







NLP-文本表示-词袋模型和TF-IDF
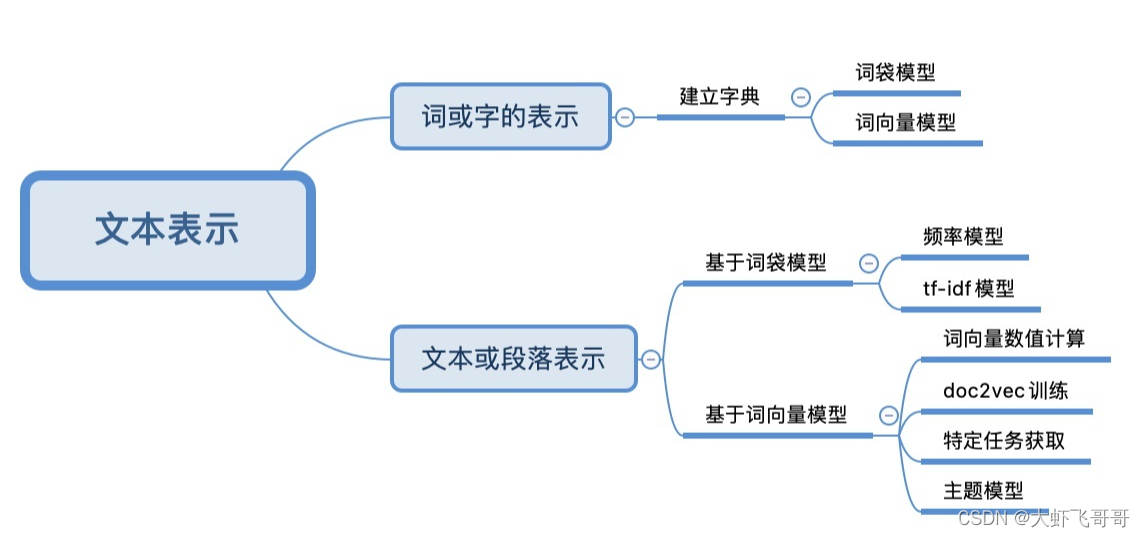
一、文本表示的几种方式
二、 词袋模型BoW(Bag-of-words)
词袋模型: 一段文本不考虑语序和词法的信息,每个单词都是相互独立的,将词语放入一个“袋子”里,统计每个单词出现的频率。
1、在词或字的维度表示 – one-hot编码
构建过程: 根据预料创建字典,每个词使用词典大小维度的向量表示,其中该词索引位置为1,其他位置为0。
举例: 有以下两条预料:
“John likes to watch movies.”,
“John also likes to watch football games.”,
创建字典 :
{'john': 3, 'likes': 4, 'to': 6, 'watch': 7, 'movies': 5, 'also': 0, 'football': 1, 'games': 2}
"John " 的表示方式: (0,0,0,1,0,0,0,0)
"likes " 的表示方式: (0,0,0,0,1,0,0,0)
"to " 的表示方式: (0,0,0,0,0,1,0,0)
"watch " 的表示方式: (0,0,0,0,0,0,1,0)
“movies” 的表示方式: (0,0,0,0,0,0,0,1)
2、在文本或段落的维度表示
构建过程: 根据预料创建字典,统计每个单词出现的频率。
“John likes to watch movies.” 的表示方式:(0,0,0,1,1,1,1,1) 即:每个单词的 one-hot编码相加。
代码实现:
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
# 语料库
docs = np.array([
"John likes to watch movies. ",
"John also likes to watch football games.",
])
count = CountVectorizer()
bag = count.fit_transform(docs)
# 输出单词与编号的映射关系。
print(count.vocabulary_)
print(bag.toarray())
3、词袋模型编码特点以及缺点
特点:
1、编码后的向量长度是词典的长度;
2、该编码忽略词出现的次序;
3、在向量中,该单词的索引位置的值为单词在文本中出现的次数;如果索引位置的单词没有在文本中出现,则该值为 0 。
缺点:
1、该编码忽略词的位置信息,词的位置不一样语义会有很大的差别;
2、该编码方式虽然统计了词在文本中出现的次数,但仅仅通过“出现次数”这个属性无法区分常用词和关键词在文本中的重要程度。
三、 词频-逆向文件频率(TF-IDF)
为了解决词袋模型无法区分常用词(如:“是”、“的”等)和专有名词(如:“自然语言处理”、“NLP ”等)对文本的重要性的问题,TF-IDF 算法应运而生。
TF-IDF的主要思想是: 如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。

