








Multi-view Face Detection Using Deep Convolutional Neural Networks, ICMR 15.
将Alexnet转成FCN的形式(也就是227*227的输入会输出1*1的heat map),将detection问题转为classification问题。

很简单,对每个region/proposal/sliding window进行分类
测试时,whole image as input,获得对应的全图的heat map( Each point in the heat-map shows the CNN response, the probability of having a face, for its corresponding 227*227 region in the original image. )。
至于怎么从heat map来获取到最终的face的detection结果,这个还有待研究。
当然少不了NMS(how to apply the nms onto the heat maps?)
笔者是这样认为的:应为heat map的每个pixel都有它对应于输入图像的区域(感受野),所以:
1 对heat map进行threshold
2 对剩下的pixels,获取其bounding box(即上面提到的感受野)
3 根据score对pixels进行降序排序,然后NMS它们的bounding box
论文中提及到两种NMS的方式:
An overlap threshold of 0.3 gives the best performance for NMS-max while, for NMS-avg 0.2 performs the best.
According to this figure, NMS-avg has better performance compared to NMS-max in terms of average precision.

=====
loss用softmax loss
输入大小是227*227,采用不同的data argumentation的方式
对输入进行采样来保持正负样本在一定的比例内,如1:3(32张positive和96张negative)。
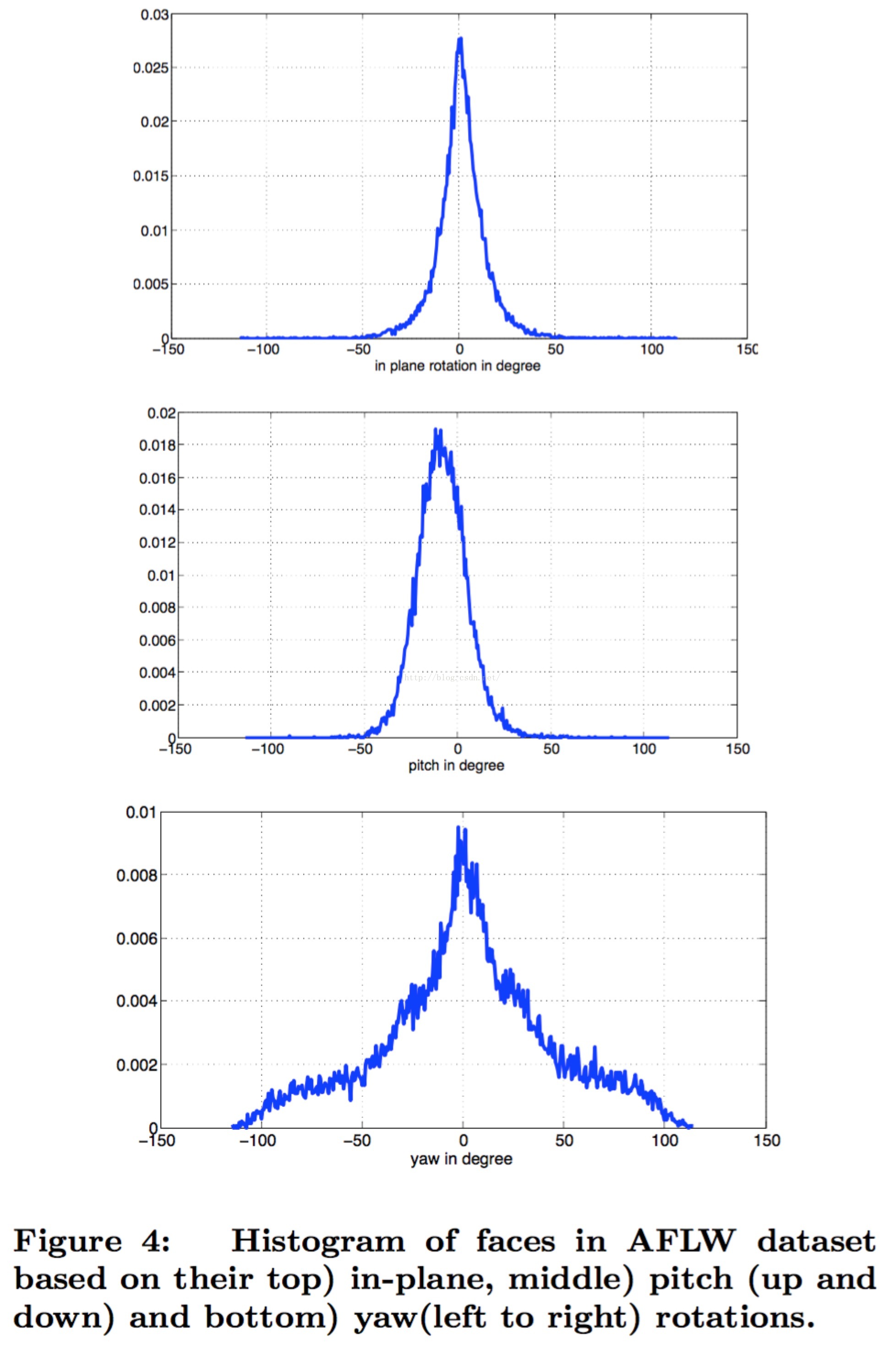
AFLW数据集(21k images & 24k faces)里的正负样本分布及其不平衡,正样本里的up-right、rotate、occluded的分布也不平衡。
可以通过sampling strategy和data argument的方式来缓解:
To increase the number of positive examples, we randomly sampled sub-windows of the images and
used them as positive examples if they had more than a 50% IOU (intersection over union) with the ground truth.
randomly flip
====
笔者认为这是把face(用bounding box)从原图中扣出来(crop),然后resize到227*227,作为输入,来训练Alexnet(finetuning)。 In this work we selected a sliding window approach because it has less complexity and is independent of extra modules such as selective search.
=====
测试时,将whole image作为输入,来获取whole image的输出heat map。
