







参考资料:
b站黑狗木视频教程
邓侃-lerobot知乎专栏
1、 仿真
部分安装需要conda换源,可参考如下,可走国内代理镜像源
# 查看当前的源
conda config --show channels
# 填加源
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
# 添加显示源
conda config --set show_channel_urls yes
# 恢复默认源
conda config --remove channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --remove channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --remove channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
conda config --remove channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
conda config --remove channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
然后安按照github的教程,pip 安装如果很慢原因是 linux下终端 ping外面的网址是Ping不通,需要自己科学上网解决或者pip走清华镜像源安装,本人使用的TUN模式,解决linux客户端访问问题。
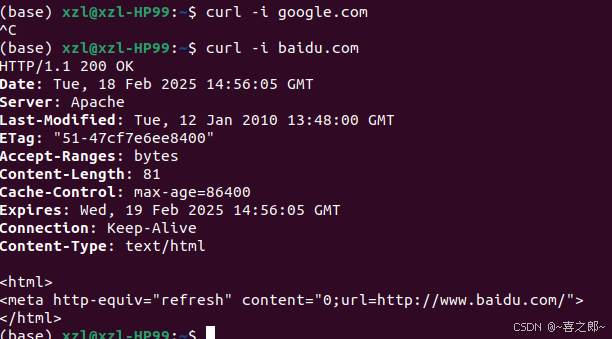
按照github体验第一版数据集
# 推方块仿真
python lerobot/scripts/visualize_dataset.py \
--repo-id lerobot/pusht \
--episode-index 0
# 装咖啡仿真
python lerobot/scripts/visualize_dataset.py \
--repo-id lerobot/aloha_static_coffee \
--episode-index 0
下载后运行数据集可视化的情况见本人b站:
2、 机械臂装配
本人直接买的淘宝机械臂,装配好,如果,需要手动买舵机和3d打印件,可见黑狗木教程2-7集
3、 机械臂遥操
3.1 舵机设置
首先寻找到主臂和从臂的端口,然后按照github上面教程修改配置文件
注意要先连接主臂,后链接从臂,不然输出会想我这样是反的
从机械臂设置 /dev/ttyACM0

主机械臂 /dev/ttyACM1
 赋予执行权限
赋予执行权限

修改配置文件
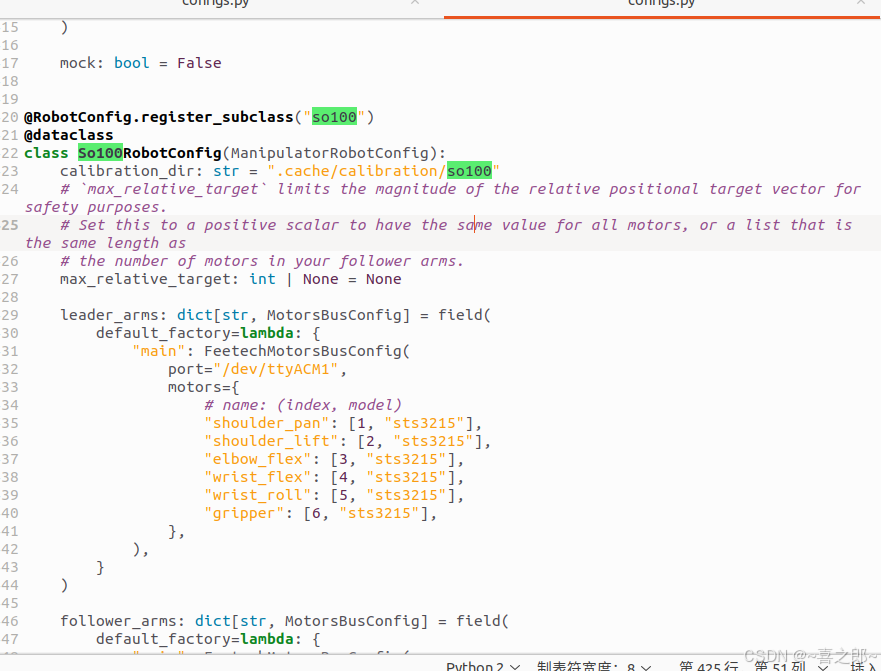 然后参考github对机械臂主从臂 共6个位姿的机械臂校准,我这里淘宝卖家已经给提前校准好了,所以可以略过。
然后参考github对机械臂主从臂 共6个位姿的机械臂校准,我这里淘宝卖家已经给提前校准好了,所以可以略过。
注意:如果使用商家的标定代码进行下一步的遥操作经常爆如下的错,则自己重新下载github程序标定
3.2 机械臂遥操作
