









修改自我组会报告,具体细节请读原文。
引子
论文标题是:AlphaHoldem: High-Performance Artificial Intelligence for Heads-Up No-Limit Texas Hold’em from End-to-End Reinforcement Learning

在写这篇文章的时候,论文还没有正式发布,我这里读的是预发布版本。我邮件联系了论文作者之一的兴军亮老师,他的回复是:
你好,欢迎关注我们的工作。论文的终稿近期会在网上公布,里面会有详细描述。我们还会共公布大量对抗数据,也会有助你理解AI和人的决策差异。其他问题,你可以和我的学生联系。
现在网络上基本搜到的PR稿都是一个模子里刻出来的,就不赘述了。
说实话论文挺让我震撼的。没有采用传统德州扑克的CFR系列的解决方案,使用只进行正向的神经网络,取得这么好的成绩,让我直呼“不可思议”。
我们进入正题吧。
背景介绍

论文研究的是双人无限注德州扑克AI。
德州扑克规则
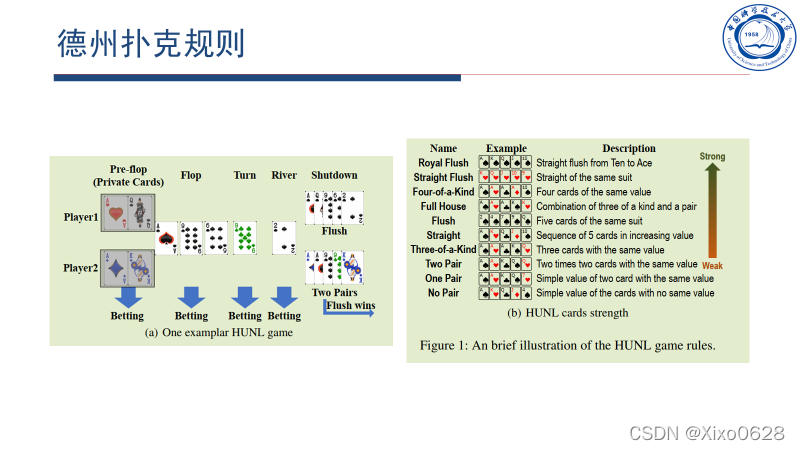
简单介绍一下,就是2张明牌和5张公共牌。最多有4轮下注,前3轮下注后分别可以多看3/1/1张公共牌,最后一轮下注后可以和对面比大小。中途弃牌视为放弃本轮。
然后从2(手牌)+5(公共牌)张牌中选择5张进行大小比较。胜利者获得本轮游戏双方的所有下注。
论文贡献
- 提出端到端强化学习框架,每个决策时刻仅使用神经网络正向传播,从状态信息直接推理到最终动作
- 提出新的游戏状态标识
- 获得了高性能的AI,单机训练3天,击败了Slumbot、DeepStack和职业牌手
信息编码方式
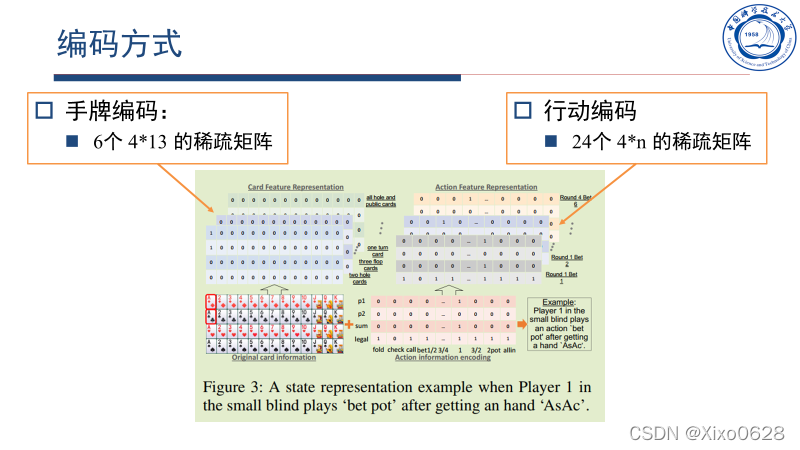
牌的信息和行动信息分别进行独立编码。
