






文章目录
论文复现
https://github.com/charlesq34/pointnet
安装的时候注意tensorflow的版本,代码是1.0.1版本的。python3.7+的版本不支持tensorflow2.0以下的。
cuda的版本是10.0
conda create -n pointnet python=3.6
conda activate pointnet
#pip install tensorflow==1.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tensorflow-gpu==1.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
sudo apt-get install libhdf5-dev
sudo pip install h5py
python train.py
在训练了:
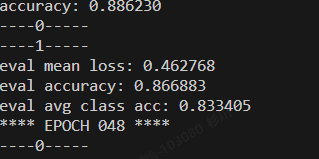
论文研读
1.动机
点云数据格式不规则,大多数研究者将其住转为3D体素网格或者集合图像,但是渲染数据不必要且造成问题,所以提出一种网络直接利用点云,可以进行部件分割、目标分类、场景理解等。
2.模型结构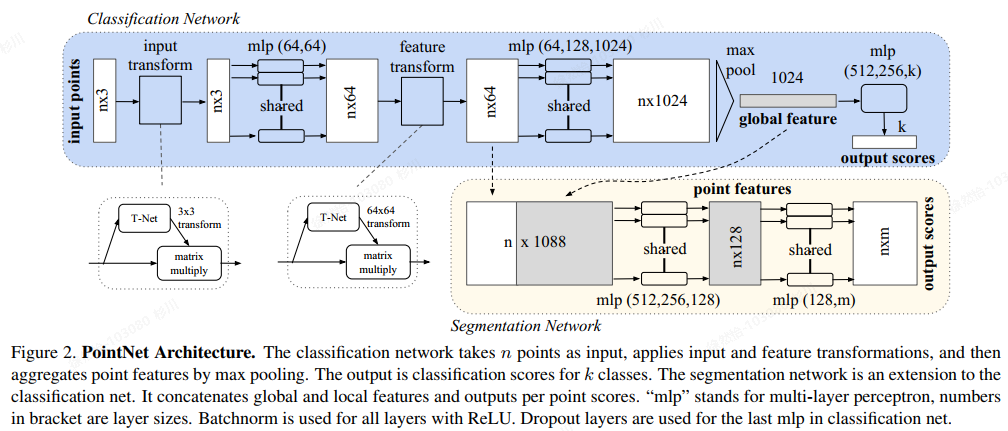
分类网络和分割网络。对于分类网络,输入n个点,提取特征然后用最大值池化聚合点的特征,输出是每一类的分数。分割网络将全局特征和局部特征拼接,输出每点的分数。主要有三个模块,最大值池化作为对称函数处理输入的无序数据,全局和局部的拼接结构是将全局点云特征加到每个点云的特征再进行特征提取。对齐网络保证模型的对特定空间转换的不变性。
整体流程:
1、输入为一帧的全部点云数据的集合,表示为一个nx3的2d tensor,其中n代表点云数量,3对应xyz坐标。
2、输入数据先通过和一个T-Net学习到的转换矩阵相乘来对齐,保证了模型的对特定空间转换的不变性。
3、通过多次mlp对各点云数据进行特征提取后,再用一个T-Net对特征进行对齐。
4、在特征的各个维度上执行maxpooling操作来得到最终的全局特征。
5、对分类任务,将全局特征通过mlp来预测最后的分类分数;对分割任务,将全局特征和之前学习到的各点云的局部特征进行串联,再通过mlp得到每个数据点的分类结果。
图中的input transform和feature tansforms是什么?
为了保证输入点云的不变性,作者在进行特征提取前先对点云数据进行对齐操作(input tansform)。对齐操作是通过训练一个小型的网络(T-Net)来得到转换矩阵(3x3),旋转矩阵和输入点云数据相乘实现对齐。feature tansforms也是T-Net获得的64x64的转换矩阵,对特征进行对齐。
该模型一直在做点之间特征的单独提取,除最后一层max pool获取全局信息外,没有将点与其周围的点进行融合,提取局部特征。这一点PointNet++里进行了解决。
3.实验效果
该模型代码里有三个train.py。最外层的是训练室内室外场景的分割 训练模型对三维形状的点云进行分类 ,里面的类别有飞机、汽车等;part_seg目录下的train.py是部件分割,例如桌子会把桌面和桌腿分别分割出来。sem_seg里面的分割是针对室内场景的分割。
https://github.com/nikitakaraevv/pointnet