# 运行如下的代码进行遥操作即可
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--robot.cameras='{}' \
--control.type=teleoperate
效果如下,本人b站录制:
3.3 配置相机,进行带相机遥操作
直接运行如下的代码会报错,如下
# 运行如下的代码进行遥操作即可
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=teleoperate
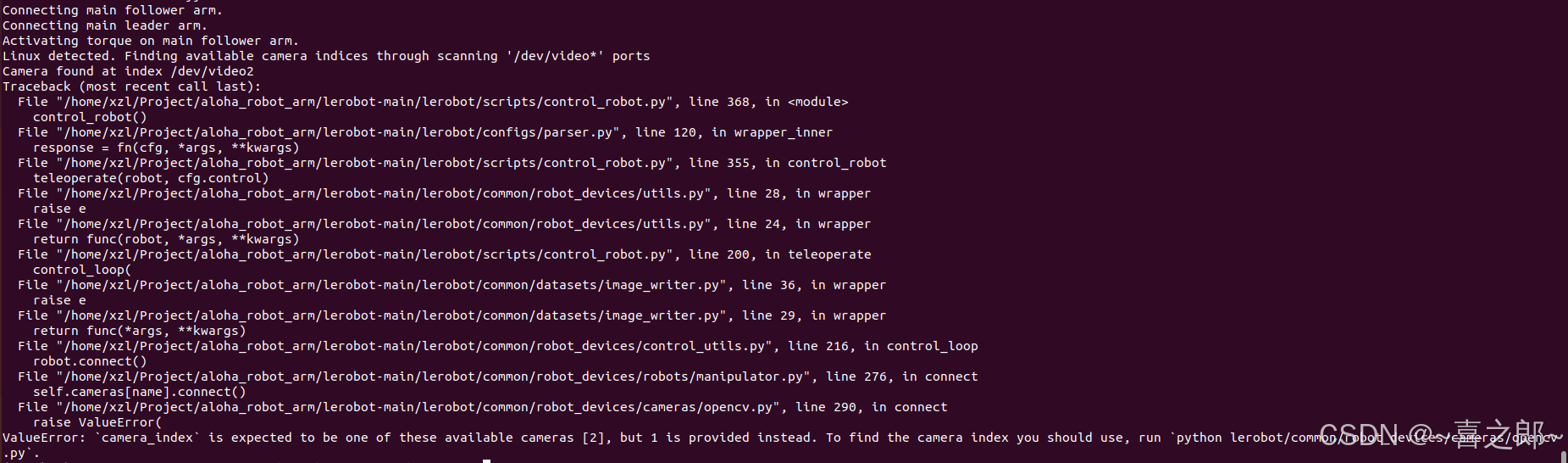
Deepseek 解决方案:
从错误信息来看,问题出在摄像头索引(camera_index)配置不正确。程序检测到可用的摄像头索引是 2,但配置中提供的索引是 1,导致无法连接摄像头。以下是解决这个问题的步骤:
解决方法
1. 检查摄像头索引
- 运行以下命令,查找当前系统中可用的摄像头索引:
python lerobot/common/robot_devices/cameras/opencv.py - 这将列出所有可用的摄像头索引,例如:
Available camera indices: [0, 2]
2. 更新配置文件
- 打开配置文件(通常是
configs/control_robot.yaml或类似的 YAML 文件)。 - 找到
camera_index参数,将其值更新为检测到的可用摄像头索引(例如2)。 - 示例:
camera_index: 2
3. 检查摄像头连接
- 确保摄像头已正确连接到计算机。
- 如果摄像头是 USB 摄像头,尝试重新插拔 USB 线缆。
- 使用以下命令检查摄像头是否被系统识别:
ls /dev/video* - 确保
/dev/video2存在(或其他检测到的索引)。
4. 测试摄像头
- 使用
OpenCV测试摄像头是否正常工作。运行以下 Python 脚本:import cv2 cap = cv2.VideoCapture(2) # 替换为检测到的摄像头索引 if not cap.isOpened(): print("Error: Could not open camera.") else: print("Camera is working.") ret, frame = cap.read() if ret: cv2.imshow("Frame", frame) cv2.waitKey(0) cap.release() cv2.destroyAllWindows() - 如果摄像头正常工作,会显示摄像头捕获的画面。
5. 检查权限问题
- 确保当前用户有权限访问摄像头设备。运行以下命令:
ls -l /dev/video2 - 如果权限不足,可以尝试以下方法:
- 将用户添加到
video组:sudo usermod -aG video $USER - 重新登录系统以应用组更改。
- 如果问题仍然存在,可以临时更改设备权限:
sudo chmod 666 /dev/video2
- 将用户添加到
6. 检查摄像头驱动
- 确保摄像头驱动程序已正确安装。
- 如果摄像头无法正常工作,尝试更新或重新安装驱动程序。
7. 联系支持
- 如果以上方法都无法解决问题,建议联系设备的支持团队或开发者,提供详细的错误日志和设备信息,以获取进一步的帮助。