牌用6个矩阵表示,分别对应2张手牌、3张翻牌、1张转牌、1张河牌、所有公共牌(翻牌、转牌、河牌)和所有已知牌(手牌、公共牌)。每个矩阵都是413的,对应52张扑克牌。如果有对应的牌就在矩阵中写1否则写0。容易判断,这些矩阵都是稀疏矩阵。
行动编码的话用了24个矩阵。每一轮下注认为最多有6轮加注/再加注/跟注/弃牌。一共用46个矩阵表征每一轮的动作。
网络结构
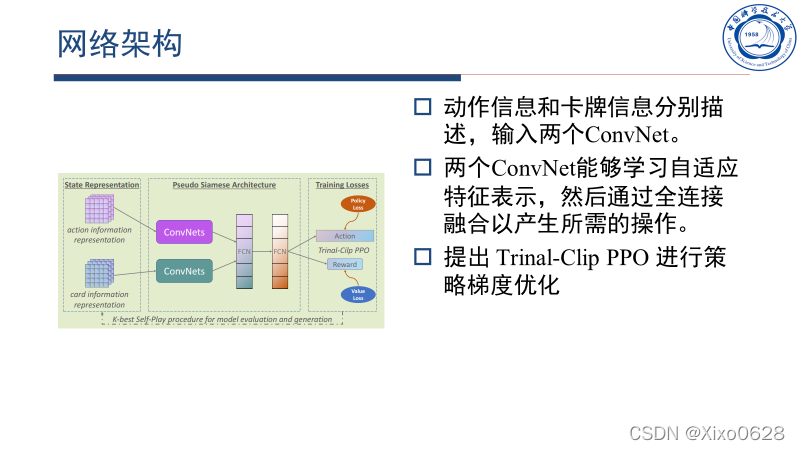
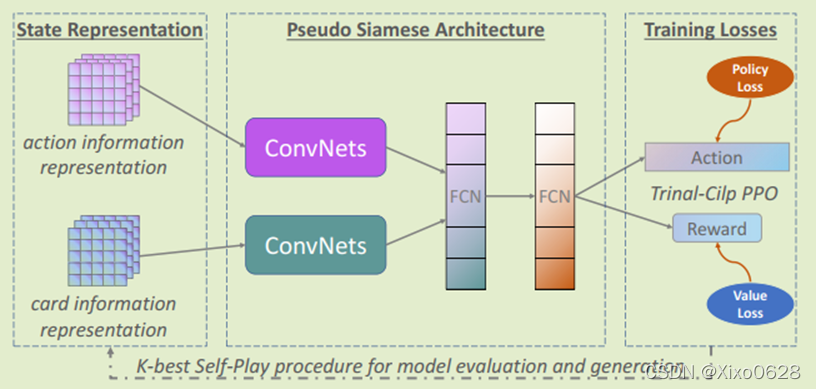
将分开编码的动作信息和卡牌信息分别输入卷积神经网络,处理后将信息输入全连接层。然后直接输出对应地动作和reward,用Trinal-Clip PPO进行策略梯度的优化。
自博弈算法
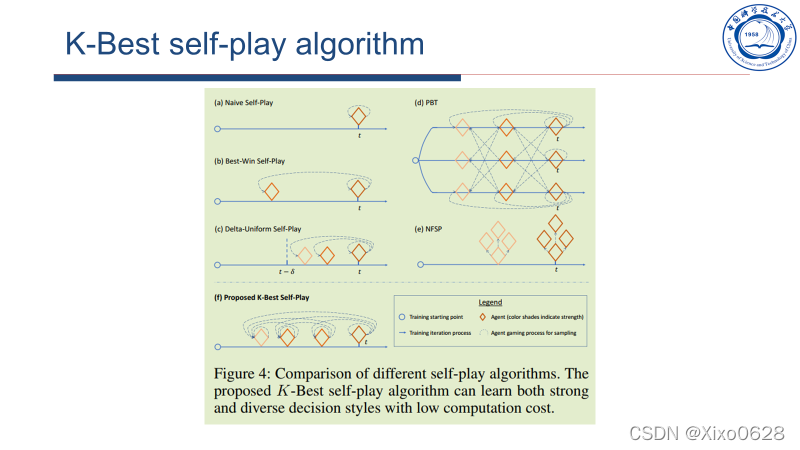
文章提出了K-best 的自博弈算法,也就是和历史上成绩最好(ELO评分)的K个模型进行对打。这样子认为不容易陷入策略循环克制的陷阱。
个人觉得这个K-best的自博弈算法也蛮有意思的。
性能比较
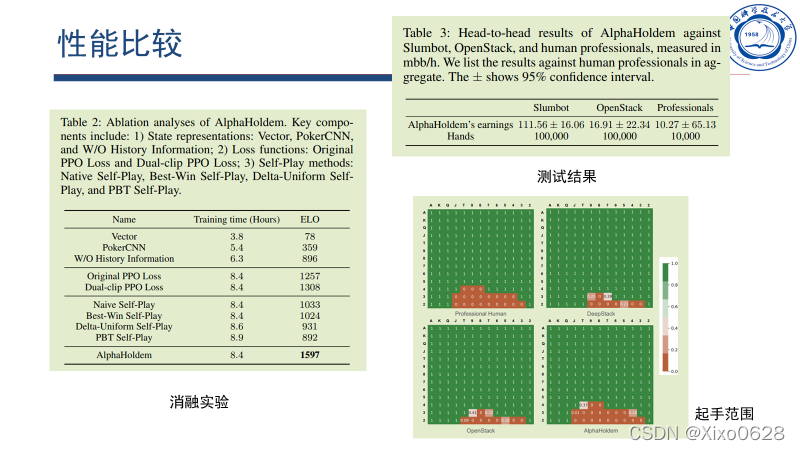
论文进行了消融实验,说明了编码方式、强化学习方式、自博弈方式都会影响Agent的性能。
和Slumbut、openStack的对打十万手牌,均取得较好结果。在和专家牌手的一万手牌中,也取得了一定的优势(但是方差很大)。
最终起手的范围来看,模型和专家人类是差不太多的,说明学到的模型是有意义的。
值得一提的是,只用很少的训练资源就完成了训练。相比DeepStack,每一个动作的决策时间也缩短了大约1000倍。
都看到这里了,就动动手点个赞吧~















 1841
1841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











