






这里携带逆向方法进行请求
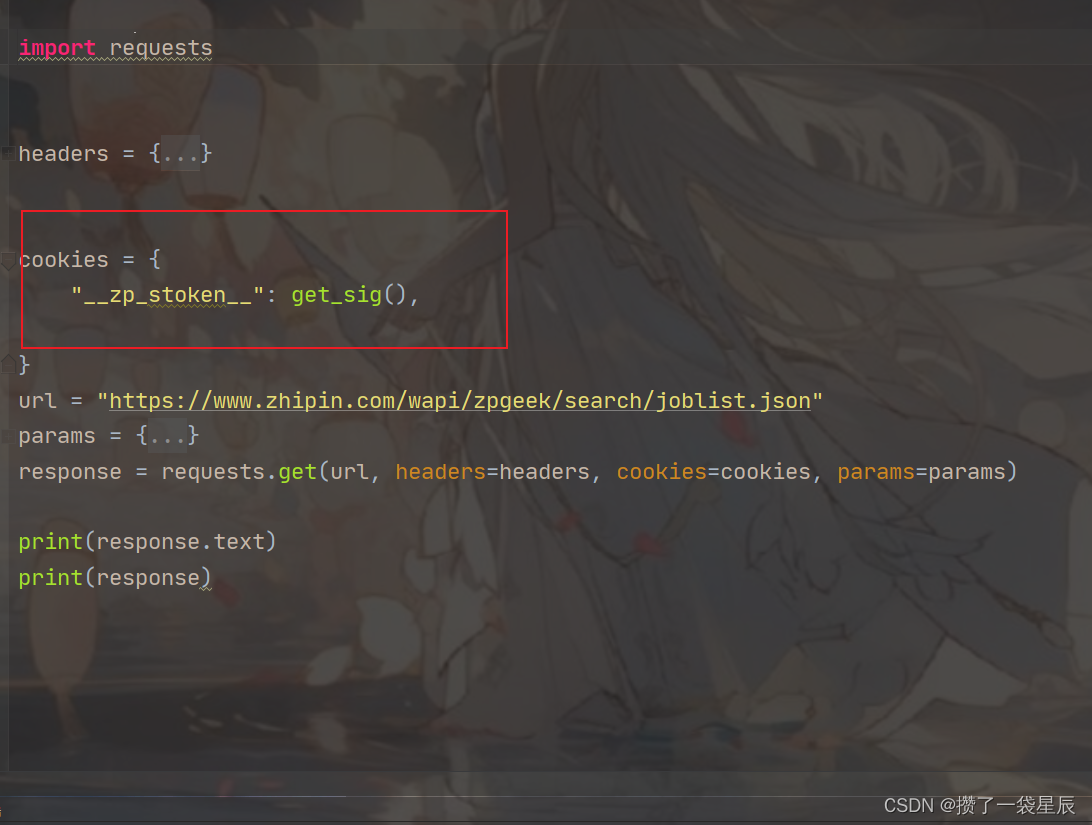
获得数据
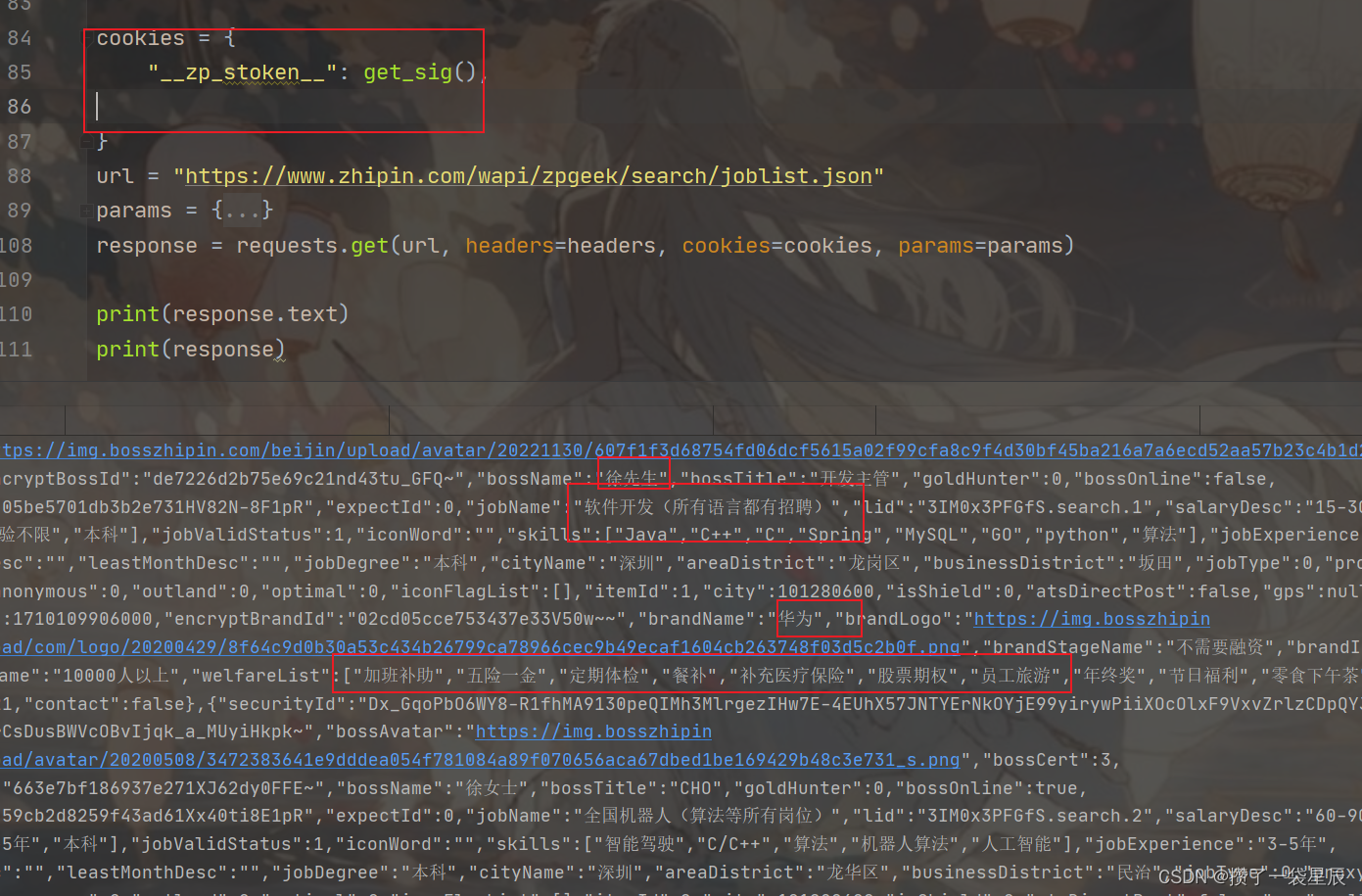
需要逆向方法请私聊 , 下面部分只展示爬取思路
- 对网页进行分析抓包
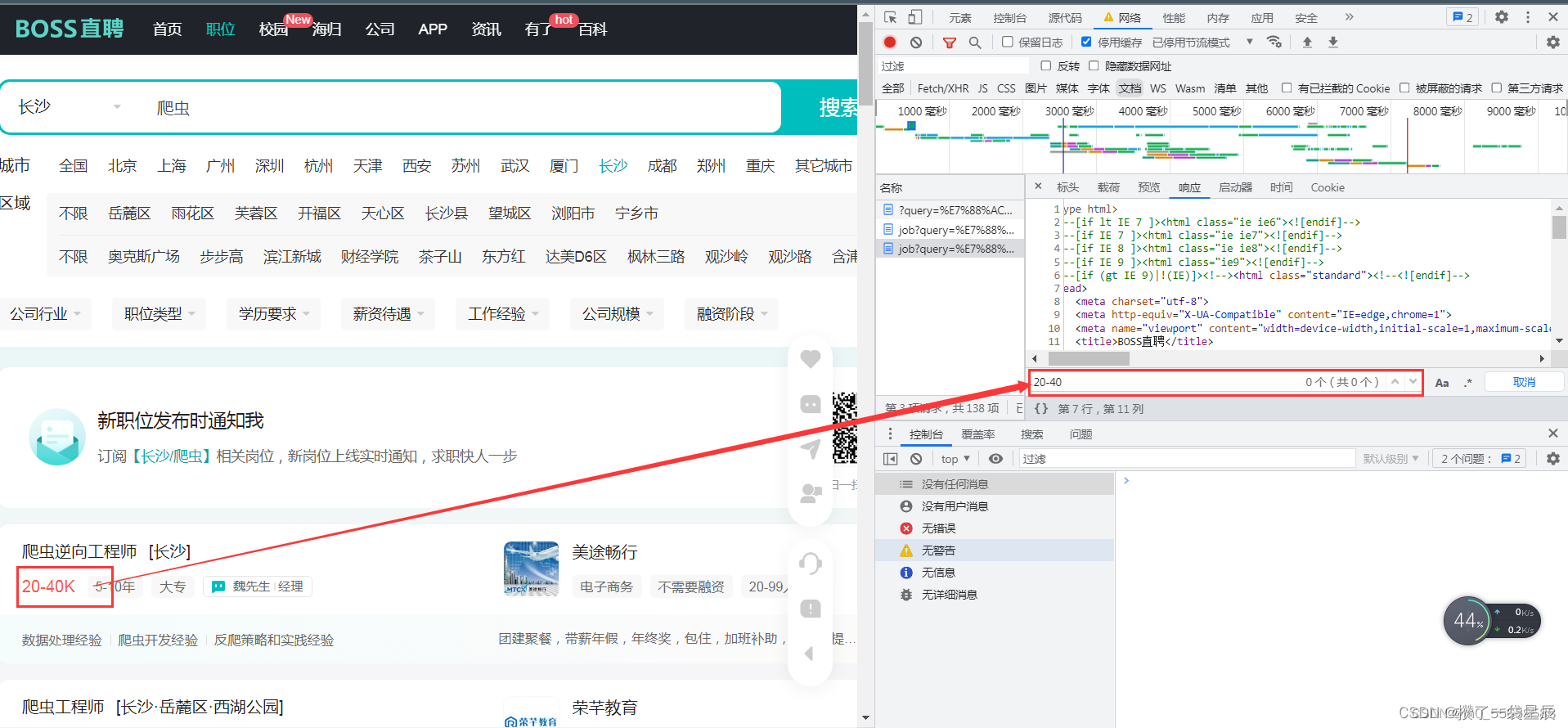
- 设置参数 – 城市/薪资范围/职业
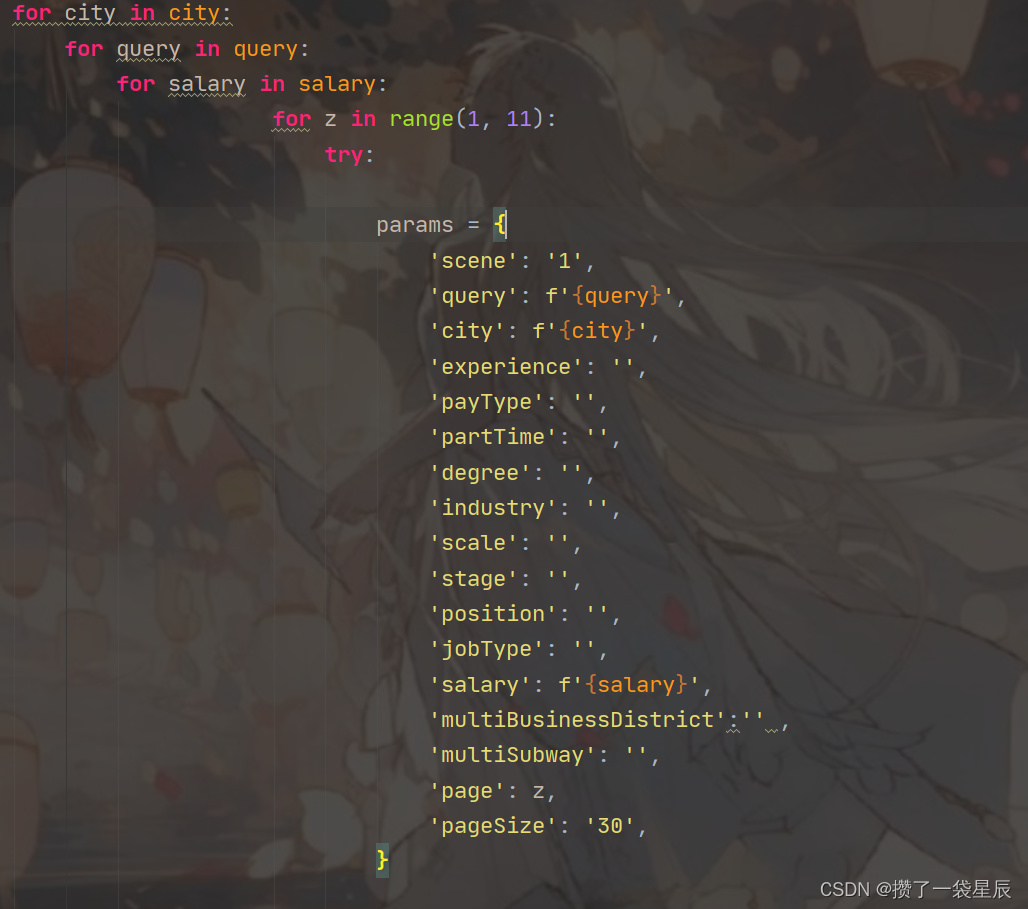