总结
- 检查摄像头索引:运行
python lerobot/common/robot_devices/cameras/opencv.py查找可用索引。 - 更新配置文件:将
camera_index更新为正确的值。 - 检查摄像头连接:确保摄像头已正确连接并被系统识别。
- 测试摄像头:使用
OpenCV测试摄像头是否正常工作。 - 检查权限问题:确保当前用户有权限访问摄像头设备。
- 检查摄像头驱动:确保驱动程序已正确安装。
- 联系支持:如果问题仍未解决,联系设备支持团队。
我发现自己的原因便是port端口不对,如下的端口需要改成和opencv检测程序一样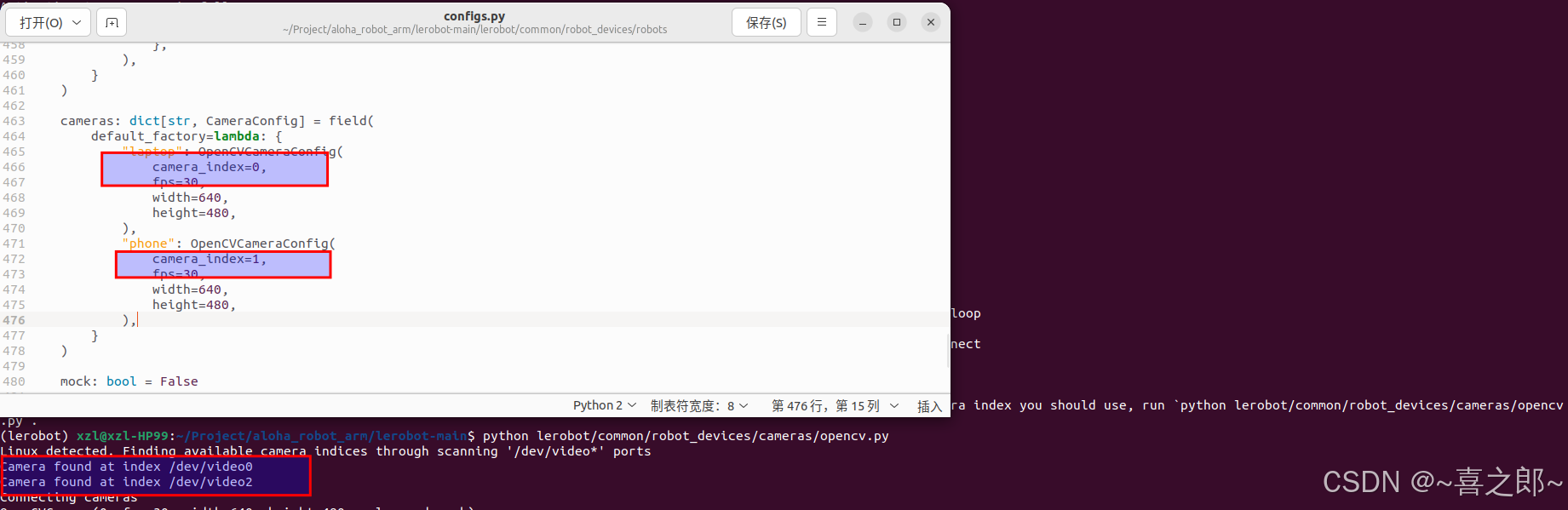 上面解决之后,继续运行之后继续报错,卡着不动,原因
上面解决之后,继续运行之后继续报错,卡着不动,原因
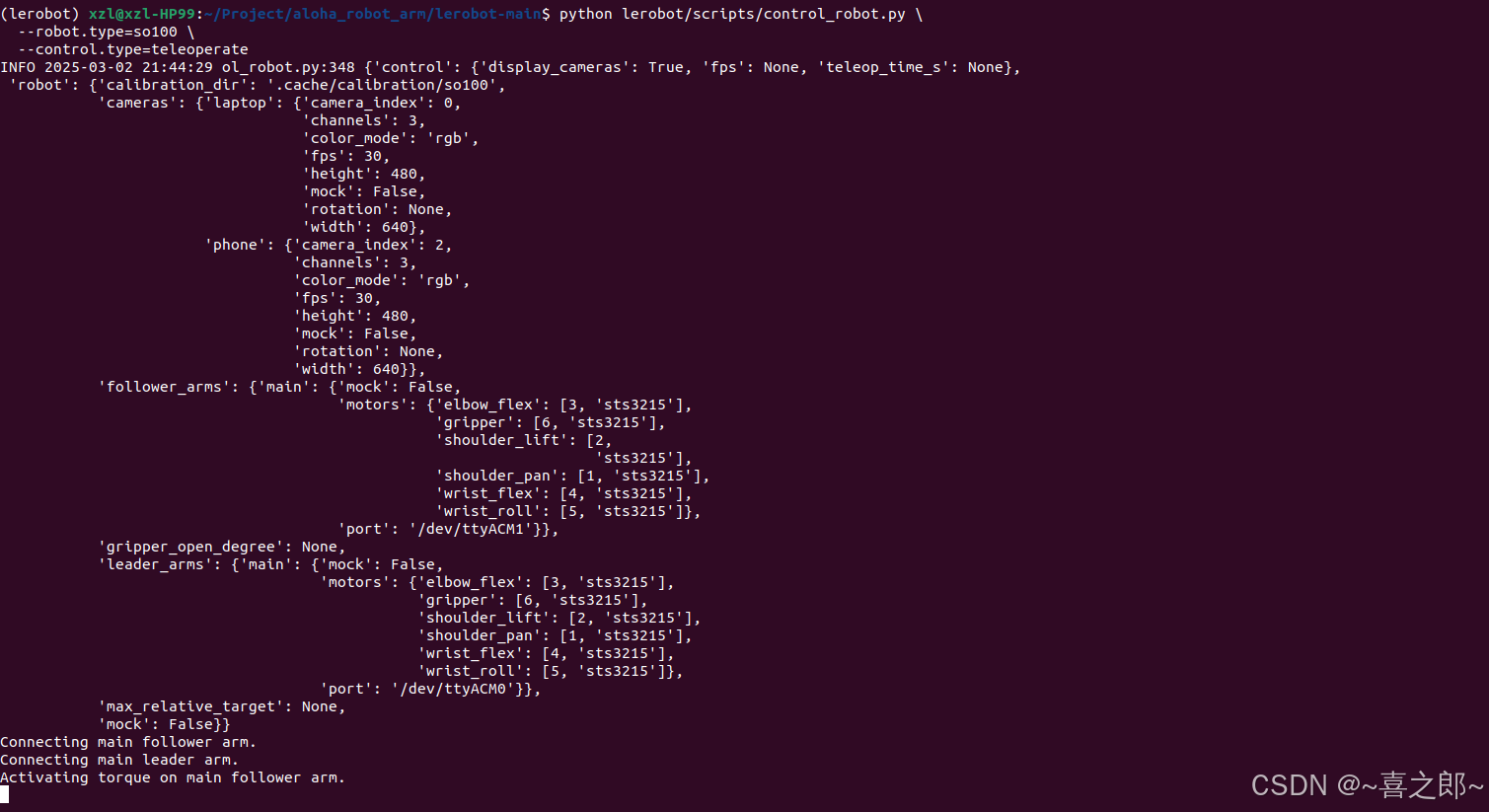 最后一行行debug了下,是这里的原因
最后一行行debug了下,是这里的原因
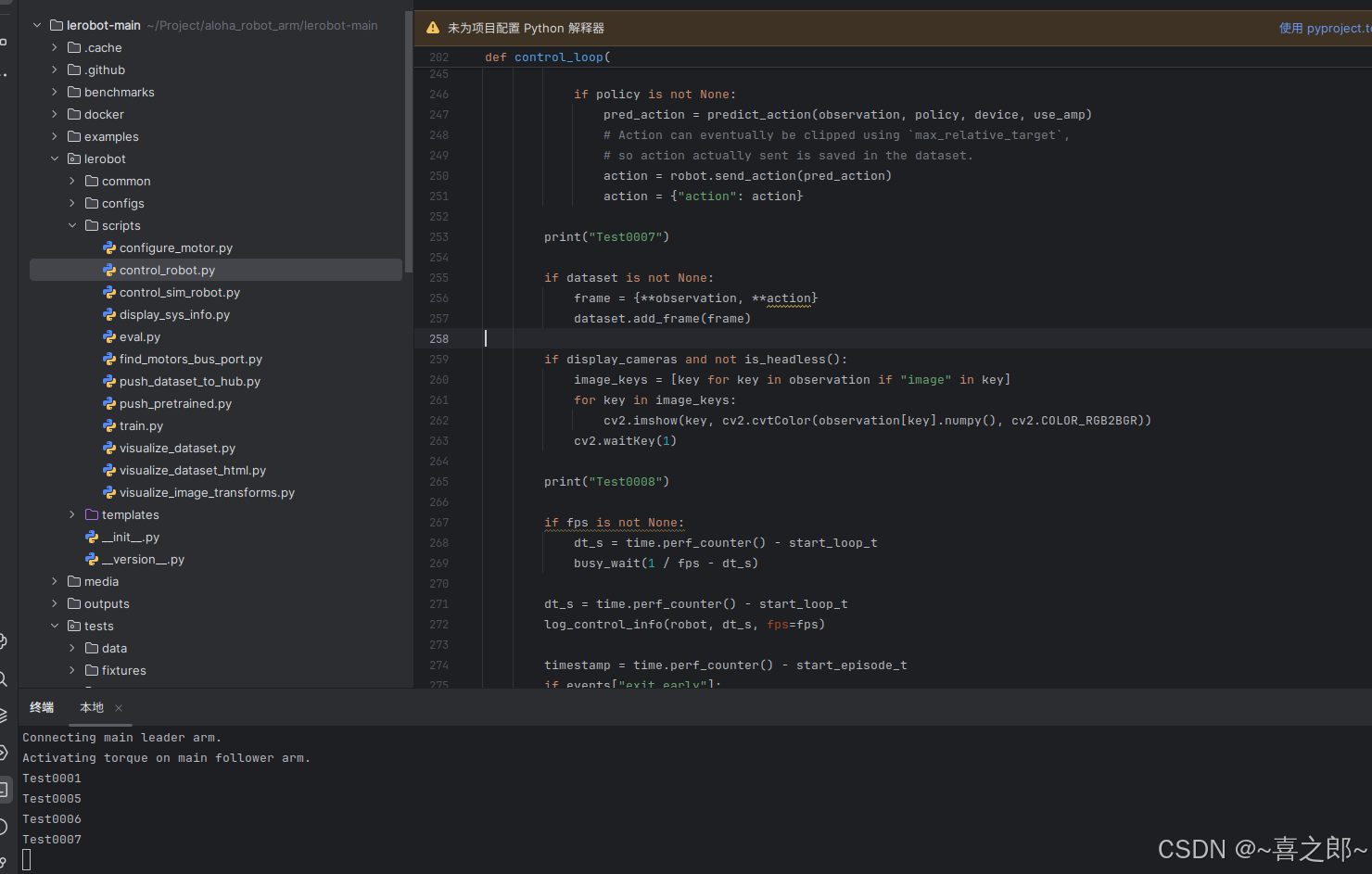
github找到2个相关的问题
问题1
问题2
解决之后,运行继续报错
 找到一个github类似问题
找到一个github类似问题
问题3
上述都解决之后,重新运行代码,效果见本人b站录制的视频
4 录制数据集
根据github 官方推荐的来搞,此方法需要科学上网,网络要好,但是遇到如下几个报错
如下encoder不对
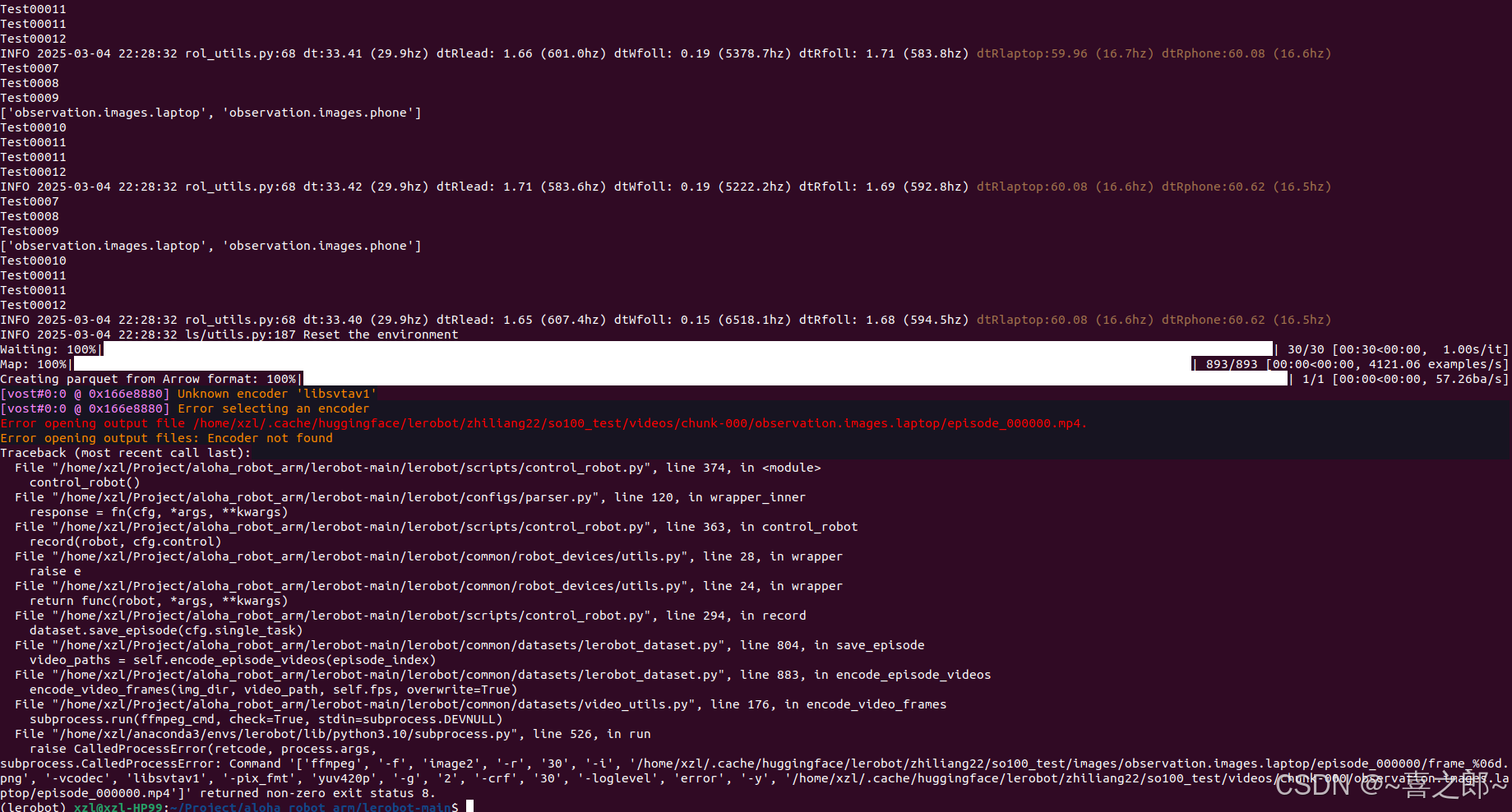 在github找到类似问题
在github找到类似问题
问题
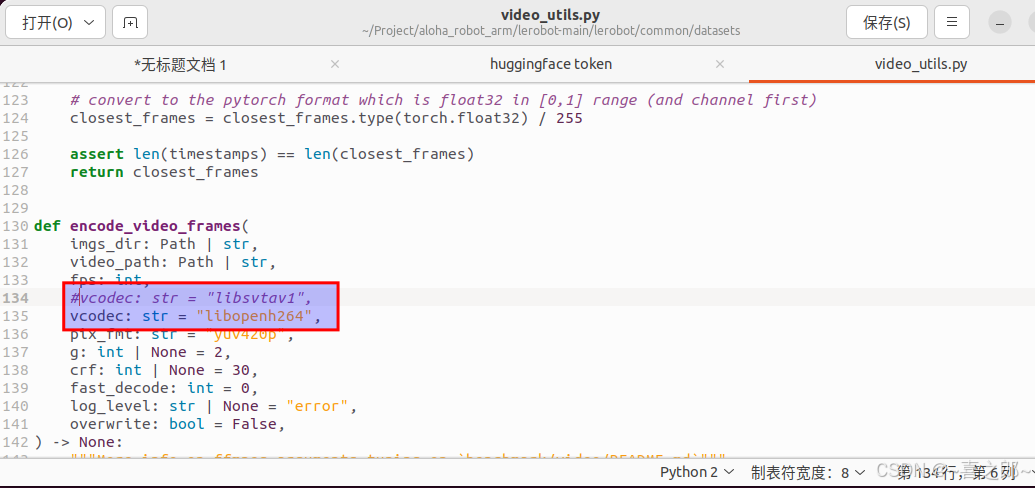
解决方式:
查看自己conda环境里面的如下软件版本号 修改成支持的encoder,重新录制即可
修改成支持的encoder,重新录制即可
如果没问题的话,会直接存到云端hugging face,但是我这边试了经常报错,传不到云端,但是新版不用担心,会在本地.cahe/huggingface里面备份一份,我们手动导入huggingface就行 注意如果上述在线上传Huggingface不行的话,我们就用,本地录制的方法,第一次录制,如下即可,num_episodes代表此次录制想要录几集
注意如果上述在线上传Huggingface不行的话,我们就用,本地录制的方法,第一次录制,如下即可,num_episodes代表此次录制想要录几集
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=record \
--control.fps=30 \
--control.single_task="Grasp a lego block and put it in the bin." \
--control.repo_id=${HF_USER}/so100_test \
--control.tags='["so100","tutorial"]' \
--control.warmup_time_s=5 \
--control.episode_time_s=30 \
--control.reset_time_s=30 \
