







维基百科对深度学习的精确定义为“一类通过非线性变换对高复杂性数据建模算法的合集”。因为深层神经网络是实现“多层非线性变换”最常用的一种方法,所以在实际中基本可以认为深度学习就是深层神经网络的代名词。从维基百科给出的定义可以看出,深度学习有两个非常重要的特性——多层和非线性。那为什么要强调这两个性质?下面将给出详细解释。
1.1线性模型的局限

从这个例子可以看到,虽然这个神经网络有两层(不算输入层),但是它和单层神经网络并没有什么区别。以此类推,只通过线性变换,任意层的全连接神经网络和单层神经网络模型的表达能力没有任何区别,而且它们都是线性模型。然而线性模型能够解决的问题是有限的。这就是线性模型最大的局限性,也是为什么深度学习要强调非线性。
1.2激活函数实现去线性化
之前样例中将神经元结构的输出置为所有输入的加权和,这导致整个神经网络是一个线性模型。如果将每一个神经元(也就是神经网络中的节点)的输出通过一个非线性函数,那么整个神经网络的模型也就不再是线性的了。这个非线性函数就是激活函数。下图展示了加入激活函数和偏置项之后的神经元结构:
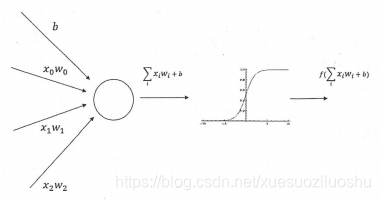
其数学定义为:
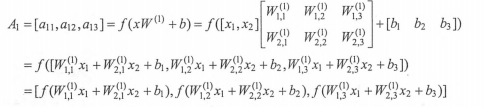
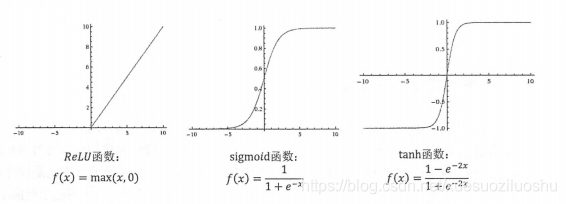
与之前定义的线性函数相比有两个改变。第一是新的公式中增加了偏置项(bias),偏置项是神经网络中非常常用的一种结构。第二个是每个节点的取值不再是单纯的加权和。每个节点的输出在加权和的基础上还做了一个非线性变换。下图显示了几种常用的非线性激活函数的函数图像:
此处加入激活函数后前向传播算法的计算省略,直接以下图网络为例,看TensorFlow如何实现
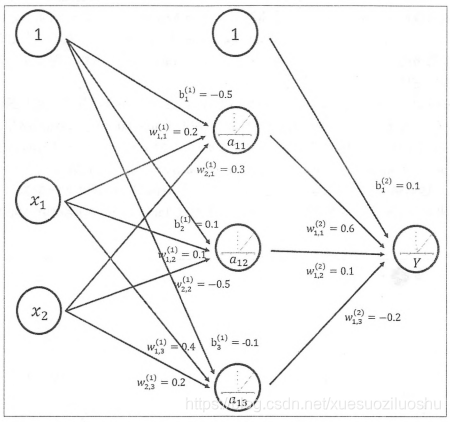
目前TensorFlow提供了7种不同的非线性激活函数,tf.nn.relu、tf.sigmoid和tf.tanh是其中比较常用的几个。TensorFlow也支持使用自己定义的激活函数。以下代码展示了如何通过TensorFlow实现上图前向传播算法。
a=tf.nn.relu(tf.matmul(x,w1)+biases1)
y=tf.nn.relu(tf.matmul(a,w2)+biases2)
以上代码可以看出,TensorFlow可以很好支持使用了激活函数和偏置项的神经网络。














 1243
1243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









