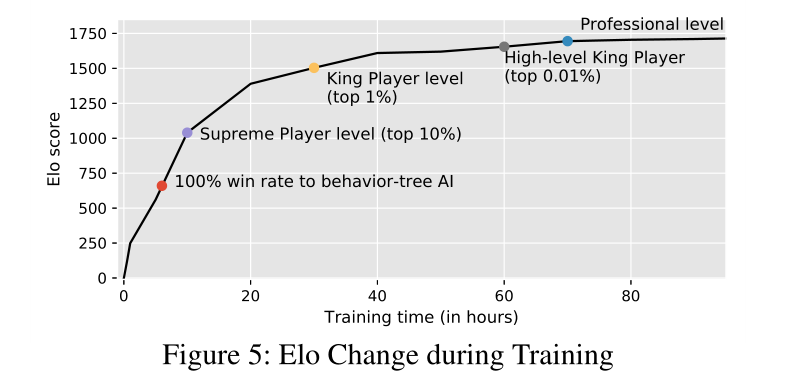
由上图可知训练6小时打败内置行为树,30小时达到top 1%人类水平,70小时达到专业水平。
我们训练的AI强化学习跟人类顶级玩家进行1v1的竞赛
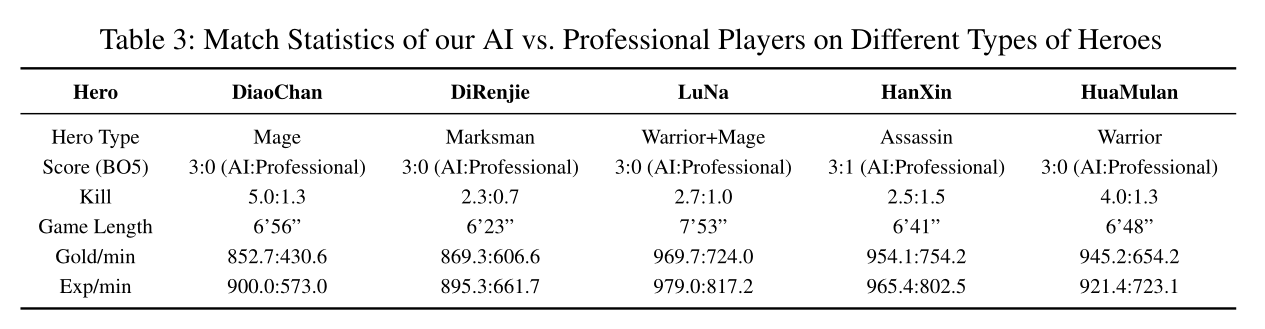
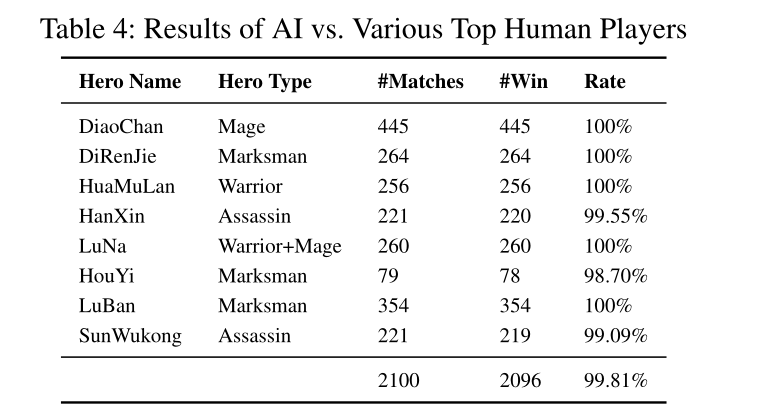
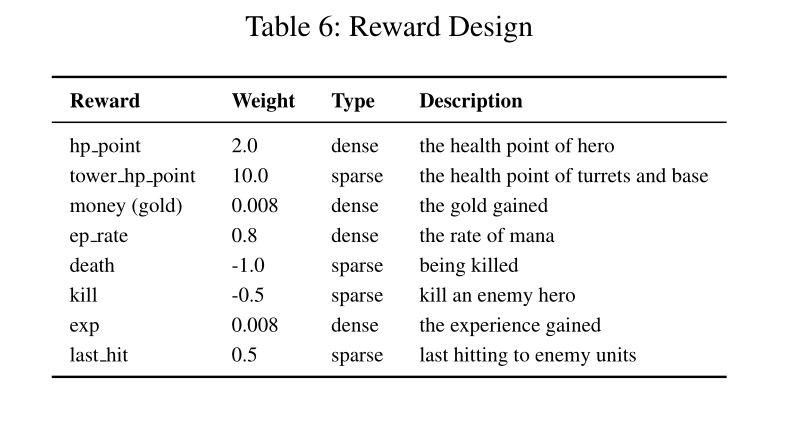
Reward设计


















 4194
4194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