--control.num_episodes=1 \
--control.push_to_hub=false \
--control.local_files_only=true
下次想要继续补录几集,可以结尾加上consume
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=record \
--control.fps=30 \
--control.single_task="Grasp a lego block and put it in the bin." \
--control.repo_id=${HF_USER}/so100_test \
--control.tags='["so100","tutorial"]' \
--control.warmup_time_s=5 \
--control.episode_time_s=30 \
--control.reset_time_s=30 \
--control.num_episodes=1 \
--control.push_to_hub=false \
--control.local_files_only=true \
--control.resume=true
轨迹重放,不带摄像头,如下
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=replay \
--control.fps=30 \
--control.repo_id=zhiliang22/so100_test \
--control.episode=0 \
--robot.cameras='{}' \
--control.local_files_only=true
本地数据集可视化,例子如下
python lerobot/scripts/visualize_dataset_html.py \
--repo-id zhiliang22/so100_test \
--local-files-only 1
具体效果可见本人B站
5 GPU训练
方式一 云平台训练
GPU推荐直接租平台训练,很快,可租用多实例的
 我根据一些博主的视频教程,运行了他们推荐的代码,例如,如下, dataset为autodl 平台的本地路径,device设置为cuda,但是发现,运行了之后,直接报错,大概率是github lerobot的main分支,又变动了,基本2-3星期变一次(会经常导致旧版的参数无法用)
我根据一些博主的视频教程,运行了他们推荐的代码,例如,如下, dataset为autodl 平台的本地路径,device设置为cuda,但是发现,运行了之后,直接报错,大概率是github lerobot的main分支,又变动了,基本2-3星期变一次(会经常导致旧版的参数无法用)
python lerobot/scripts/train.py \
--dataset.repo_id=/root/lerobot/data/zhiliang22/so100_test \
--policy.type=act \
--output_dir=outputs/train/act_so100_test \
--job_name=act_so100_test \
--wandb.enable=false \
