







0. 背景
论文地址:Deep Residual Learning for Image Recognition
代码地址:GitHub
这篇论文是 ILSVRC 2015 年冠军,由 MSRA 何凯明团队提出,提出了迄今为止最深的网络——152 层的神经网络构成分类器,并且提出解决随着层数增加,训练误差增大的方案。
1. 问题
- 深度学习随着层数增加,效果变好。举例:Alexnet是10层,VGG16,VGG19越来越好;
- 早期使用全连接网络时,有梯度消失/陡增现象(gradient vanishing/exploding),使用卷积层以及归一初始化、BN(划重点)后解决问题;
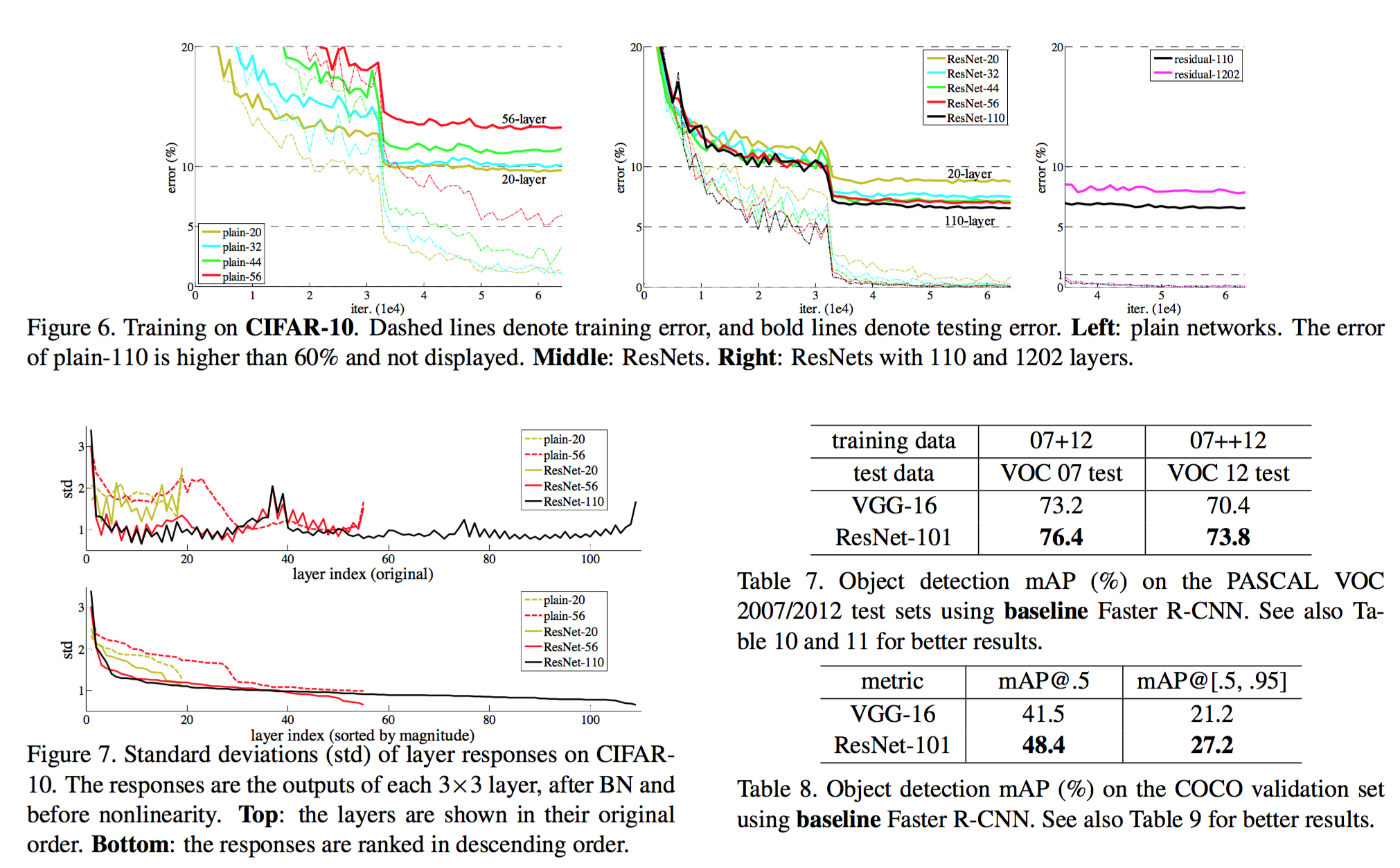
- 新的问题是准确率恶化问题(degradation),训练时神经网络收敛,随着层数的增加,训练误差和验证误差不是一直减小,在达到一定层数后,误差反而随之增长。如下图所示,本文着力解决这个恶化问题。
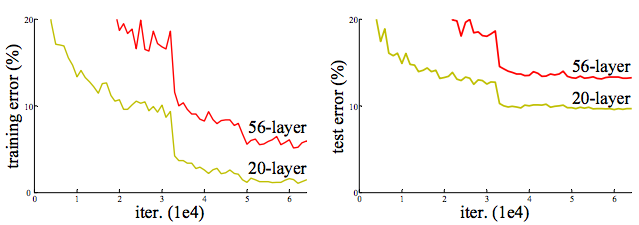
图片来自1
2. 贡献
- 解决了网络恶化问题,准确度随层数增加而增加
- 目前为止赢了 2015 年的 ImageNet 的 detection,localization,以及 COCO 数据集上的 detection 和 segmentation
- 实现简单,训练方便,方向传播使用 end to end 的 SGD,不用修改solver