The heat-map shows the scores of the CNN for every 227*227 window with a stride of 32 pixels in the original image. We directly used this response for classifying a window as face or back- ground. To detect faces of smaller or larger than 227*227, we scaled the image up or down respectively。
笔者持怀疑态度:一般来说face的大小不会很大,会在30~80 pixels之间,把face的patch(尽管会包括一些绕着face的back ground)resize到227*227来训练模型,那么测试的时候,怎么从者227*227的sliding window(对应的score或者response很高,如0.99,也就是该窗口至少存在一个人脸)中找到一个face的bounding box,总不能把227*227当做face的bounding box吧?这是笔者的疑惑,先看看论文是怎么解决的?
1 We upscaled images by factor of 5 to detect faces as small as 227/5 = 45 pixels.
相当于将输入图像upsample到5*5倍,这样227*227的感受野变成了45*45,
这样一看人脸的框的大小为45*45还是蛮合理的。
2 为了处理多尺度的问题,对1)中上采样的图像进行缩放,其缩放比例是0.707,0.7937,0.8706,0.9056,1。
这样看,就是通过输入的金字塔来得到图像里的face的bounding box。蛮合理的!
=====
类似lingbo师弟和zhujin老大的做法,不过他们是直接设计一个感受野大小是49*49的小网络(49*49是标准脸的大小,这个网络将49*49的patch作为输入,输出1*1的heat map,测试过程和上面的一样,只是不需要将输入上采样到原来的5*5倍,而是直接将原图作为输入,而且尺度也是有较多个的,如19个尺度,从0.2到3之间变化)
=====
论文中一点比较诡异的是:bounding box的regression不起作用
(具体可以参考RCNN和SPPNet这两篇论文,另外bounding box的regression已经有DPM和OverFeat这两篇论文证实有效的)。
(论文中,regression的使用是在测试的NMS步骤之后)
论文作者认为是训练集和测试集的bounding box的分布不同导致,即在训练集上学好的bounding box的regressor不能很好泛化到测试集上。大部分的mismatch是side-view faces的情况。(嗯这样解释有点道理,可惜笔者没有想到更好的理由,哪位想到了,是否可以请教下?)
=====
为了和RCNN做对比,论文中用finetuned Alexnet的fc7作为特征,训练svm的face classifier,并同时训练bounding box的regressor。测试时,在bounding box的NMS在bounding box的regression之后。这个完全按照RCNN的来做,只是用得是AlexNet(即上面finetune的)和用得时Pascal Voc 2012的数据集。下面附上效果:

=====
最后附上自己做的人脸检测的效果:

笔者在FDDB上的效果(见malong)(这里没有跟小米(Bootstrapping Face Detection with Hard Negative Examples,arxiv 16.08(download))的比,毕竟还是有一定的margin的,笔者已经哭晕在厕所了)


=====
如果这篇博文对你有帮助,可否赏笔者喝杯奶茶?
















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