--device=cuda
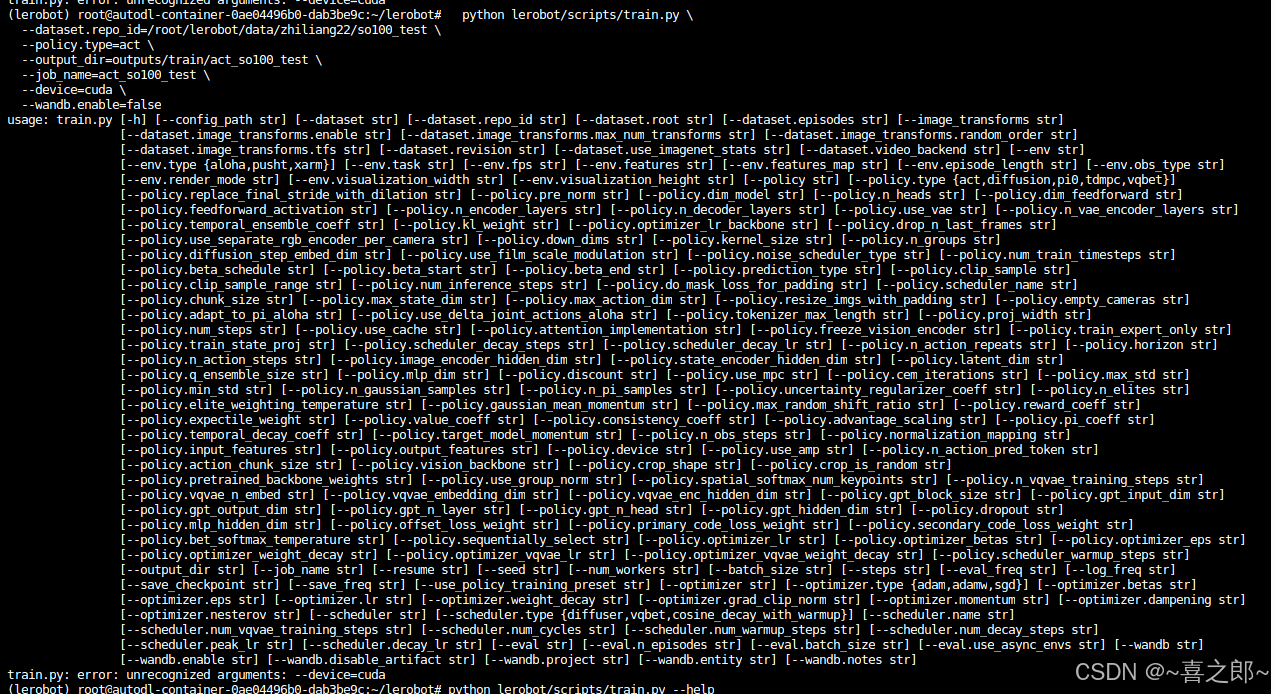
后来索性,直接将device 直接去除,尝试可行,新版最新的源码,如下使用会直接调用cuda
原因我在再train.py使用到的common包里面的get_safe_torch_device cuda设备下面打了一个debug的断点,然后autodl平台训练时候,日志输出的就是cuda调用,并且,训练时候梯度下降的速度正常。
python lerobot/scripts/train.py \
--dataset.repo_id=/root/lerobot/data/zhiliang22/so100_test \
--policy.type=act \
--output_dir=outputs/train/act_so100_test \
--job_name=act_so100_test \
--wandb.enable=false
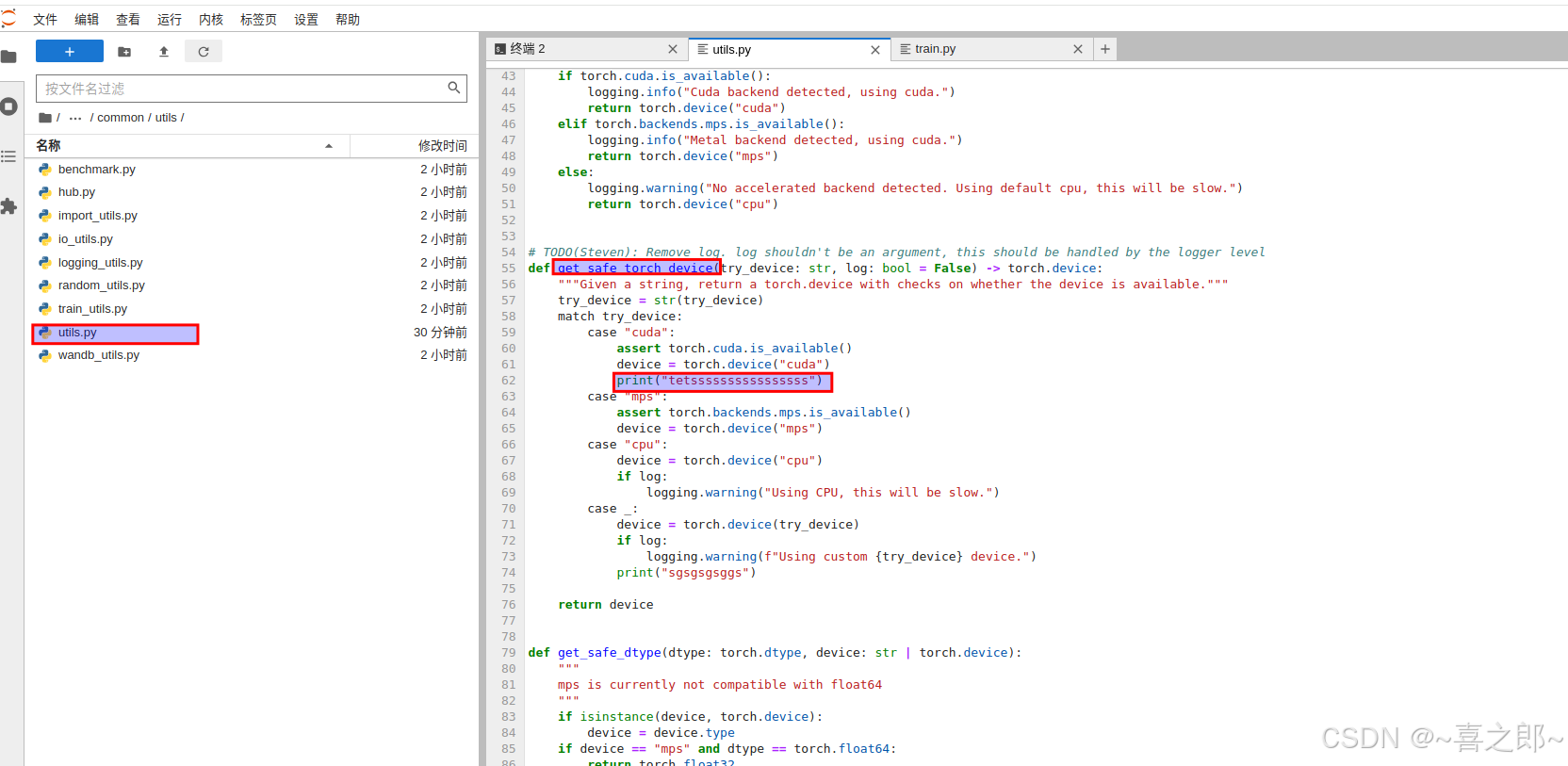

如下我添加额外打印日志正常打印,说明调用的就是cuda,然后梯度下降也正常说明训练正常。
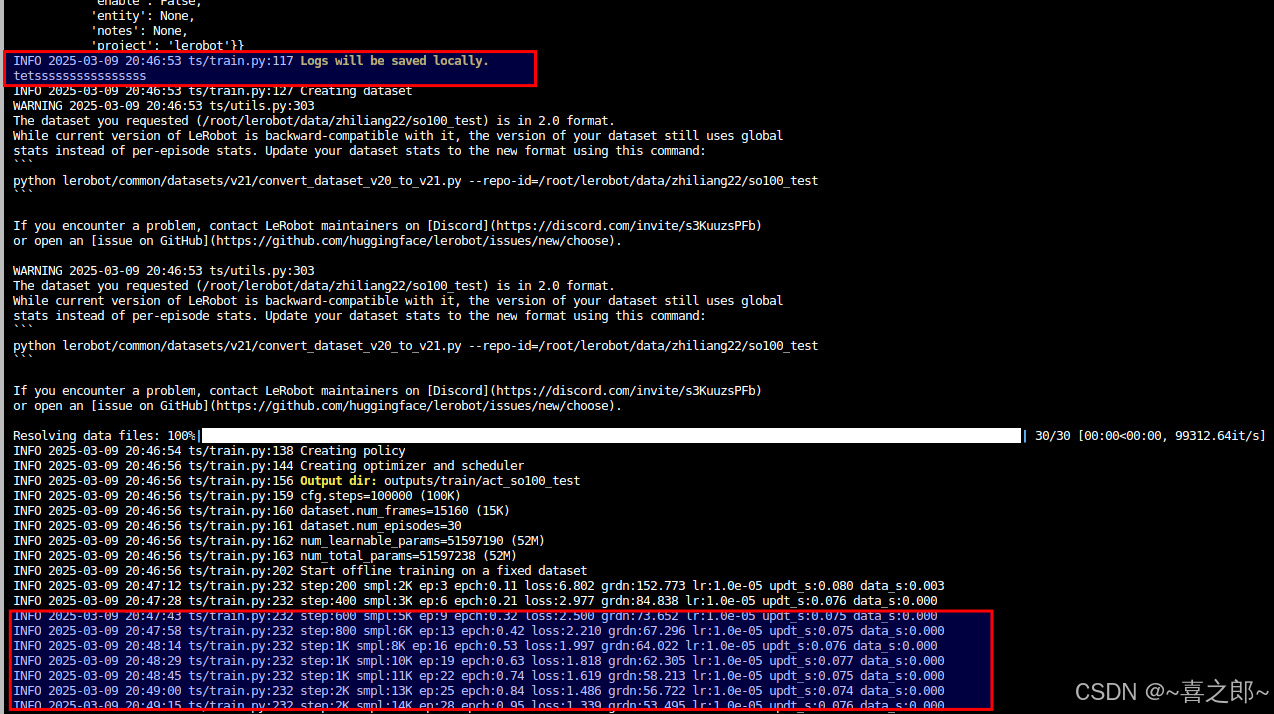
ps:另一种直接看实例的gpu使用情况,就知道cuda gpu正常训练了
方式二 本机显卡训练
这种显卡不行的话,训练很慢,也是如上面一样,本机有cuda,不需要设置cuda,直接调用本机的cuda
python lerobot/scripts/train.py \
--dataset.repo_id=zhiliang22/so100_test \
--policy.type=act \
--output_dir=outputs/train/act_so100_test \
--job_name=act_so100_test \
--wandb.enable=false
但是如上直接运行,会直接在如下代码处卡着不动
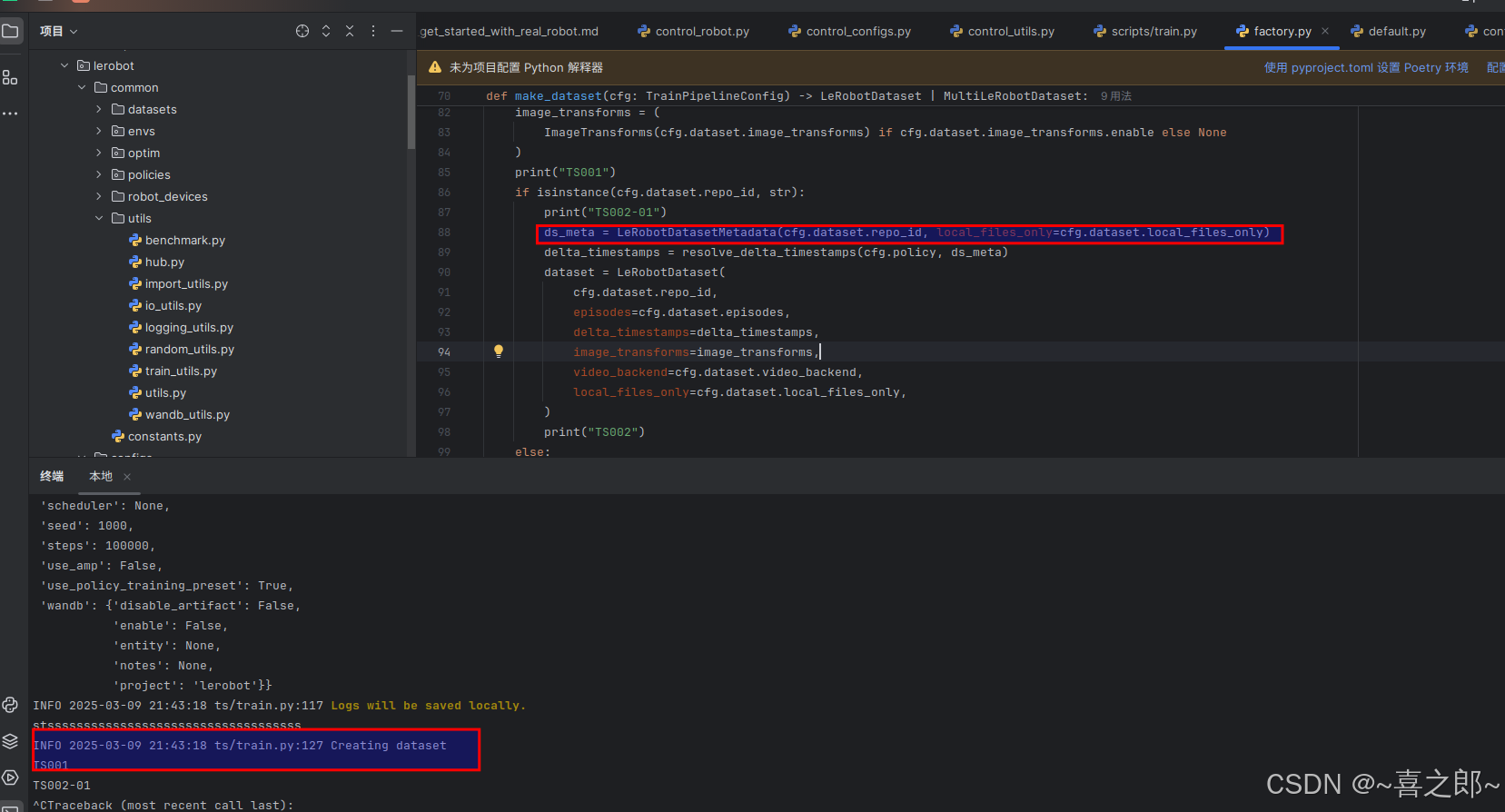 所以,本地训练如果用的源码版本和我一样,需要手动将如下改成True
所以,本地训练如果用的源码版本和我一样,需要手动将如下改成True
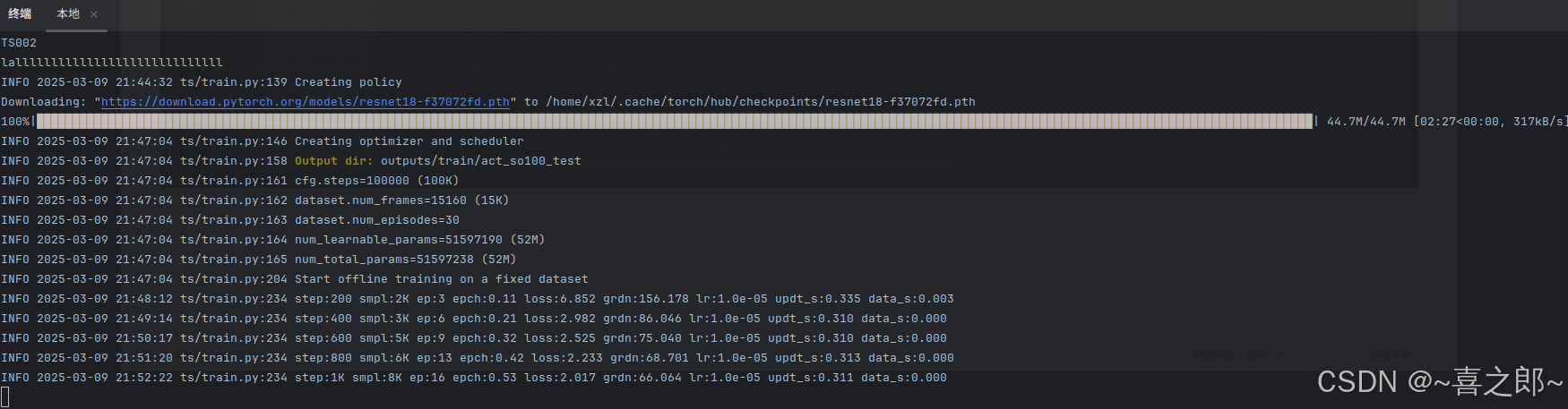
 如下,梯度下降了,代表本机在训练
如下,梯度下降了,代表本机在训练
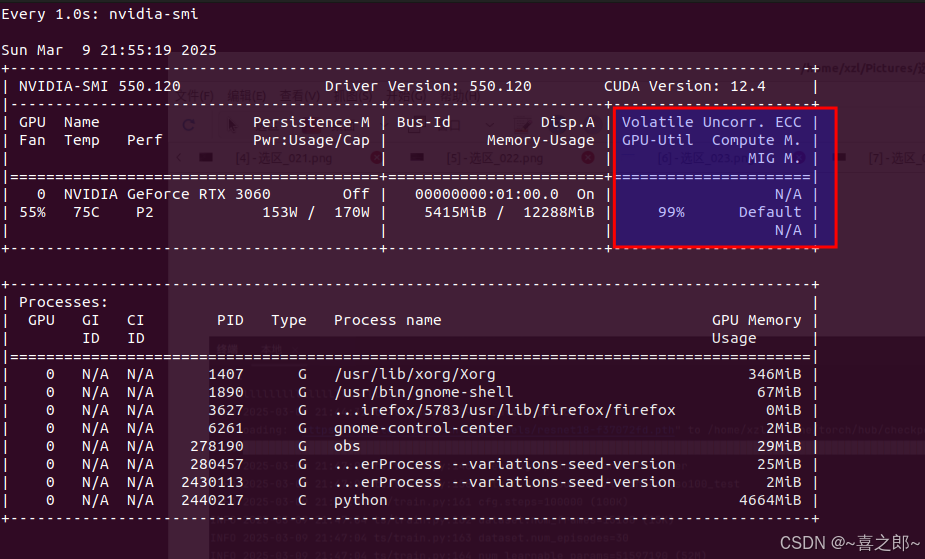
watch -n 1 nvidia-smi 命令看下发现gpu也在全速跑
6 数据集验证
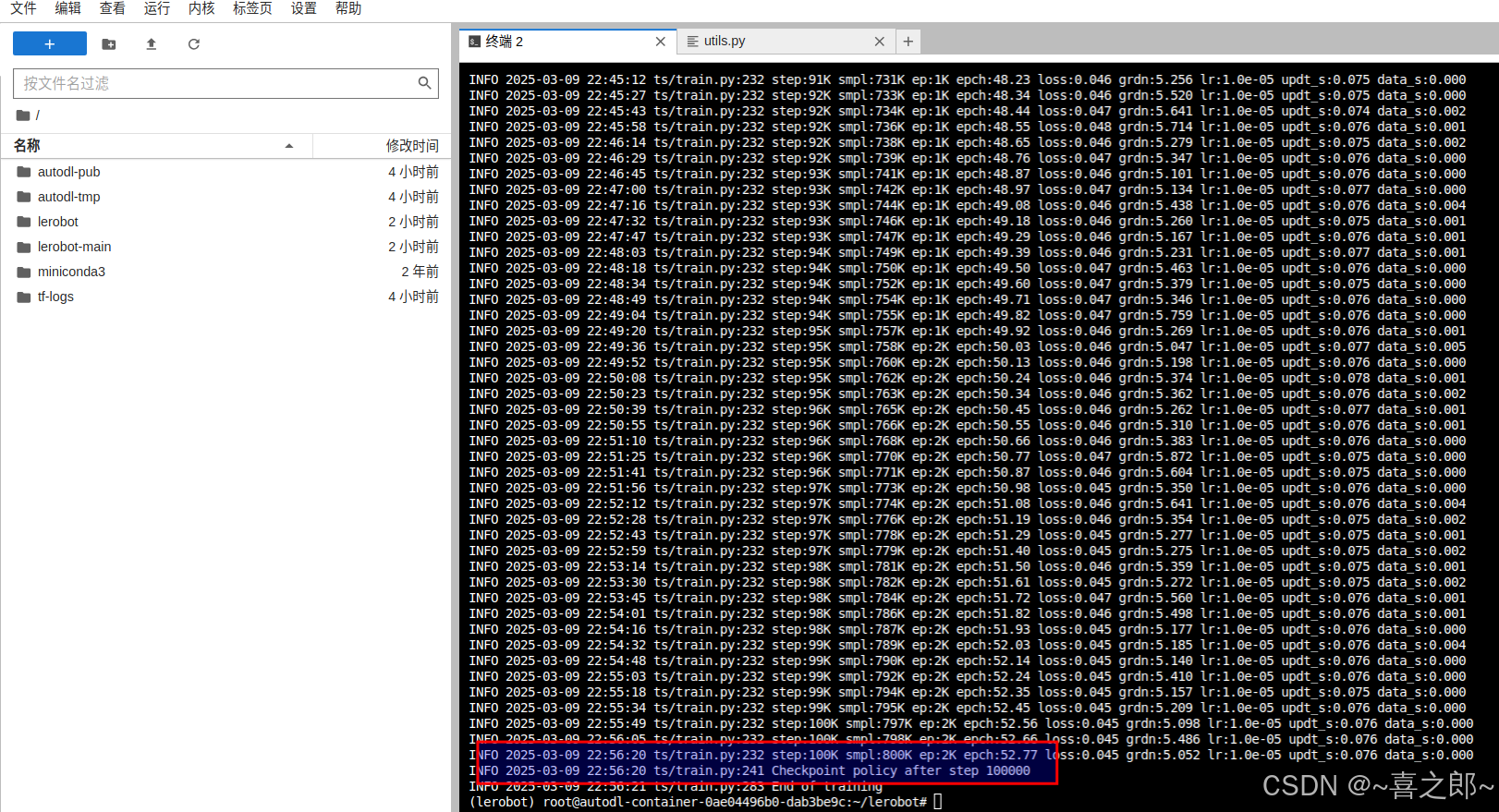
如上我使用云平台4090 30集数据集训练时长大约3h
 将训练好的last文件拷贝到本地电脑
将训练好的last文件拷贝到本地电脑
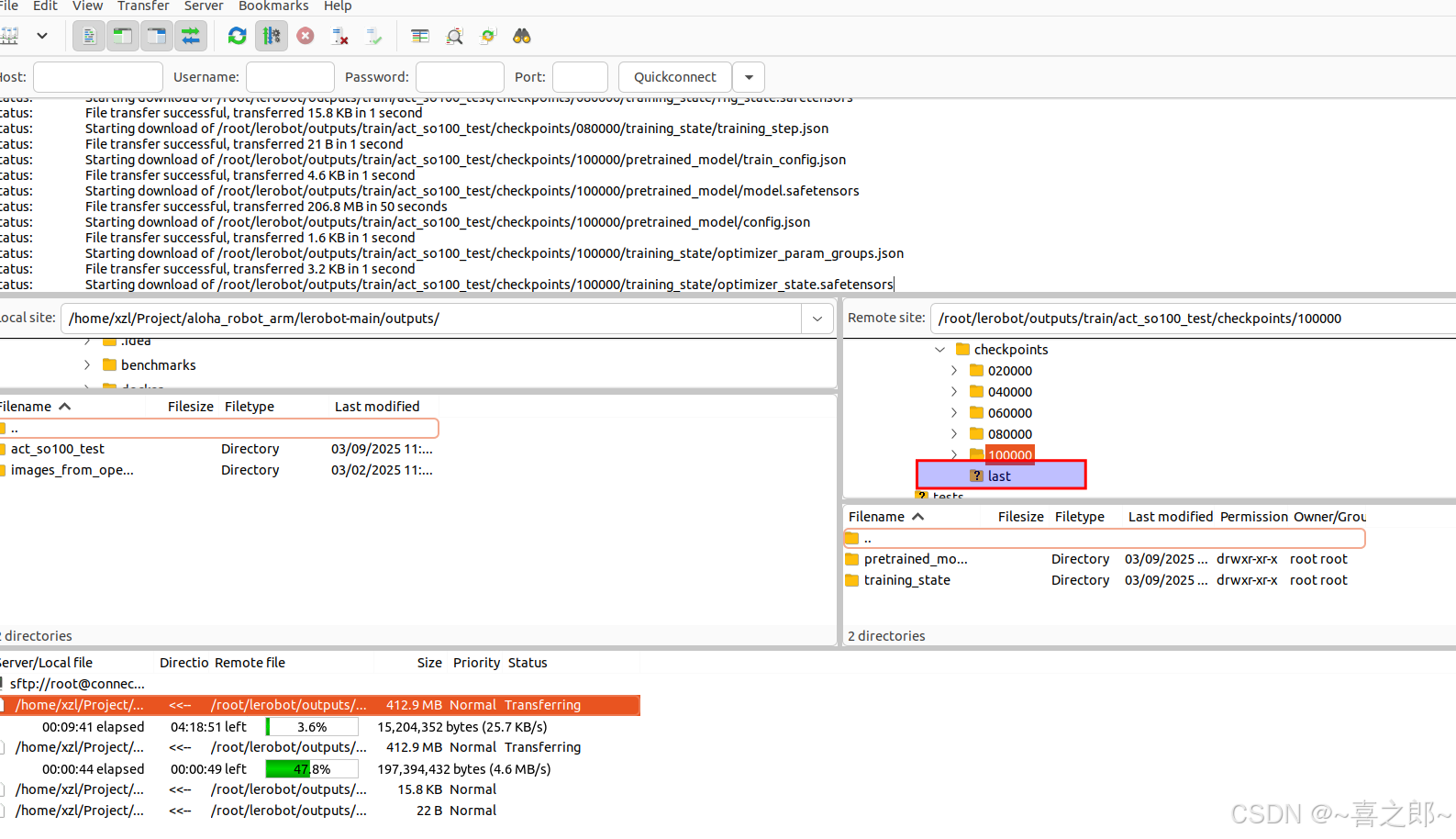
使用audodl平台下符号链接文件非常慢,从而下完100000/目录,后手动创建last符号链接
在当前目录下创建一个类似 last 的符号链接指向 100000/ 目录非常简单。你可以使用 ln 命令来创建符号链接。
创建符号链接的命令
运行以下命令:
