







局部特征聚合描述符(vector of locally aggregated descriptors,VLAD)
一、局部描述符聚合:非概率的Fisher Kernel
对于视频,每帧的局部描述符{x1,…,xi,…},在大规模视频搜索中不可能将他们一次都存在内存中,即使每个局部描述符都只需要几比特大小,但是一般来说,每帧都会有数百上千的局部描述符。因此,我们将这些局部描述符聚合到一个单独的向量中去。我们利用由Perronnin[1]等人引进的Fisher Kernel对于图像表示的变形。得到的结果向量,叫做局部聚合描述符(VLAD),它提供了一种简洁有效的图像表达。假设利用k-means聚类已经学习得到的码本(codebook)和k个中心(c1,…,cj,…,ck),我们就获得一帧的VLAD描述符,记作u,具体过程如下:
(1)和词袋特征表达一样,帧的每个局部描述子xi赋给码本中离它最近的中心,然后得到量化后的索引 :
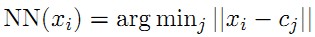
(2)将描述符集合指派给一个中心cj,向量uj通过这些描述符和他的中心的差的累积和获得。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









