







paper: Key Points Estimation and Point Instance Segmentation Approach for Lane Detection
code: https://github.com/koyeongmin/PINet
dataset: Tusimple-dataset
Advantage:
-
The arbitrary number of lanes;
-
lower number of FP
二.方法介绍

1)方法
(1)generate exact points on the lanes ( resizing layer + 2 hourglass blocks)
(2)cluster points as a point cloud instance segmentation(loss func same as SPGN, point cloud instance)
(3)post-process (remove error lanes, a instance should consist of only one smooth lane)
2)网络结构PINet ( Point Instance Network )

(1)resizeing layer
Conv + max pooling, 512x256 → 64x32 / 32x16
(2)feature extraction layer
Architecture: 2 hourglass blocks, and each block has 3 output branches
output grid size = the resized input size
其中,1 hourglass block architecture:

(和 U-net结构相似)
3)网络layer setting

4)loss function
loss func from SPGN(3个分支)
a. confidence branch:
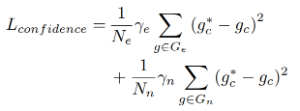
b.offset branch
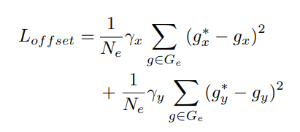
c.feature branch
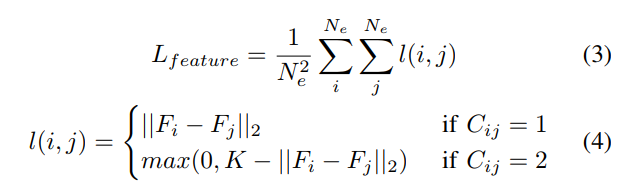
3)虽然使用了2个hourglass blocks,但是由于 hourglass input size 为3216或6432,因此,计算量并不会非常大。
4)每个hourglass block都会有一个loss的计算,这个与 stacked hourglass network一样。3)虽然使用了2个hourglass blocks,但是由于 hourglass input size 为3216或6432,因此,计算量并不会非常大。
4)每个hourglass block都会有一个loss的计算,这个与 stacked hourglass network一样。## 一.概述
d.Total loss
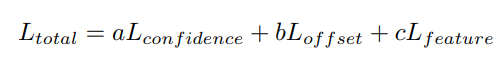
5)post-process


后处理过程: 就是一个再次对点进行聚类的过程,类似于 RANSAC, but 它是基于直线方程,可参考性不大。

三.实验效果
1)可视化效果

2)评测方法和指标
(1)方法:和Tusimple 数据集的方式一样,计算点的acc,以及车道线的FP和FN
ACC: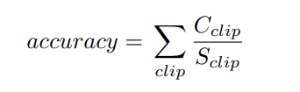
C_clip 表示:the number of correct predicted points
S_clip 表示:the number of GT points
(The evaluation of tuSimple dataset require exact x axis value for some fixed y axis value, and we apply simple linear interpolation to find corresponding points for the given y values. Because the distance between predicted points is close, we can estimate accurate results without any complex curve fitting method.)
FP和FN: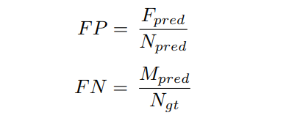
F_pred 表示:FP lanes数量
N_pred 表示:predicted lanes数量
M_pred 表示:FN lanes数量
N_gt 表示:GT lanes数量

四.总结
-
1)通过resize layer和feature extraction layer获取不同车道线实例的点,使用2个关键点检测网络hourglass block提取车道线的点,然后使用点云实例分割的方式,使用点云实例分割网络的SPGN网络的loss函数作为损失函数,获得不同实例(车道线)的点。
-
2)为了减少FP,采用进一步聚类的方式(类似RANSAC方式),对每个实例的点进行聚类,滤出error的点,最终获得每个实例上的点。
-
3)虽然使用了2个hourglass blocks,但是由于 hourglass input size 为3216或6432,因此,计算量并不会非常大。
-
4)每个hourglass block都会有一个loss的计算,这个与 stacked hourglass network一样。















 2034
2034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









