







定义:聚类分析或聚类是对一组对象进行分组的任务,使得同一组(称为集群)中的对象(在某种意义上)彼此之间比其他组(集群)中的对象更相似(在某种意义上)。
应用领域:模式识别,图像分析,信息检索,生物信息学,数据压缩,计算机图形学和机器学习。
内涵:聚类分析并不是一种特定的算法,而是要解决的一般任务,这些算法在理解什么构成集群以及如何有效地找到它们存在的显著差异。
集群成员之间距离较小的组,数据空间的密集区域,间隔和特定的分布,如此依赖,聚类可以被表述为一个多目标优化问题。“集群”通常无法被精确定义,共同的特点是大家都是一组对象。典型的集群模型包括以下几个方面。
连通性模型:例如层次聚类基于距离联通性构建模型。
层次聚类是一种聚类分析方法,包括凝聚和分裂两种类型。通常拆分与合并是通过贪婪的方式实现的,结果通常以树状图的形式呈现。HAC时间复杂度为O(n^3),内存Ω(n^2)。为了决定拆分或者合并集群,需要测量观测集合之间的差异。通常利用适当的度量和链接标准实现。
公制:适当的度量将影响集群的形状。因为在一个度量下某些元素可能比另一个更近。例如,在二维中,曼哈顿距离度量下,(0,0)与(0.5,0.5)之间的距离和(0,0)与(0,1)之间的距离是相同的,而欧几里得距离度量下后者更大一点。通常的一些距离度量包括:
| 欧几里得距离 | 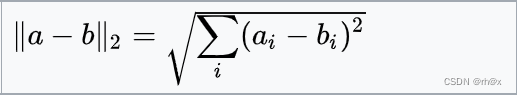 |
| 平方欧里得距离 | 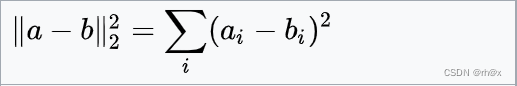 |
| 曼哈顿距离 | 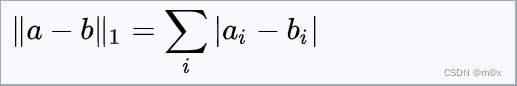 |
| 最大距离(切比雪夫距离) | 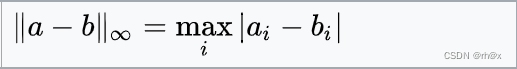 |
| 马氏距离 | 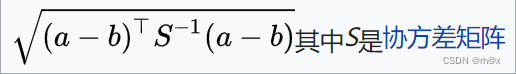 |
| 汉明距离 | 两个字符编码对应位置不同的位数 |
| Levenshtein距离 | 编辑距离 |
另外,存在其他几种差异度量。特别是基于相关的距离-Pearson,Eisen cosine,Spearman,Kendall相关距离。1-相关度作为距离不够严格,可以用平方根作为度量(满足勾股定理)。
联动标准:链接标准将观测值集之间的距离确定为观测值之间成对距离的函数。
| 最大或完全链接 | 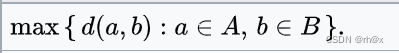 |
| 最小或单链接 | |
| 未加权平均链接 | 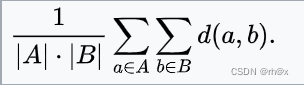 |
| 加权平均链接 | 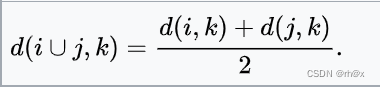 |
| 质心链接 | |
| 最小能量链接 | 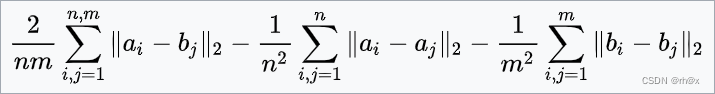 |
| 集群内方差总和 | - |
| 被合并的集群的方差增加(ward)用Lance-Williams算法,是一个递归算法 | 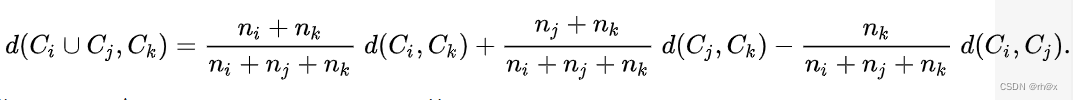 |
| 候选集群从相同分布函数(vlinkage)产生的概率 | - |
| K最近邻上的入度和出度的乘积 | - |
质心模型s:k-means算法用单个均值向量表示每个集群
K均值聚类是一种矢量化方法,最初来自信号处理,旨在将n个观察值划分为k个簇。其中每个观测值属于具有最近均值的簇,作为集群。这导致将数据空间划分为Voronoi单元。
k均值聚类最下滑聚类内方差。这个问题很困难(NP-hard),有效的启发式算法可以快速有脸到局部最优值。
说明:给定一组观测值(x1,x2,x3,...,xn),其中每个观测值都是d维向量。k均值旨在将n个观测值划分为k个集合,以最小化簇内平方和(WCSS)。
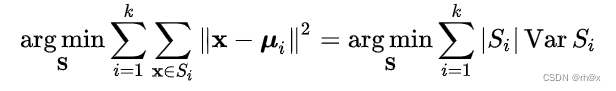
分布模型:集群使用统计分布建模,例如期望最大化算法使用的多元正太分布
在统计中,期望最大化(EM)算法是一种迭代方法,用于朝朝统计模型中参数的最大使然估计,其汇总模型依赖于为观察到的潜在变量。
EM迭代在执行期望E步骤和最大化M步骤之间交替,该步骤为使用当前参数估计的对数似然的期望创建函数,该步骤计算最大化预期对数的参数-发现的可能性E步。然后,使用这些参数来确定下一个E步骤的潜在变量分布。
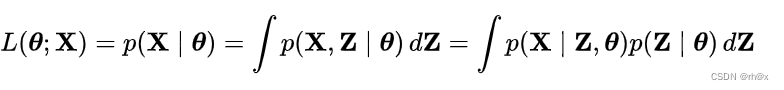
密度模型:集群使用数据空间中链接的密集区域,例如DBSCAN和OPTICS
用于识别聚类结构的排序点(OPTICS)是一种用于在空间数据中查找基于密度的聚类算法。与DBSCAN算法思想接近,但解决了DBSCAN的弱点之一:在不同密度的数据中检测有意义的集群的问题。数据库的点是线性排序的,使得空间上的点成为排序中的邻居。此外,每个点存储一个特殊的距离,该距离表示一个集群必须接受的密度,以便两个点都属于同一个集群。
子空间模型:在双聚类中,聚类使用聚类成员和相关属性进行建模
对行和列同时进行聚类。
基于图的模型:一个clique,即图的子集,使得子集中的每个节点都由一条边连接,可以认为是集群的原型形式。完全联通性要求的松弛称为准团,如HCS聚类。
HCS是一种基于图连同性进行聚类分析的算法。它通过在相似图中表示相似的数据,然后找到所有高度连接的子图来工作的

















 1497
1497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