ln -s 100000/ last
ln:创建链接的命令。-s:表示创建符号链接(软链接)。100000/:目标目录(符号链接指向的目录)。last:符号链接的名称。
验证符号链接
创建完成后,你可以通过以下命令验证符号链接是否正确:
ls -l
输出示例:
lrwxrwxrwx 1 user user 7 Mar 10 10:00 last -> 100000/
这表示 last 符号链接已成功创建,并指向 100000/ 目录。
使用符号链接
你可以通过以下方式使用符号链接:
-
进入
last目录:cd last这相当于进入
100000/目录。 -
列出
last目录的内容:ls last -
删除符号链接:
如果需要删除符号链接,可以使用以下命令:rm last注意:这只会删除符号链接,不会删除目标目录
100000/。
总结
- 使用
ln -s 100000/ last创建符号链接。 - 使用
ls -l验证符号链接。 - 通过
cd last或ls last使用符号链接。
最终可使用如下代码进行运行校验,这里很多坑,具体坑我一个个debug出来的,可见后文ps中我的debug过程。
坑1:control.repo_id 得eval开头
坑2:本地的话control.push_to_hub设置成false
坑3:control.local_files_only=true
坑4:control.policy.path建议直接填绝对路径
坑5:要加上control.device=cuda,这里为啥要加,可能是新老代码不兼容导致的,具体得看个人实际报错
ython lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=record \
--control.fps=30 \
--control.single_task="Grasp a lego block and put it in the bin." \
--control.repo_id=zhiliang22/eval_act_so100_test \
--control.tags='["tutorial"]' \
--control.warmup_time_s=5 \
--control.episode_time_s=30 \
--control.reset_time_s=30 \
--control.num_episodes=30 \
--control.push_to_hub=false \
--control.local_files_only=true \
--control.policy.path=/home/xzl/Project/aloha_robot_arm/lerobot-main/outputs/act_so100_test/checkpoints/last/pretrained_model \
--control.device=cuda
b站效果:
ps:本人Degbug过程
好了,之后使用github的评估代码验证报错,本地下载训练好的东西,错误写法1如下
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=record \
--control.fps=30 \
