







介绍
英文题目:Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
中文题目:多门专家混合多任务学习中的任务关系建模
论文地址:https://dl.acm.org/doi/pdf/10.1145/3219819.3220007
领域:深度学习,多任务学习
发表时间:2018
作者:Jiaqi Ma,密歇根大学,谷歌
出处:KDD
被引量:137
代码和数据:https://github.com/drawbridge/keras-mmoe
阅读时间:22.07.24
读后感
多任务学习一般用于相同输入特征,用一个模型同时学习多个任务.一次预测多个标签,这样可以节约训练和预测时间,也能节约存储模型的空间.
之前的方法主要是底层共用网络,上层针对每个任务分别训练自己的网络.这样做的问题是,如果多个任务相关性不强,可能向不同方向拉扯共享参数,虽然理论上多个任务可以互为辅助,提供更多信息,但实现效果往往不如单独训练模型效果好.
介绍
多任务学习效果一般取决于不同任务之间的相关性.文中提出的MMoE(Multi-gate Mixture-of-Experts)是对之前方法MoE的改进.主要用于解决多任务相关性小时,同时优化多个目标的问题.比如同时预测用户是否购买及用户满意度.
在研究过程中,遇到的问题还有:如何衡量不同任务的相关性;如果不让模型由于多任务变得过大和过于复杂.
文章贡献
- 提出MMoE结构,构建了基于门控的上层网络,模型可自动调节网络参数.
- 设计了生成实验数据的方法,以便更好的衡量任务相关性对建模的影响
- 在实验数据集中实现了更好的效果,解决了现实世界中大规模数据训练问题
方法

之前的实现方法如图-1(a)所示,底层网络Shared Bottom共享参数,上层使用双塔或多塔结构以适配不同任务:

其中k是具体任务,f(x)是底层模型,hk是上层模型.
进而是如图-1(b)所示的MoE模型(在后续的实验中也记作OMoE),它使用多个专家网络作为底层,利用输入计算门控值用于设置各个专家贡献的占比,然后将计算出的结果送入上层网络.
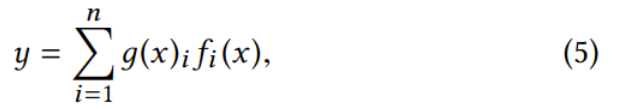
其中g是门控,n是专家的各数,公式结合了各个专家的结果.对于每个实体,只有部分网络被激活.
图-1©是本文提出的网络结构MMoE,与MoE不同的是它针对不同的任务计算不同的门控分别设置专家占比.
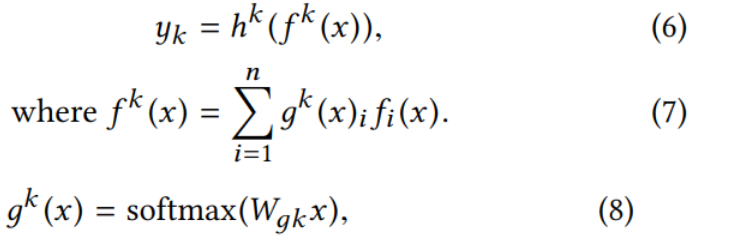
其中的 Wgk 是可训练的矩阵,用于根据输入选择专家.
每个门控网络线性地将输入空间分割成n个区域,每个区域对应一个专家。MMoE决定不同门控制管理的区域如何相互重叠。如果某区域与任务的相关性较低,那么共享专家将受到惩罚,任务的门控网络将学会使用不同的专家。
实验
合成数据实验
合成数据能更好的对比不同任务相关性的影响,利用合成数据的实验对比如图-4所示:
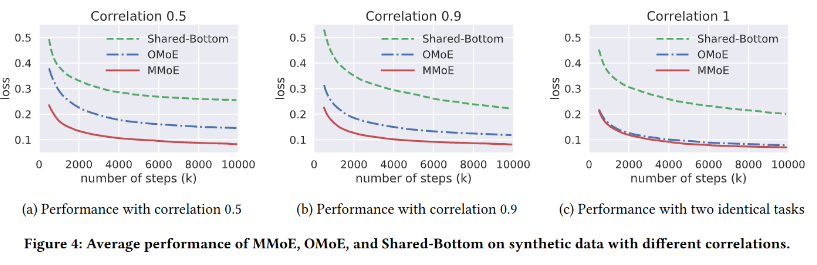
- 对于所有模型,相关度高的任务训练效果都更好
- 在不同相关度的情况下,MMoE都好于OMoE和Shared-Bottom模型.而在相关性一致的情况下,MMoE和OMoE结果几乎一致
- 基于MoE的两个模型效果都明显好于Shared-Bottom,且收敛更快,这说明MoE结构使模型更好训练.
真实数据实验
人口收入数据
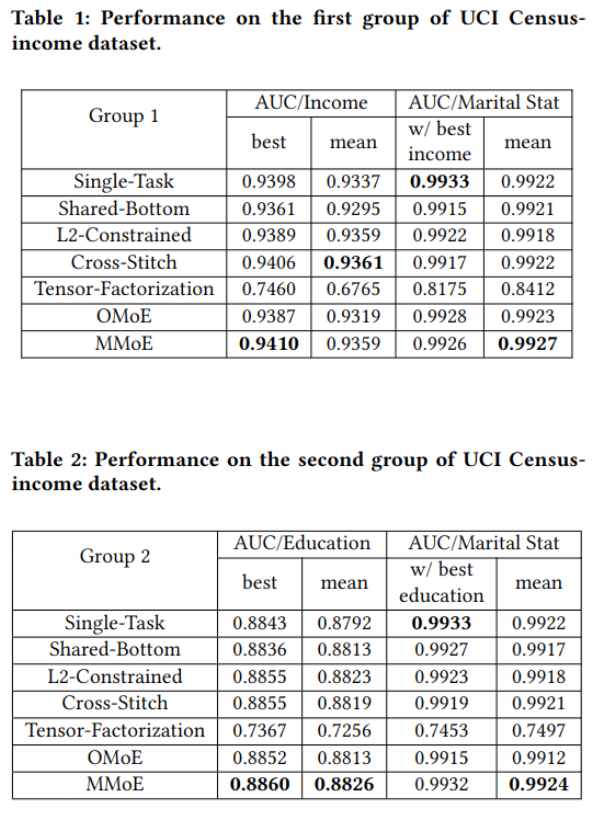
使用人口收入数据,分别进行两组实验,第一组同时训练两个任务:训练收入是否超过50K和婚否;第二组同时训练教育程度和婚否.训练数据199523.训练结果如下:
大规模的内容推荐
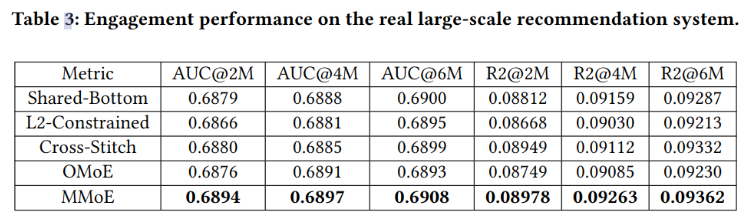
利用谷歌数以亿计的推荐数据训练.目的是同时优化:与粘性相关的目标,如点击率和粘性时间;以及与满意度相关的目标.具体评价标准使用AUC和R-Squared scores.效果如表-3所示:
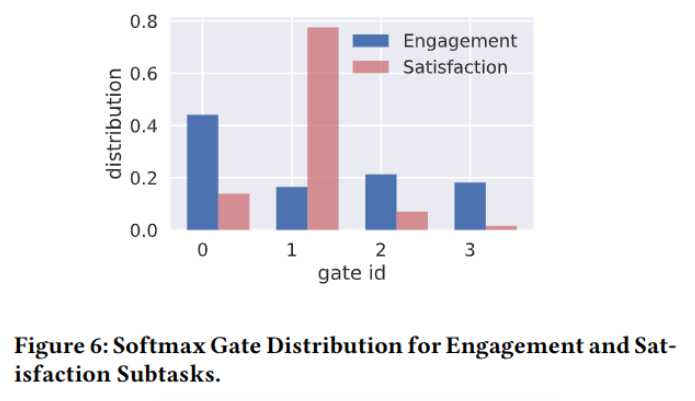
从图-6中可以看到不同专家对不同任务的贡献:















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