- 不增加网络参数,可以看到 152 层的 Resnet 比 VGG-19 的网络参数还要少,计算复杂度降低
3. 方法
提出在浅层网络上加网络层,不应该增加误差,由此引出深度残差学习框架(deep residual network framework)。
以两层网络层为例,假设输入为 x,原本网络学习目标函数为
H(x)
,作者将这个目标函数分开成两部分,一部分是 x,另一部分为
F(x)
,于是有
H(x)=F(x)+x
这里的 x 直接由输入提供,网络学习部分转而变为 F(x) 。这样做的好处是如果下层的误差变大,网络会自动将 F(x)→0 处理。
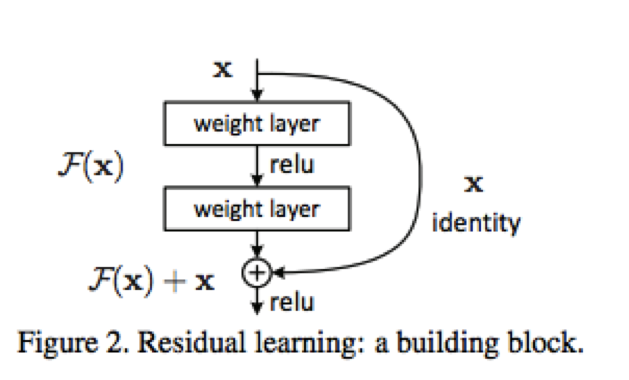
图片来自2
网络结构设计细节
- 使用 BN 训练,避免 gradient vanishing/exploding
- 没有全连接层,减少网络参数,缩短训练和测试用时
- 输入图片等比例 resize,短边随机取到 [256, 480],采样时取图片中心的 224 x 224 以及水平镜像,所有图片,相同像素位置均值为 0
- mini-batch size = 256
- learning rate 初始值为 0.1,发现误差曲线平了就除以 10,总共训练 60×104 个迭代
- weight decay: 0.0001
- momentum: 0.9
- 不用dropout