--control.single_task="Grasp a lego block and put it in the bin." \
--control.repo_id=zhiliang22/so100_test \
--control.tags='["tutorial"]' \
--control.warmup_time_s=5 \
--control.episode_time_s=30 \
--control.reset_time_s=30 \
--control.num_episodes=30 \
--control.push_to_hub=false \
--control.local_files_only=true \
--control.policy.path=outputs/train/act_so100_test/checkpoints/last/pretrained_model
直接使用上面的代码,运行时候,debug了下会在代码下处报错
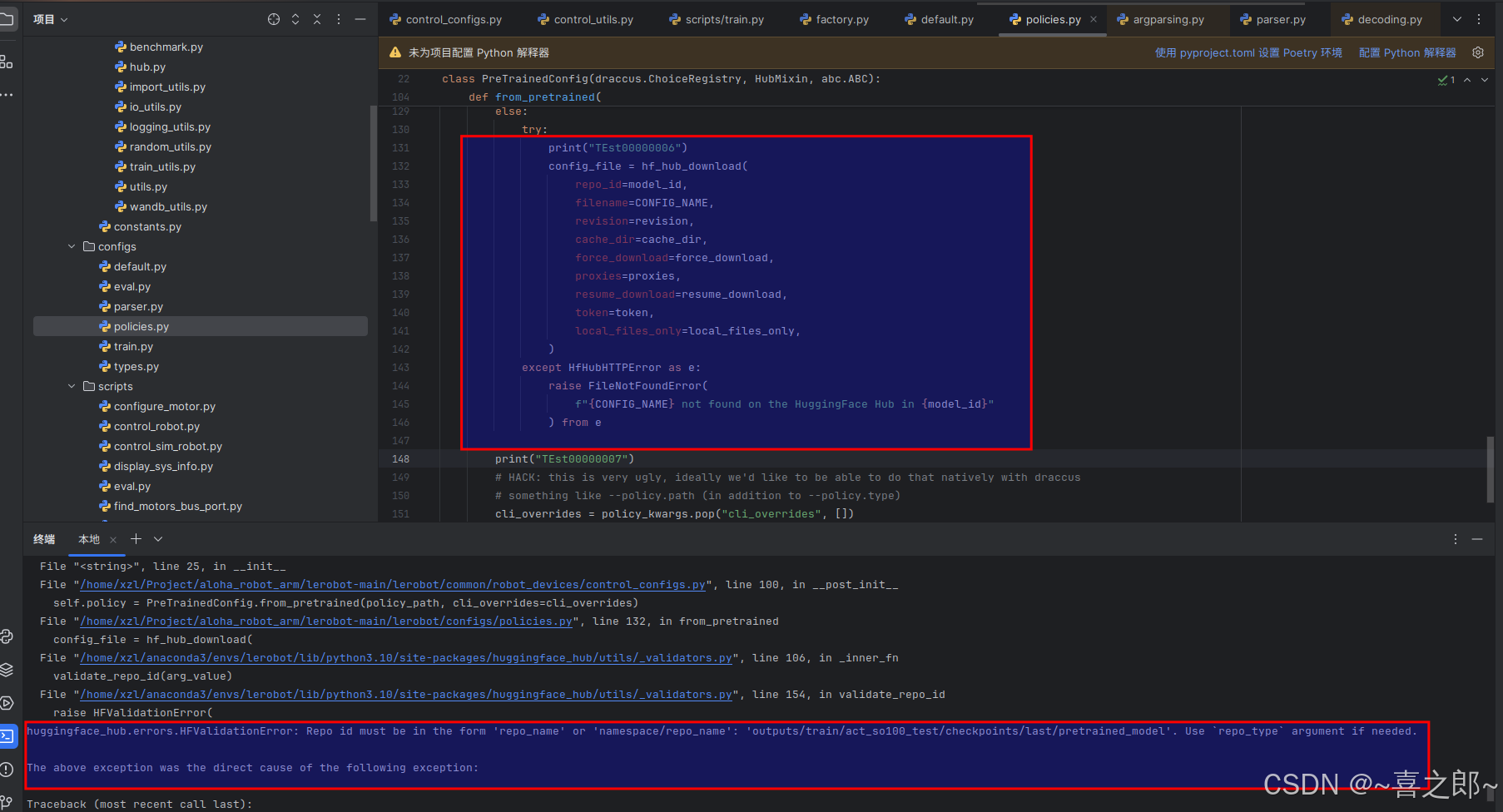
在线huggingface下载本人暂时改了这里,代码逻辑还是不通
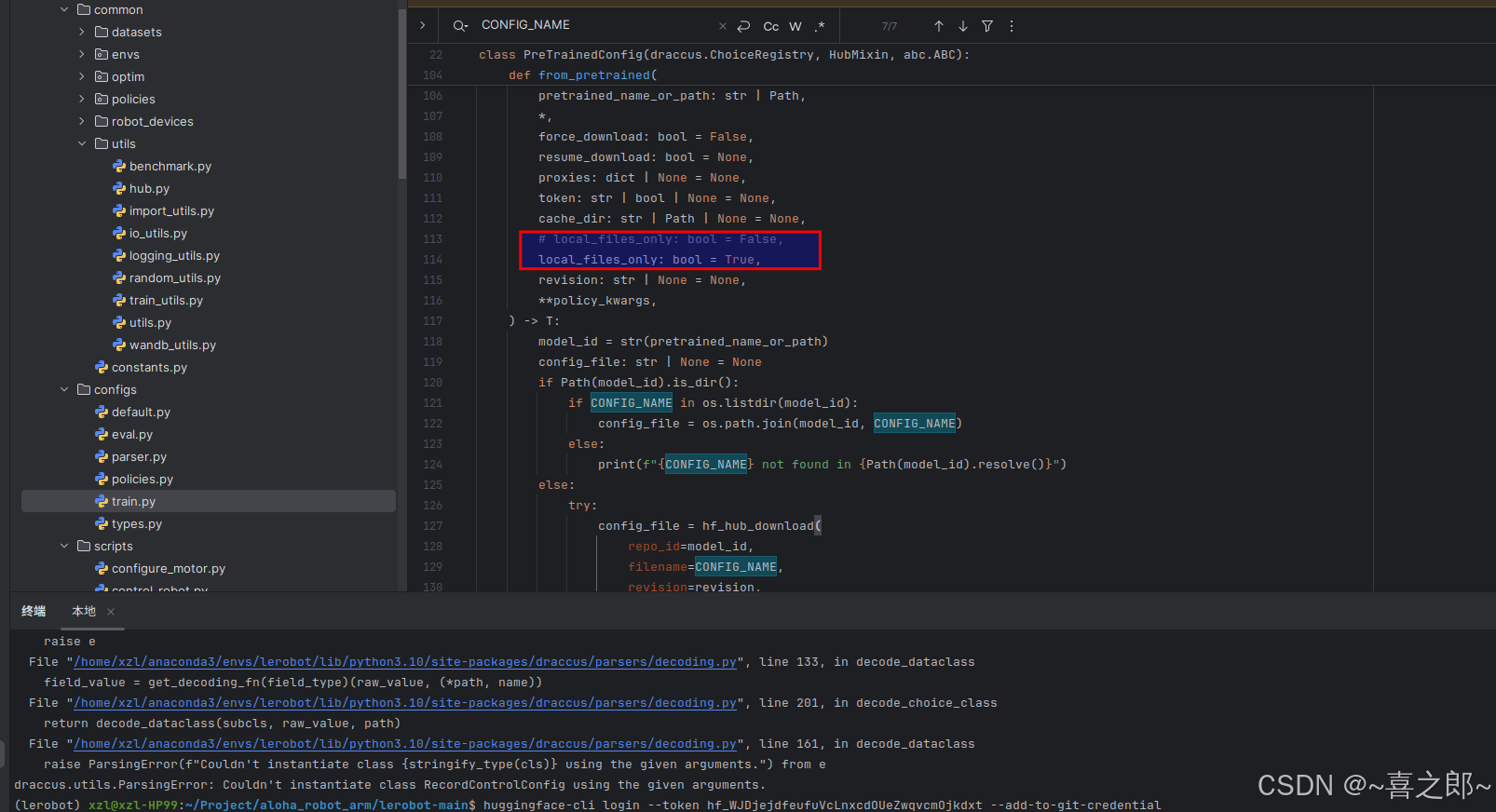 于是便使用如下写法,将这里control.policy.path路径改为绝对路径,这样代码可以走上面的本地逻辑
于是便使用如下写法,将这里control.policy.path路径改为绝对路径,这样代码可以走上面的本地逻辑
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=record \
--control.fps=30 \
--control.single_task="Grasp a lego block and put it in the bin." \
--control.repo_id=zhiliang22/so100_test \
--control.tags='["tutorial"]' \
--control.warmup_time_s=5 \
--control.episode_time_s=30 \
--control.reset_time_s=30 \
--control.num_episodes=30 \
--control.push_to_hub=false \
--control.local_files_only=true \
--control.policy.path=/home/xzl/Project/aloha_robot_arm/lerobot-main/outputs/act_so100_test/checkpoints/last/pretrained_model
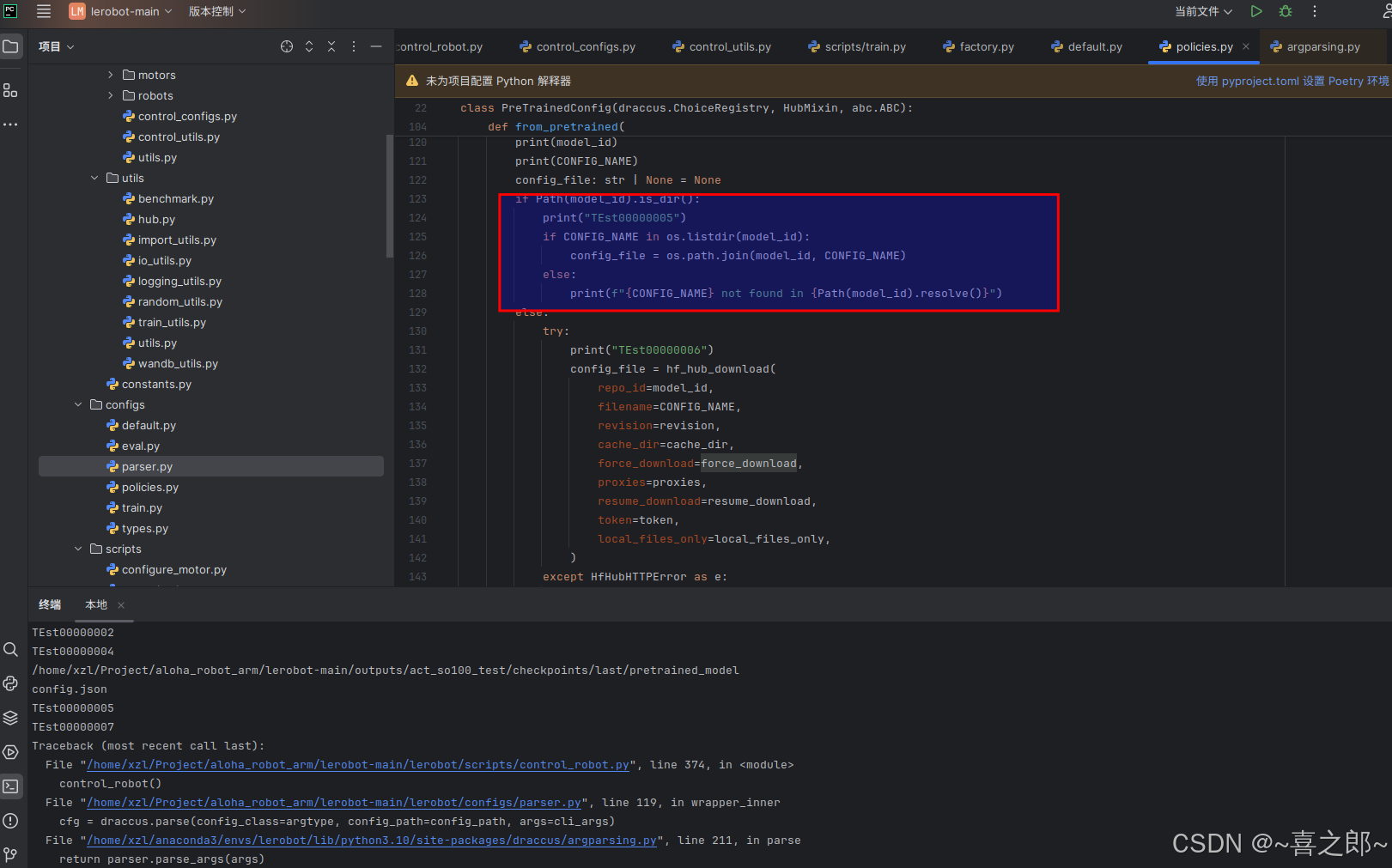
但是还是报错,这里往下走又报错了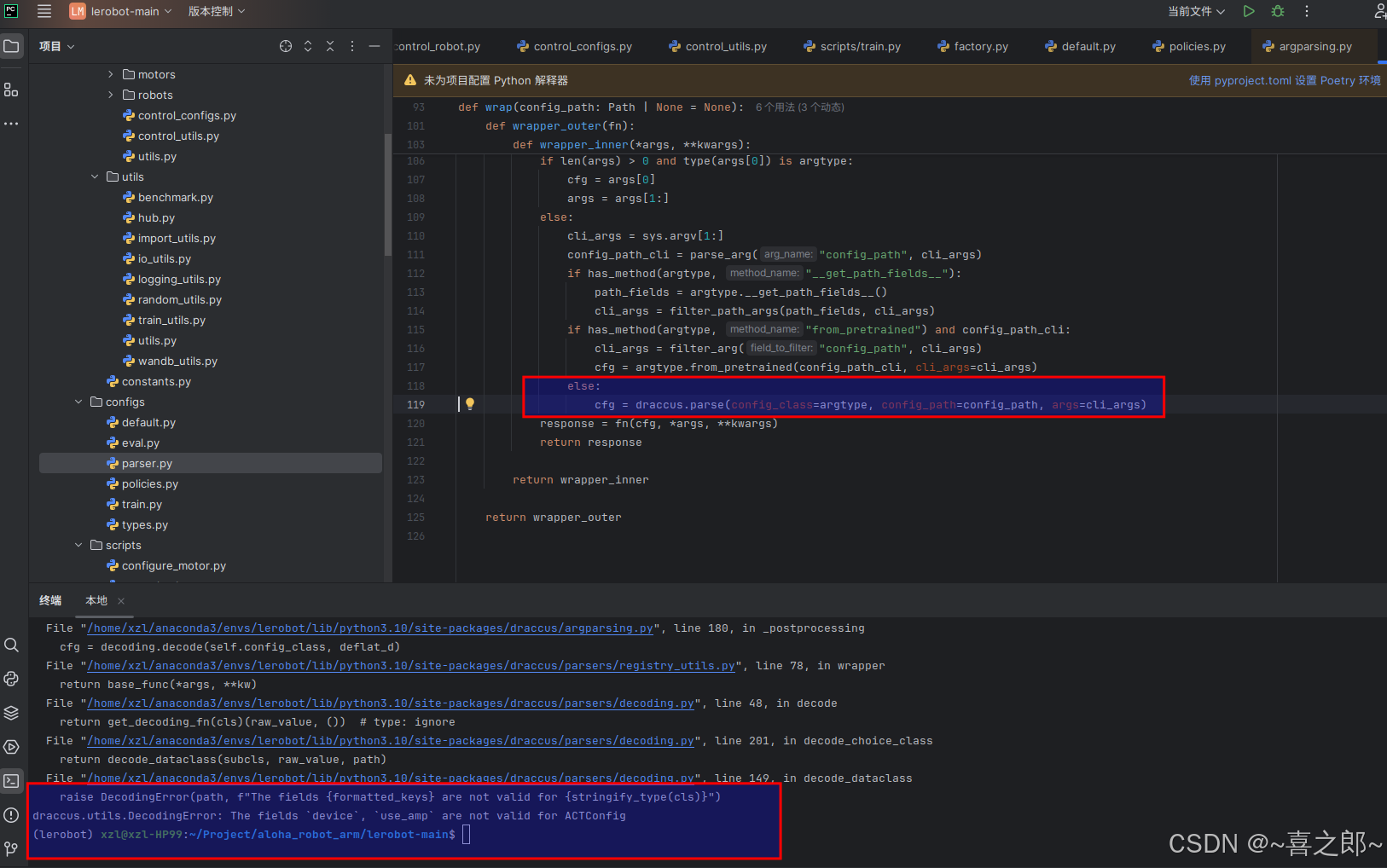 按照豆包解释
按照豆包解释
从你给出的错误信息来看,问题的根源在于 is_torch_device_available 函数里抛出了 ValueError 异常,提示未知设备 None。下面为你详细分析并给出解决办法。
错误分析
错误信息的核心部分如下:
ValueError: Unknown device 'None.