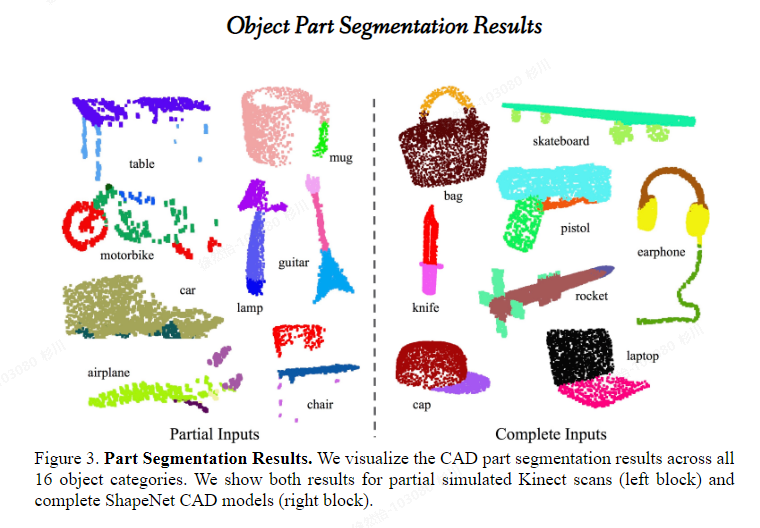

实验数据:

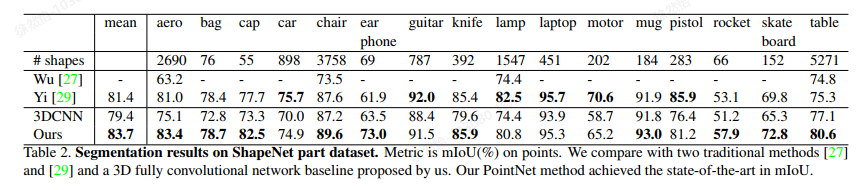
4.总结
本文的模型2017年提出,是直接利用3D点云用来分类和分割。对于分割任务,将单个点云的特征和全局的特征拼接再提取特征,涉及到对称函数(max pool)解决无序数据问题、全局和局部特征的拼接以及对齐网络。
参考:
https://zhuanlan.zhihu.com/p/336496973
代码研读
模型什么时候保存,保存到哪里?
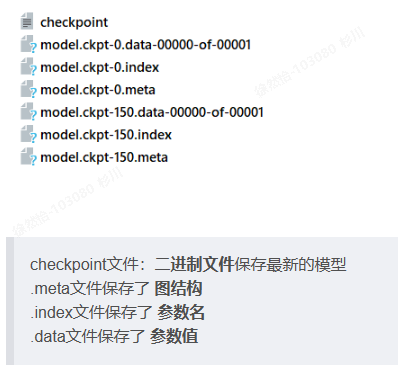
现在的epoch是250轮,当训练到10的倍数就将模型保存到Model saved in file: log/model.ckpt。但是目录下没有model.ckpt,倒是有:

这三个文件分别表示的是什么,在代码哪里对应的?
代码中使用的是tf.train.Saver()类的save(sess,ckpt文件目录),saver()和restore()只保存了session中相关变量对应的值,不涉及模型的结构。Saver的作用是将我们训练好的模型的参数保存下来,以便下一次继续用于训练或测试。Restore是将训练好的参数提取出来。saver.restore()回根据 ‘model.ckpt-n’ 自动寻找参数名–值文件进行加载 基于checkpoint文件(ckpt)加载参数时,实际上就是用Saver.restore取代了initializer的初始化

模型训练的数据集?
ModelNet10和ModelNet40都是分类的数据集。(https://modelnet.cs.princeton.edu/)