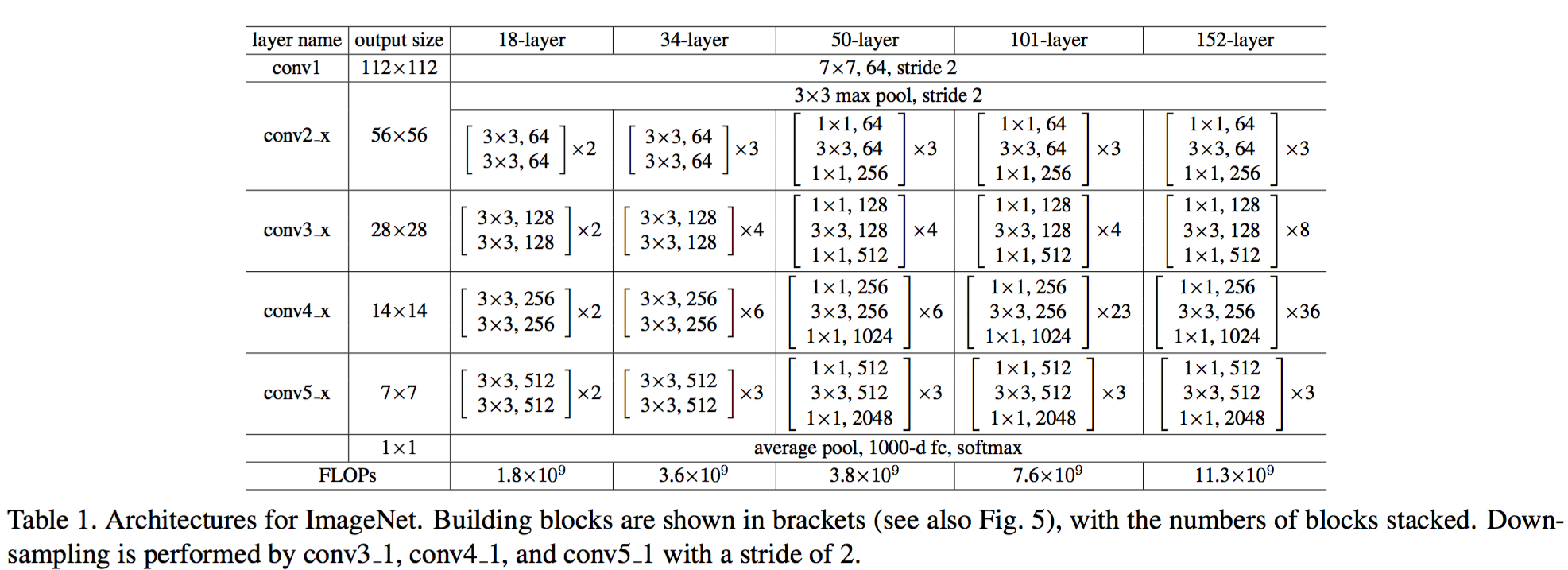
4. 实验结果
ImageNet 数据集
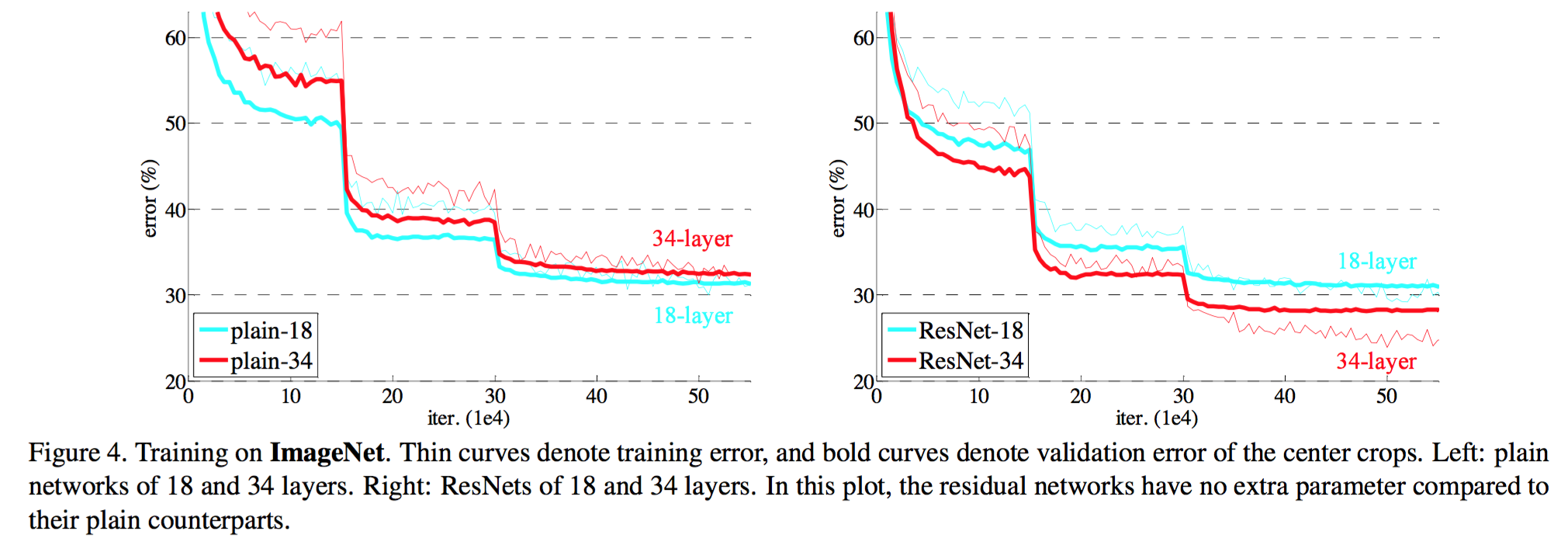
解决了 degradation 问题,如下图:
层数越多越准确,如下表
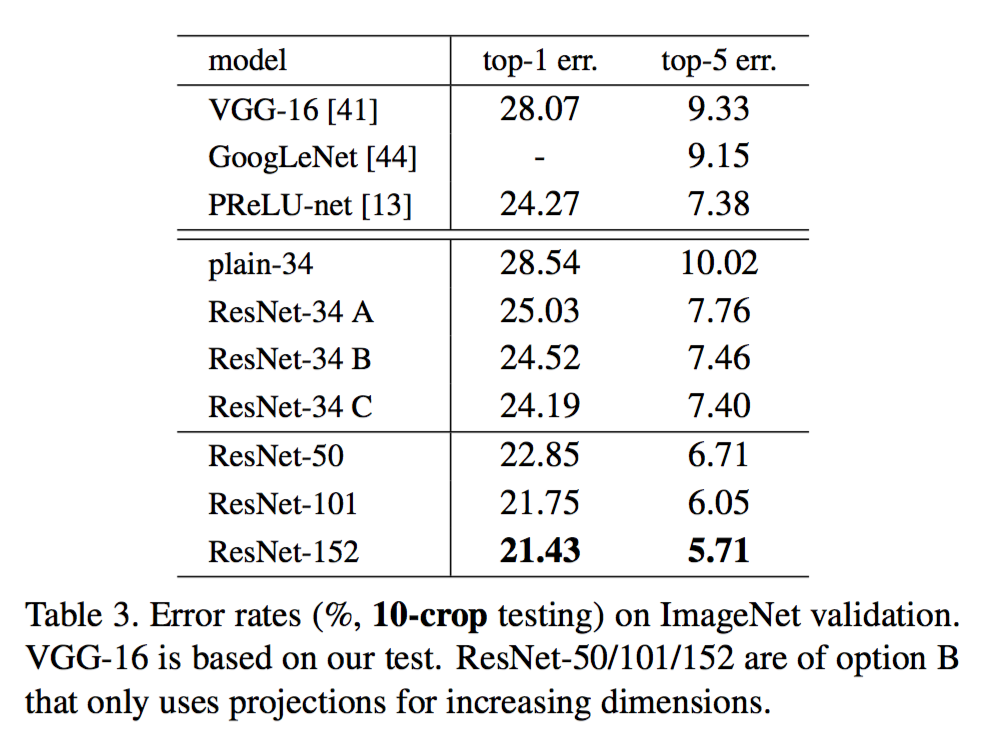
与其他方法对比
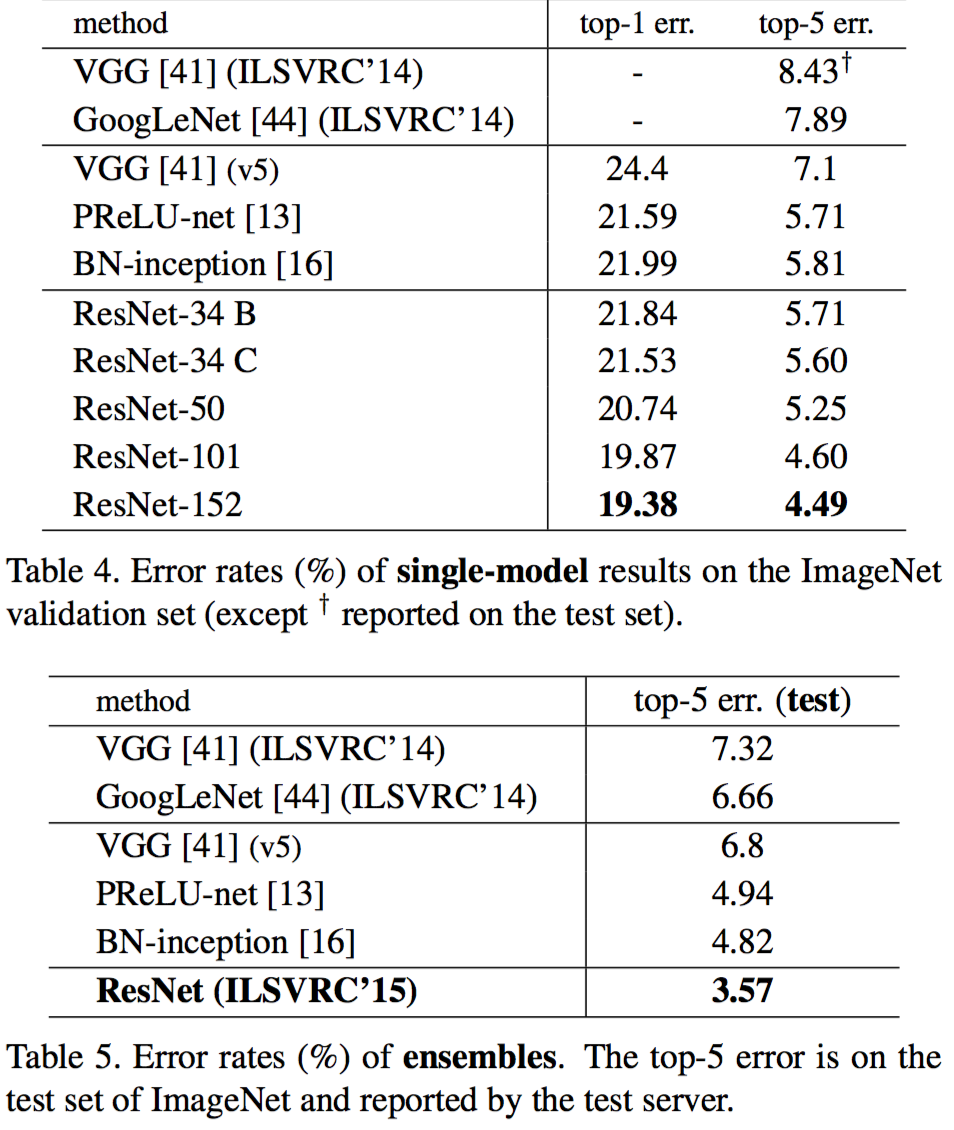















 564
564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