如上图所示:查询词在文档5中出现频率高, 在其他文档中出现少,则认为查询词与文档5相似度高。
1、TF (Term Frequency)—— “单词频率”
TF: 计算一个查询关键字中某一个单词在目标文档中出现的次数。

举例说来,如果我们要查询 “Car Insurance”,那么对于每一个文档,我们都计算“Car” 这个单词在其中出现了多少次,“Insurance”这个单词在其中出现了多少次。
2、IDF(Inverse Document Frequency)—— “逆文档频率”
IDF:表示关键词的普遍程度。如果包含单词 t i t_{i} ti 的文档越少, IDF越大,则说明该词条具有很好的类别区分能力。
很明显,如果有太多文档都涵盖了某个单词,这个单词也就越不重要,或者说是这个单词就越没有信息量。因此,我们需要对 TF 的值进行修正,而 IDF 的想法是用 DF 的倒数来进行修正。倒数的应用正好表达了这样的思想,DF 值越大越不重要。

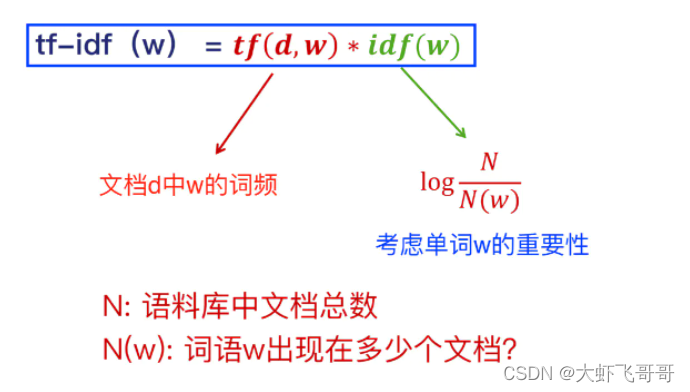
3、TF- IDF

其中:
T
F
TF
TF 一般需要标准化,解决长文档、短文档问题。
TF- IDF 应用场景: 搜索引擎 、关键词提取、文本相似性、文本摘要
代码如下:
import math
from collections import Counter
corpus = ['this is the first document',
'this is the second second document',
'and the third one',
'is this the first document']
words_list = list()
for i in range(len(corpus)):
words_list.append(corpus[i].split(' '))
print(words_list)
count_list = list()
for i in range(len(words_list)):
count = Counter(words_list[i])
count_list.append(count)
print(count_list)
def tf(word, count):
return count[word] / sum(count.values())
def idf(word, count_list):
n_contain = sum([1 for count in count_list if word in count])
return math.log(len(count_list) / (1 + n_contain))
def tf_idf(word, count, count_list):
return tf(word, count) * idf(word, count_list)
for i, count in enumerate(count_list):
print("第 {} 个文档 TF-IDF 统计信息".format(i + 1))
scores = {word: tf_idf(word, count, count_list) for word in count}
sorted_word = sorted(scores.items(), key=lambda x: x[1], reverse=True)
for word, score in sorted_word:
print("\tword: {}, TF-IDF: {}".format(word, round(score, 5)))
4、TF- IDF 优缺点
优点: 简单快速,结果比较符合实际情况。
缺点: 单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多;无法体现词的位置信息;需要多个文档对比。
















 5490
5490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