语义分割模型下载数据集进行训练,但是sh download_data.sh报错。

手动下载数据集进行解压,然后训练python train.py,数据集目录结构长这样:
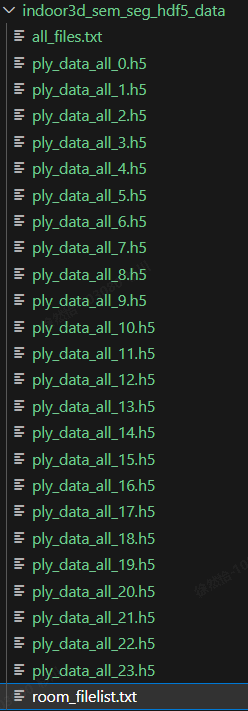
输入的是.h5格式。一共有13个类别。
H5文件是层次数据格式第5代的版本(Hierarchical Data Format,HDF5),用以存储和组织大规模数据。H5将文件结构简化为两个主要的对象类型,数据集dataset,就是同一类型数据的多维数组;组group,一种容器结构,可以包含数据集和其他组。对每一个dataset而言,除了数据本身之外,这个数据集还有很多属性信息,同事支持存储数据集对应的属性信息,所有的属性信息的集合称metaData。
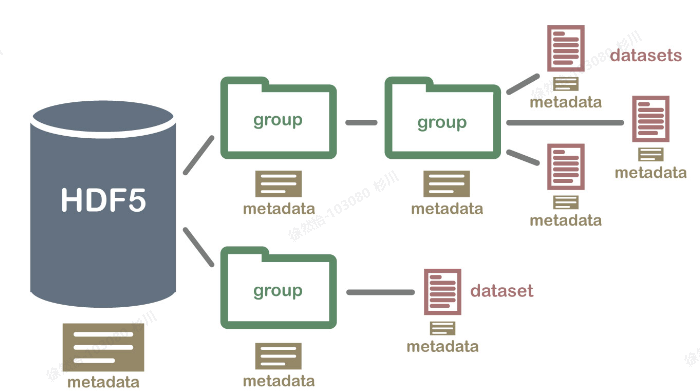
h5py文件是存放两类对象的容器,数据集(dataset)和组(group),dataset类似数组类的数据集合,和numpy的数组差不多。group是像文件夹一样的容器,它好比python中的字典,有键(key)和值(value)。group中可以存放dataset或者其他的group。”键”就是组成员的名称,”值”就是组成员对象本身(组或者数据集)。https://blog.csdn.net/YYY_77/article/details/118269666(该链接是将原图和label转为h5文件)
下载的数据集indoor3d_sem_seg_hdf5_data目录下主要就是h5格式的文件,all_files.txt是这些h5文件的位置。
room_files.txt里面的内容长这样:
下载好这个数据集就可以直接训练了。
如果要准备自己的HDF5数据,要先下载3D室内解析数据(S3DIS),用python collect_indoor3d_data.py把数据重组再运行gen_indoor3d_h5.py来生成HDF5文件。
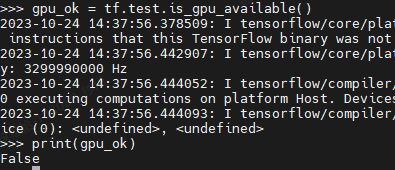
为什么是在CPU上运行的?运行的时候有输入gpu号
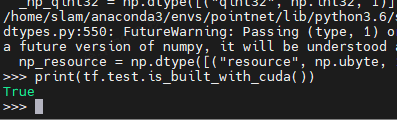
因为安装的tensorflow是cpu版本。验证tensorflow是cpu还是gpu的方法:
pip install tensorflow-gpu==1.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple

为什么在4个GPU上都在运行?
如何测试模型的语义分割的效果?

1.下载好数据集解压,放在data目录下;
下载S3DIS数据集用来测试和可视化。
https://cvg-data.inf.ethz.ch/s3dis/

2. 运行collect_indoor3d_data.py。
collect_indoor3d_data.py是读取文件夹中的每一个文件,把文件处理为数据标签文件(每一行是xyzrgbl,l是什么?)并调用indoor3d_util.py中的函数进行保存。
indoor3d_util.collect_point_label(anno_path, os.path.join(output_folder, out_filename), 'numpy')
在这一步,如果把S3DIS数据集生成HDF5文件,就要运行gen_indoor3d_h5.py,这个函数读取上一步生成的.npy文件得到h5文件和room_filelist.txt。不过这里,该数据集用来测试不用生成h5。
Area_5/hallway_6中多了一个额外的字符,不符合编码规范,需要手动删除。经查找具体位置为Stanford3dDataset_v1.2_Aligned_Version\Area_5\hallway_6\Annotations\ceiling_1.txt中的第180389行数字185后。windows下建议使用EmEditor打开文件,会自动跳转到该行,数字185后面有一个类似空格的字符,实际上不是空格,删掉然后重新打一个空格就可以了。

3.运行batch_inference.py进行测试。
参数中num_point、dump_dir、no_clutter的意思?

num_point点云的数目、错误分类的点云会被保存在dump目录下,通过将点云渲染为三视图图像来可视化点云。
分割模型训练好(基于GPU):
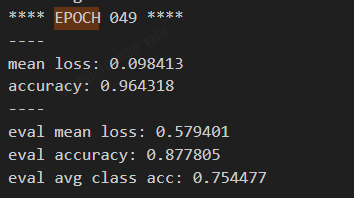
运行指令:
python batch_inference.py --model_path log6/model.ckpt --dump_dir log6/dump --output_filelist log6/output_filelist.txt --room_data_filelist meta/area6_data_label.txt --visu
报错:unsupproted operand type(s) for +:‘range’ and ‘list’
只需强制将range转为list类型即可
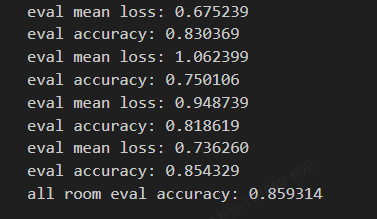
以下是测试生成的文件,准确率在85.9%。
怎么看可视化的结果?
dump中有obj文件,可以用CloudCompare打开看点云数据。

