







论文链接:SSD: Single Shot MultiBox Detector
代码: SSD
摘要:
作者提出了一个单一的深度神经网络(SSD)来做图像的目标检测。网络预测出的边界框由一系列默认框组成,这些默认框位于每个特征图位置上并且有不同的横纵比和尺度。在预测时,网络为每个默认框中每个目标类别的存在生成评分,并对该框进行调整以更好地匹配对象形状。此外,该网络结合了来自不同分辨率的多个特征图的预测结果,以自然地处理不同大小的目标。相对于需要对候选区域的方法,SSD完全消除了候选区域生成和子序列像素或特征重采样阶段,并将所有计算封装在一个单一的网络中。这使得SSD非常容易训练并且可以直接整合到需要检测功能的系统中。在PASCAL VOC、MS COCO和ILSVRC数据集上的实验结果表明,SSD具有与使用候选区域步骤的方法一样的准确性,而且速度更快,同时SSD模型训练和推理使用的是一个整体框架。与其他一阶段方法相比,即使在较小的输入图像尺寸下,SSD也具有更高的精度。对于300x300输入,SSD在Nvidia TitanX上以58帧每秒的速度在VOC2007测试中实现了72.1%的mAP,而对于500x500输入,SSD实现了75.1%的mAP,性能优于最先进的R-CNN模型。
思路:
摘要提到,SSD不仅快,而且精度高,简要说一下作者的设计思路:
- 速度快:相对于R-CNN系列来说,不需要候选区域生成这一步了,跟YOLO一样,将边界框回归当做回归问题处理,所以SSD比R-CNN系列方法快,但是相比于YOLO,其实没什么速度优势,还有就是作者计算FPS(模型每秒能处理图像的帧数)的方式有点特别,并不是一张张测出来的,而是并行测出来的,就是一次测8张,然后用总耗时除以8得到FPS。我之前做一个车道线检测项目时,用的是TensorFlow,单独测一张图像用时和并行测10张图像,计算出来的FPS相差2倍多。
- 精度高:在设置默认框的时候采用了多尺度和多横纵比,并且在不同的特征图上进行检测任务。多尺度的好处在于,默认框的大小不一样,小目标和大目标可兼顾;多横纵比的好处在于,默认框的宽高比多样,多于检测一些有较大横纵比的目标有较好效果,其实就是能为这些目标匹配到更大iou的默认框;在不同特征图上进行检测任务的好处在于,可以结合特征图的低维特征和高维特征,可以使定位更准。综上三点,对于小目标效果更好,对于低分辨率图像,效果也不错。
网络架构:

SSD方法基于一个前向卷积网络,该网络生成一个固定大小的边界框集合和这些框中对象类实例存在的得分,然后执行一个非最大抑制步骤来生成最终检测。网络前面的层是用于图像分类的架构,就是在分类层前面任何地方将网络截断,前面这些层作为SSD的主干网络。然后添加一些辅助结构到主干网络中去做目标检测任务。添加的辅助结构如下:
- Multi-scale feature maps for detection: 在截断后的基网络的末尾添加卷积特征层。这些层的大小逐渐减小,可以在多个尺度上做检测,每个尺度的卷积层做的检测结果都是不同的(论文里面提到的多尺度,有两种,分别是特征图大小的尺度和默认框大小的尺度),而Overfeat[和YOLO仅用了一个尺度特征图来做检测。作者其实就是使用更底层更细粒度的信息来做检测任务,实验结果表明,这操作将检测性能大概提高了4个点。
- Convolutional predictors for detection:这个很好理解,就是使用卷积层来做最后边框和置信度的预测,YOLO使用的是全连接层。要注意的是,这些卷积层在图2中叫做,额外卷积层,添加在主干网络后面的,不止一个。输出生成类别的得分和相对于默认框坐标的形状偏移量。
- Default boxes and aspect ratios:
如图一所示,默认框就是在特征图的每个位置上,按照不同的宽高比和尺度设置一些固定边框。宽高比作者给了6组,分别是:1,2,3,1/2,1/3. 默认框的尺度则是根据特征图的数量来决定的,计算公式如下:
m是特征图的数量,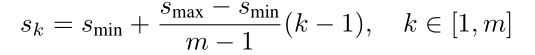
表示第k个图的默认框尺度,作者文中
取0.2,
取0.95.这样就能使每个特征图上的默认框尺度均匀增加。
目标函数:
![]()
分为两部分,第一部分是真实坐标框和默认框的偏移误差和R-CNN一样,采用的是LI损失函数,第二部分是目标类别置信度误差,使用的是softmax损失函数,设置为1。
Matching strategy:
在训练的时候,要将目标框的真是标注和默认框关联起来,对于每个真实标注框,都是从所有位置、纵横比和比例的默认框中选择。首先,每个真实标注都会从所有的默认框中选取 jaccard overlap最大的默认框作为匹配,然后从剩下默认框中选取 jaccard overlap大于0.5的也作为匹配。这样做的好处第一可以保证至少有一个默认框与真实标注匹配,二是每个真实标注框可以预测多个置信度高的默认框,而不是仅仅选取最大的那个。
Hard negative mining:
在匹配步骤之后,大多数默认框都是没有匹配到真实标注框的(叫做负样本,匹配到的叫正样本),特别是当可能的默认框尺度很大时。这使得正负样本差距太大。作者没有使用所有的负样本,二是对负样本置信度进行排序,选取置信度高的负样本用于训练,使正负样本的比例最多为3:1。这将导致更快的优化和更稳定的训练。
Data augmentation:
极其重要,将性能提高了将近7个点!!!,主要是随机剪切和横纵比缩放。
实验结果:


从这个结果可以看出,使用较低层的特征来做检测,效果提升了近4个点,效果很明显,而数据增强,效果提高了近7个点,其它的操作也有性能提升,但是不明显。作者得出的结论是:用于检测的特征图越多越好,默认框宽高比越多越好,空洞卷积更好且更快。



从时间分析的可以看出,SSD确实快,但是作者的计算方式,是并行的,一次测8张,然后算平均。这样测出的速度性能是没法应用于视频流的,处理视频流只能一帧一帧处理。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









