







1. Overview
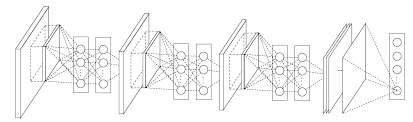
1. 1×1卷积核
2. MLP Convolution Layers
3. Global Average Pooling
1*1 卷积核
传统卷积核最小是3×3,这样还能保证所有方向,而这里的卷积核有说是相当于全连接.
原文中的解释是对输入的feature map的加权线性重组,目的是跨通道的复杂和可学习的信息交互。
也是因为这种操作只对通道运算,与空间无关。
比较极端的一个例子:如果1×1卷积核设置的通道数与输入的feature map通道数一样,
那么这个卷积核与average pooling的作用是等价的。
一般情况下,这种严格线性变换之后要由非线性激活曾来继承(例如Relu)。
此文中初次提出,然后在GoogLeNet及之后出现的各种网络中,也大量使用了这种手段,是一种很有效的降维模型,能突破计算瓶颈,从而把网络做宽做深。
因为1×1这个卷积核非常小,拥有更少的参数意味着更加不容易过拟合.
MLP Convolution Layers
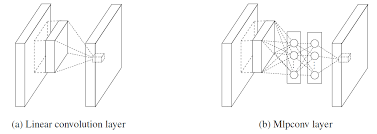
传统的卷积层是直接的线性运算+激活函数,抽象程度较低。
与maxout作比较:
maxout 用分段线性去对任意凸函数建模。因此,通过对凸函数的局部近似,maxout有了在凸面上分离超平面的能力。
而此文中在卷积层中加入Mlpconv与之不同的是,这种使用了微神经网络的函数近似器有更大的能力模拟潜在分布。
这里使用的激活函数依然是Relu
Global Average Pooling
传统cnn把卷积当做特征提取器最后把特征灌进全连接再softmax进行分类。
Global Average Pooling是用来代替全连接的。
每张feature map均值成一个点,很多张排成一个向量,输入到softmax中
这里使用Global Average Pooling要比全连接要好。
其一是因为结构更加自然,把feature map 和categories更好的联系起来
其二是这层不用调参,所以至少这层不会overfitting
其三是他把空间信息直接加到一起,这样会对输入的各种空间信息更加robust
reference
Network In Network
Going Deeper with Convolutions
Global average Pooling
One by One [ 1 x 1 ] Convolution - counter-intuitively useful
1x1 Convolutions - Why use them?
[Paper summary] Network In Network (Deep NIN) - 2014















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