这表明在代码里,is_torch_device_available 函数接收到了 None 作为设备参数,然而该函数并不认可 None 为有效的设备。此错误在 RecordControlConfig 类的 __post_init__ 方法里被触发,代码如下:
if not is_torch_device_available(self.device):
这意味着 self.device 的值为 None,但在调用 is_torch_device_available 函数时,它期望的是一个有效的设备字符串(像 'cpu' 或者 'cuda')。
解决办法
1. 检查配置文件或者命令行参数
要保证在配置文件或者命令行参数里,device 参数被正确设置。你可以在命令行里添加 --control.device=cpu 或者 --control.device=cuda 来明确指定设备。示例如下:
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=record \
--control.fps=30 \
--control.single_task="Grasp a lego block and put it in the bin." \
--control.repo_id=zhiliang22/so100_test \
--control.tags='["tutorial"]' \
--control.warmup_time_s=5 \
--control.episode_time_s=30 \
--control.reset_time_s=30 \
--control.num_episodes=30 \
--control.push_to_hub=false \
--control.local_files_only=true \
--control.policy.path=/home/xzl/Project/aloha_robot_arm/lerobot-main/outputs/act_so100_test/checkpoints/last/pretrained_model \
--control.device=cpu
2. 在代码里设置默认设备
要是你不想每次都在命令行里指定设备,那么可以在 RecordControlConfig 类里为 device 参数设置一个默认值。示例如下:
from dataclasses import dataclass
@dataclass
class RecordControlConfig:
# 其他参数...
device: str = 'cpu' # 设置默认设备为 CPU
def __post_init__(self):
if not is_torch_device_available(self.device):
# 处理设备不可用的情况
print(f"Device {self.device} is not available. Using CPU instead.")
self.device = 'cpu'
3. 修改 is_torch_device_available 函数
你可以对 is_torch_device_available 函数进行修改,让它在接收到 None 时使用默认设备。示例如下:
import torch
def is_torch_device_available(try_device):
if try_device is None:
try_device = 'cpu' # 使用默认设备 CPU
if try_device == 'cpu':
return True
elif try_device.startswith('cuda'):
return torch.cuda.is_available()
else:
raise ValueError(f"Unknown device '{try_device}'.")
通过上述方法,你应该能够解决 Unknown device 'None' 的错误。
按照豆包的改了下,加上device,又报错了,说我数据集命名有问题,
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=record \
--control.fps=30 \
--control.single_task="Grasp a lego block and put it in the bin." \
--control.repo_id=zhiliang22/so100_test \
--control.tags='["tutorial"]' \
--control.warmup_time_s=5 \
--control.episode_time_s=30 \
--control.reset_time_s=30 \
--control.num_episodes=30 \
--control.push_to_hub=false \
--control.local_files_only=true \
--control.policy.path=/home/xzl/Project/aloha_robot_arm/lerobot-main/outputs/act_so100_test/checkpoints/last/pretrained_model \
--control.device=cuda
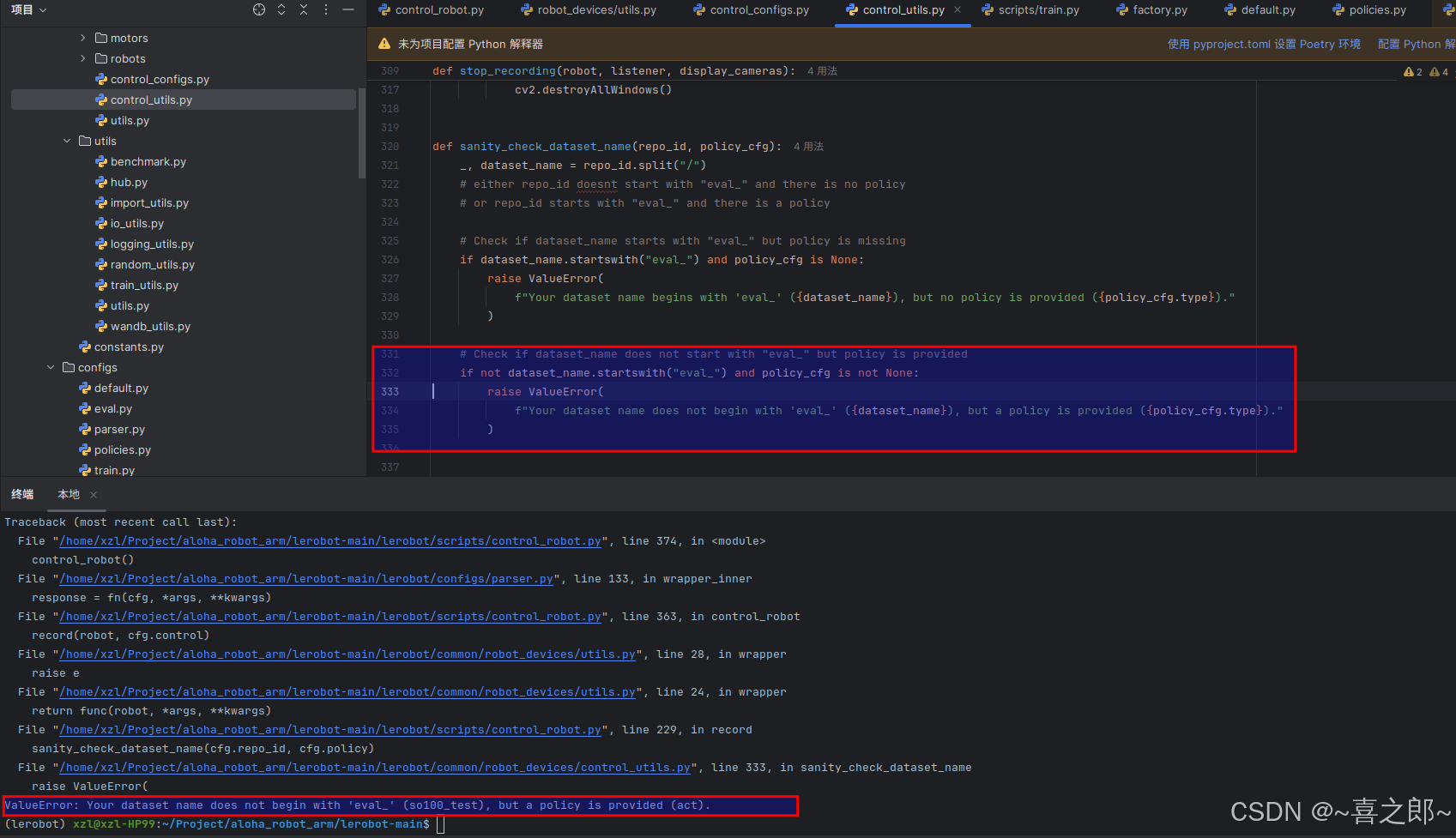 所以,必须以eval开头,这样在你Ubantu上的cahe目录才生成文件夹,最终使用如下代码才成功。
所以,必须以eval开头,这样在你Ubantu上的cahe目录才生成文件夹,最终使用如下代码才成功。
ython lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=record \
--control.fps=30 \
--control.single_task="Grasp a lego block and put it in the bin." \
--control.repo_id=zhiliang22/eval_act_so100_test \
--control.tags='["tutorial"]' \
--control.warmup_time_s=5 \
--control.episode_time_s=30 \
--control.reset_time_s=30 \
--control.num_episodes=30 \
--control.push_to_hub=false \
--control.local_files_only=true \
--control.policy.path=/home/xzl/Project/aloha_robot_arm/lerobot-main/outputs/act_so100_test/checkpoints/last/pretrained_model \
--control.device=cuda

















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