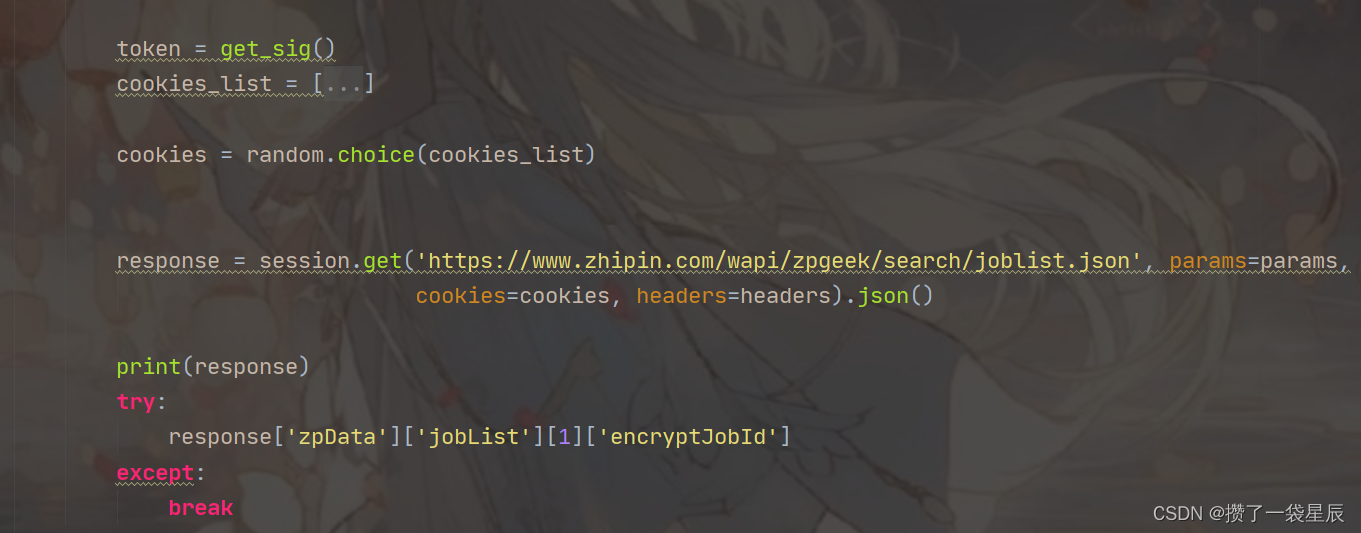
- 对网页进行请求获得数据集
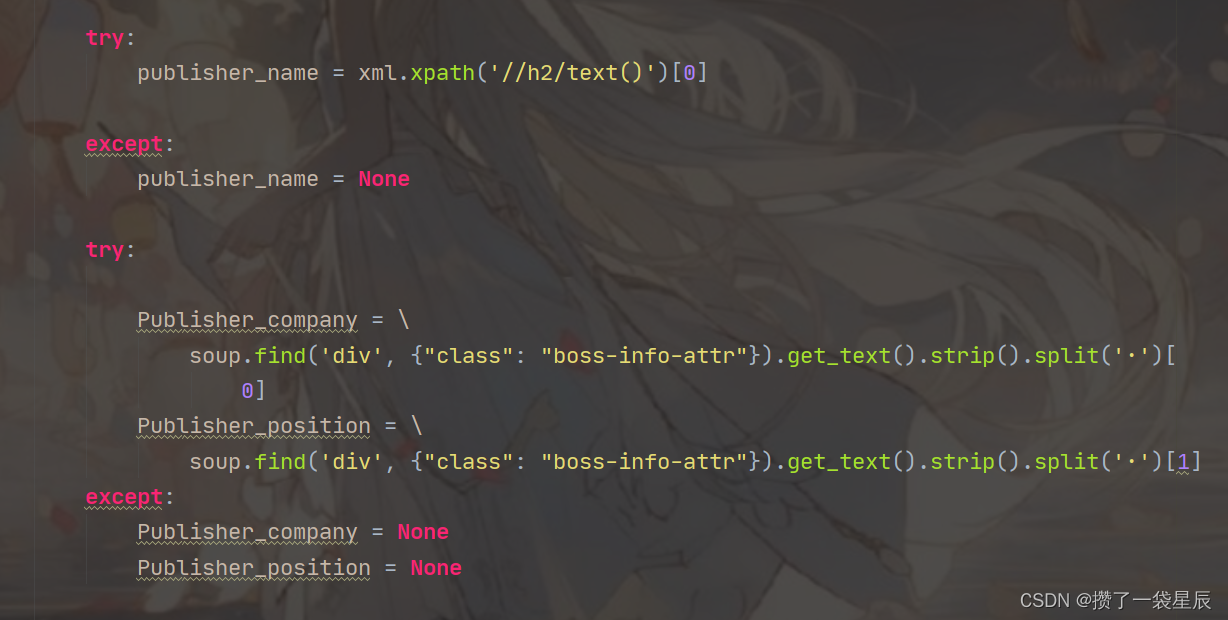
- 利用xpath,soup等进行进行数据清洗
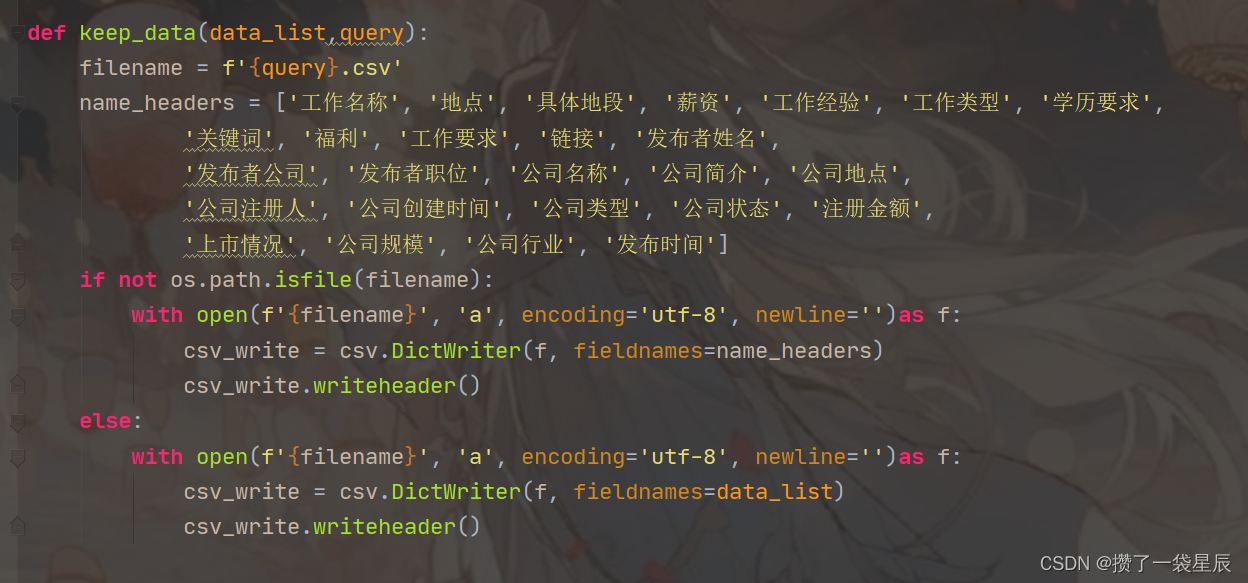
- 将数据一csv的格式保存
编写一个爬虫的基本实现思路可以概括为以下几个步骤。请注意,由于爬虫可能涉及法律和道德问题,特别是当它们用于未经授权地抓取网站数据时,因此在开始之前,请确保你的爬虫行为符合目标网站的robots.txt规则以及当地的法律法规。
