






目录
一、介绍
1、官网
是一个Python库,用 于拟合多种统计模型,执行统计测试以及数据探索和可视化。
2、主要功能





3、安装
方法一:pip install statsmodels
方法二:conda install –c conda-forge statsmodels
二、t检验
1、概念
通过比较不同数据之间的差值,以观察数据之间有没有显著差异。适用于小样本(30个以下)、总体方差未知的情况。
2、假设条件
(1)总体分布服从正态或近似服从正态分布。
(2)检验定量数据,即数据大小是有意义的,对于分类数据的检验请移步卡方检验。
# 区别:样本标准差和总体标准差
# 样1本标准差=(x-均值)/(n-1)
# 总体标准差=(x-均值)/n# 用scipy计算出的是:双尾检验
# 单(1samp)样本t检验(ttest_1samp)
# 相关(related)样本t检验(ttest_rel)
# 双独立(independent)样本t检验(ttest_ind)
# 当不确定两总体方差是否相等时,应先利用levene检验,检验两总体是否具有方差齐性。
# stats.levene(data1,data2)
# 如果返回结果的p值远大于0.05,那么我们认为两总体具有方差齐性。
# 如果两总体不具有方差齐性,需要加上参数equal_val并设定为False。如下。
# stats.ttest_ind(data1,data2,equal_var=False)# 判断标准(显著水平)alpha=5%,1%,10%
# 左尾判断条件:t < 0 and p_one < 判断标准(显著水平)alpha
# 右尾判断条件:t > 0 and p_one < 判断标准(显著水平)alpha
# p值:假定原假设成立的前提下,得到样本平均值的概率是多少。p值越小,则拒绝原假设# 效应量:在判断某个调查研究的结果,是否有意义或者重要时,要考虑的另一项指标是效应量。
# 效应量太小,意味着处理即使达到了显著水平,也缺乏实用价值。
# .20 小的效应,.50中等效应,.80高的效应(d绝对值)
3、单样本t检验
假定我们得到了k个测试错误率,![]() , 则平均测试错误率𝜇 和方差𝜎 2为:
, 则平均测试错误率𝜇 和方差𝜎 2为:
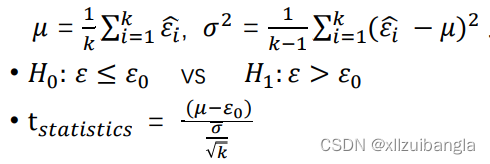
实现:stats.ttest_1samp
# 引入所需库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import math
from scipy import stats
data1 = pd.Series([0.6, 0.2 , 0.05 ,0.5 ,0.004 ,0.4 ,0.06, 0.09 ,0.7, 0.9]) #构建十个数的一维数组
data_mean1 = data1.mean() #样本均值
data_std1 = data1.std() #样本标准差
print('样本均值 = {},样本标准差 = {}。'.format(data_mean1,data_std1))
pop_mean= 0.3 #平均值u
t_sta = (data_mean1-pop_mean)*math.sqrt(10)/data_std1 #相关配对的效应值
t,p_towTail = stats.ttest_1samp(data1,pop_mean) #t值,双尾检验的p值
# 单尾检测的p值
p_one = p_towTail/2
d=(data_mean1 - pop_mean) / data_std1 #效应量
print('t值 = {},双尾检验的p值 = {}。'.format(t,p_towTail))
data2 = pd.Series([0.06, 0.02 , 0.05 ,0.15 ,0.004 ,0.04 ,0.06, 0.09 ,0.07, 0.09]) #构建十个数的一维数组
data_mean2 = data2.mean()
data_std2 = data2.std()
pop_mean= 0.3
t2,p_towTail2 = stats.ttest_1samp(data2,pop_mean) # 单(1samp)样本t检验(ttest_1samp)
print('t值 = {},双尾检验的p值 = {}。'.format(t2,p_towTail2))
4、配对样本t检验
用于分析配对定量数据之间的差异对比关系,这个就和独立样本t检验区分开了,要求样本量相同且前后顺序要一一 对应。
基本实现思路:

实现:scipy.stats.ttest_rel(x,y)
# 引入所需库
from scipy.stats import ttest_rel
import pandas as pd
import math
# 引入列表x,y
x = [0.5, 0.8, 0.8, 0.9, 0.5, 0.5, 0.01, 0.2]
y = [0.7, 0.3, 0.01, 0.8, 0.01, 0.1, 0.01, 0.1]
# 配对样本t检验
m,n = ttest_rel(x, y)
print('统计值 = {},P值 = {}'.format(m,n))
print(ttest_rel(x, y))
di = pd.Series([-0.2,0.5,0.79,0.1,0.49,0.4,0,0.1])
data_mean3 = di.mean()
data_std3 = di.std()
t_sta = (data_mean3-0)*math.sqrt(8)/data_std3
三、McNemar检验与Nemenyi检验
1、分别统计两学习器A与B在下列四种情形下的样本数:
判断都正确、都错误、A正确B错误,A错误B正确
2、𝐻0:学习器A与B无显著区别 vs 𝐻1:学习器A与B显著区别
3、实现:是statsmodels.sandbox.stats.runs . mcnemar(f_obs)
(一)麦克尼马尔检验——McNemar检验
# 引入所需库
from statsmodels.sandbox.stats.runs import mcnemar
import numpy as np
f_obs = np.array([[20, 21],[43, 16]]) #引入二维数组
(statistic, pVal) = mcnemar(f_obs) #statistic——统计值,pVal——p值
print('p = {0:5.3e}'.format(pVal))
#判断显著性
if pVal < 0.05: #显著性水平为alpha = 5%
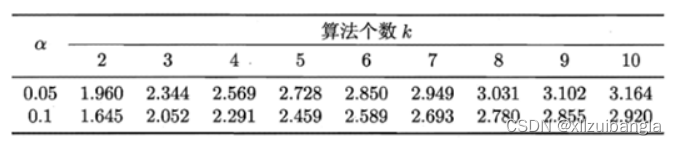
print("There was a significant change between algorithm A and B.") (二)、Nemenyi检验计算出平均序值差别的临界值域CD:

值参见下表:
四、Friedman检验
对于k个算法和N个数据集,首先得到每个算法在每个数据集上的测试性能结果,然后根据性能结果有好到坏排序,并给出序值1, 2, …, k,若多个算法性能结果相同,则它们平分序值,假设第i个算法的平均序值为ri,则ri服从正态分布:
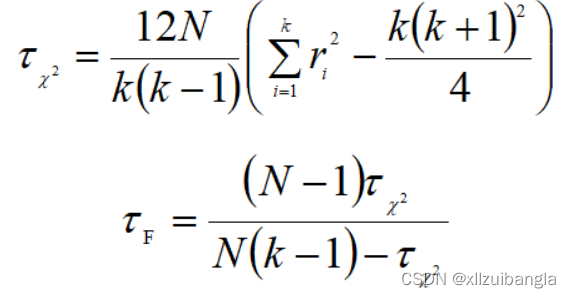
则变量tF服从自由度为k-1和(k-1)(N-1)的F分布,假设这k个算法在N个数据集上的性能没有差异,若假设检验拒绝这个假设,则说明算法的性能显著不同,这时需要进行后续检验进一步区分各算法。
import numpy as np
data = np.array([[1,2,3],[1,2.5,2.5],[1,2,3],[1,2,3]]) #4*3二维数组
# 定义函数
def Friedman(n,k,data_matrix):
'''
Friedman检验
参数:数据集个数n, 算法种数k, 排序矩阵data_matrix
返回值是Tf
'''
#计算每个算法的平均序值,即求每一列的排序均值
row,col = data_matrix.shape #查看数据形状
order_mean = list() #空列表
for i in range(col): #计算平均序值
order_mean.append(data_matrix[:,i].mean())
sum_mean = np.array(order_mean)#转换数据结构方便下面运算
## 计算总的排序和即西伽马ri^2
sum_ri2_mean = (sum_mean ** 2).sum()
#计算Tf
result_Tx2 = (12 * n) * (sum_ri2_mean - ((k * (k + 1) ** 2) / 4)) / (k * (k + 1))
result_Tf = (n - 1) * result_Tx2 / (n * (k - 1) - result_Tx2)
return result_Tf
Tf = Friedman(4,3,data)
print(Tf)
# 判断显著性
if Tf < 5.143:
print("There was no significant change between algorithm A, B and C at 0.05 significance level.")
else:
print("There was a significant change between algorithm A, B and C at 0.05 significance level.")















 1181
1181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