1. 确定目标
- 明确需求:确定你需要从哪些网站抓取哪些数据。
- 分析网站结构:了解目标网站的页面结构,包括URL模式、页面元素等。
2. 编写爬虫框架
- 选择编程语言:Python是编写爬虫的热门选择,因为它拥有强大的库支持,如
requests、BeautifulSoup、Scrapy等。 - 设置基础结构:创建一个基本的Python脚本,导入必要的库。
3. 发送HTTP请求
- 使用requests库(或其他HTTP客户端库)发送GET或POST请求到目标URL。
- 处理重定向和Cookies:确保爬虫能够处理重定向和保持会话状态(如登录状态)。
- 设置请求头:模拟浏览器发送请求,设置合适的
User-Agent和其他必要的请求头。
4. 解析HTML内容
- 使用解析库:如
BeautifulSoup、lxml等,解析HTML文档。 - 提取数据:根据HTML结构,使用CSS选择器、XPath等方法提取所需数据。
5. 存储数据
- 保存到文件:将抓取的数据保存为CSV、JSON等格式的文件。
- 使用数据库:对于大量数据,可以考虑使用数据库(如MySQL、MongoDB)来存储。
6. 处理JavaScript渲染的页面
- 如果目标网站大量使用JavaScript渲染页面内容,可能需要使用
Selenium或Puppeteer(Node.js环境)等工具来模拟浏览器行为。
7. 遵守robots.txt规则和礼貌爬虫
- 检查robots.txt:在开始抓取之前,检查目标网站的
robots.txt文件,确保你的爬虫行为被允许。 - 设置合理的请求间隔:避免过于频繁地发送请求,给目标网站服务器带来压力。
- 处理反爬虫机制:如验证码、IP封锁等,可能需要采取额外的措施来绕过这些机制(但请注意,绕过某些反爬虫机制可能违反法律法规)。
8. 调试和优化
- 调试:在开发过程中,使用打印语句、断点调试等方法来检查爬虫的行为是否符合预期。
- 优化性能:对于大型网站或需要抓取大量数据的情况,优化爬虫的性能变得尤为重要。可以通过多线程/多进程、异步IO等方式来提高效率。


















 1710
1710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