用CloudCompare打开pred.txt文件看点云数据。
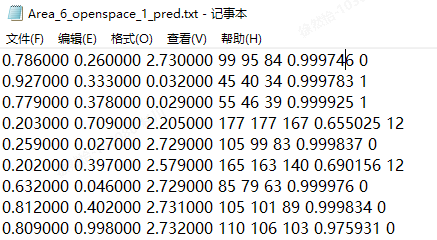
这里每一列代表什么意思?
前3列是x、y、z,中间3列RGB(大概率是),倒数第二列分类的最大值,最后一个是分类的标签。

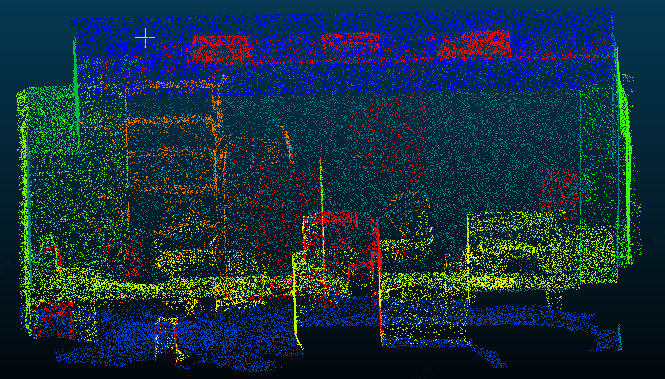
原图是什么样的?分割成了什么类型?
结论:原图太大了下载不太现实,分割的类型就是txt最后一列。
S3DIS数据集是包含真实标签的3D点云数据,这些3D点云包含在2D-3D-S数据集中。2D-3D-S数据集(https://github.com/alexsax/2D-3D-Semantics)是从3个不同的建筑里6个大型室内区域共6000平方米的区域内采集的,包含7w张RGB图片,还有对应的深度图、表面重建、语义注释、全局XYZ图和相机信息。数据集的大小有全局xyz的图片共766G,没有全局xyz的图片大小为110G。

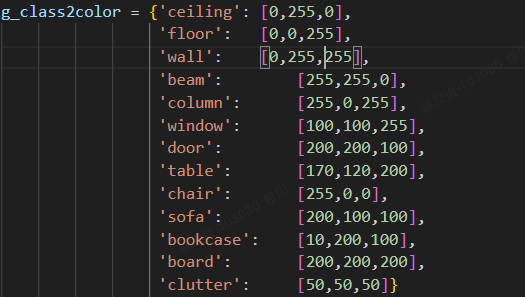
代码里有写什么颜色对应什么种类:
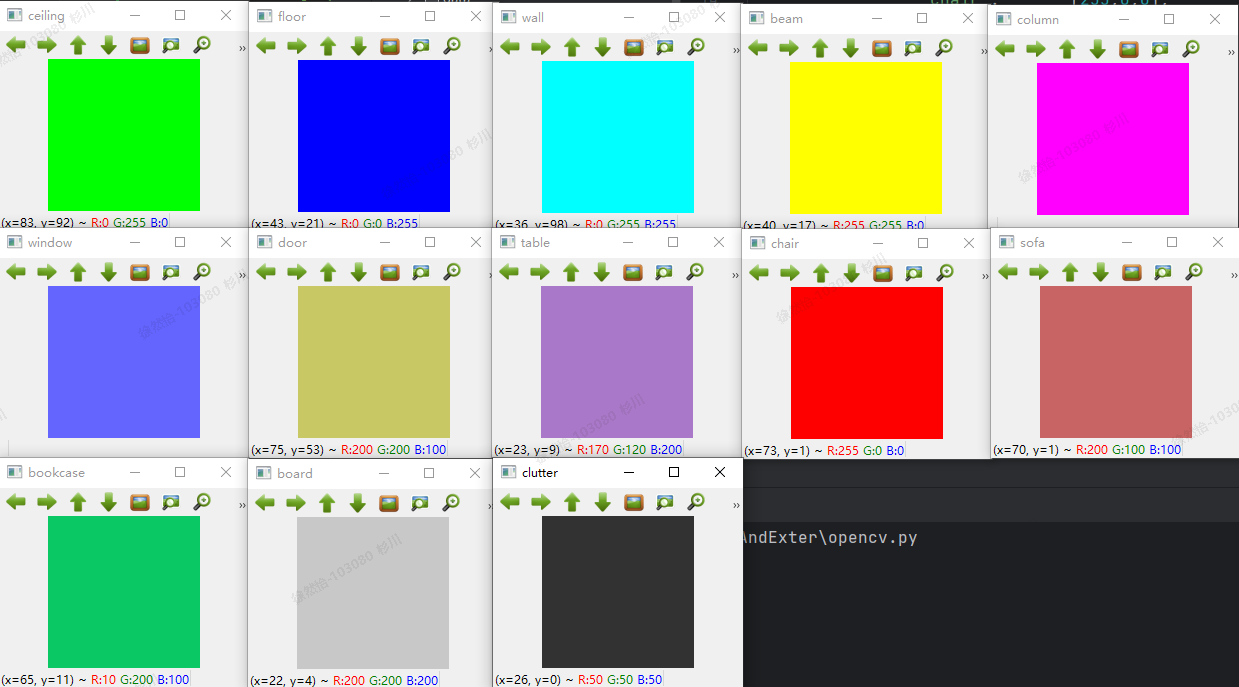
用Github推荐的MeshLab看可视化效果:
真实标签:

分割模型的预测结果:

分割模型训练读入.H5格式文件,那模型测试是读入什么格式的数据?
npy文件格式
理一下分割模型训练测试整体流程
要训练分割模型并进行效果测试,下载indoor3d_sem_hdf5_data数据集到sem_seg目录下,里面是一些h5文件用来训练模型。模型训练好之后要进行测试和可视化,要下载Stanford3dDataset_v1.2_Aligned_Version数据集,运行collect_indoor3d_data.py,把数据集里面的txt文件生成.npy文件,(此时还可以运行gen_indoor3d_h5.py将生成的.npy文件生成为h5文件),运行batch_inference.py进行测试和可视化。
如何测试模型的分类效果?
点云分类模型训练好(基于CPU):
数据集是modelnet40_ply_hdf5_2048。
直接运行python evaluate.py --visu报错:
报错1:没有scipy库
pip install scipy -i https://pypi.tuna.tsinghua.edu.cn/simple
报错2:没有PIL库
pip install pillow -i https://pypi.tuna.tsinghua.edu.cn/simple
报错3:没有matplotlib
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
报错4:AttributeError: module ‘scipy.misc’ has no attribute imsave
pip install imageio -i https://pypi.tuna.tsinghua.edu.cn/simple
import imageio
...
imageio.imwrite(img_filename, output_img)
# scipy.misc.imsave(img_filename, output_img)
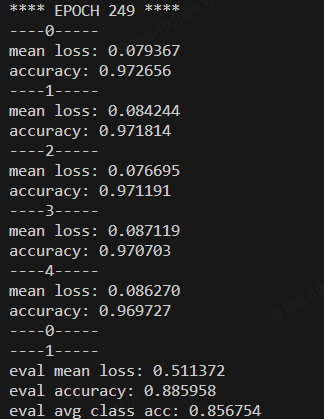
运行结果:
eval mean loss: 0.519701
eval accuracy: 0.884117
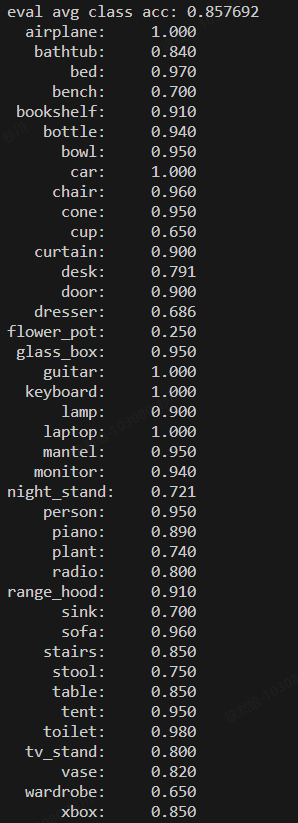
eval avg class acc: 0.857692
图片保存在dump目录下,是分类物体的三视图显示。源代码是把错误分类的物体的三视图保存下来了,我把所有的都保存下来看了一下。绘图是由pc_util.point_cloud_three_views方法实现三视图的绘制。原理是使用draw_point_cloud方法绘制二维点云图像,通过修改旋转系数xrot、yrot和zrot来改变主视图方向,最终输出三种不同视觉的图像。
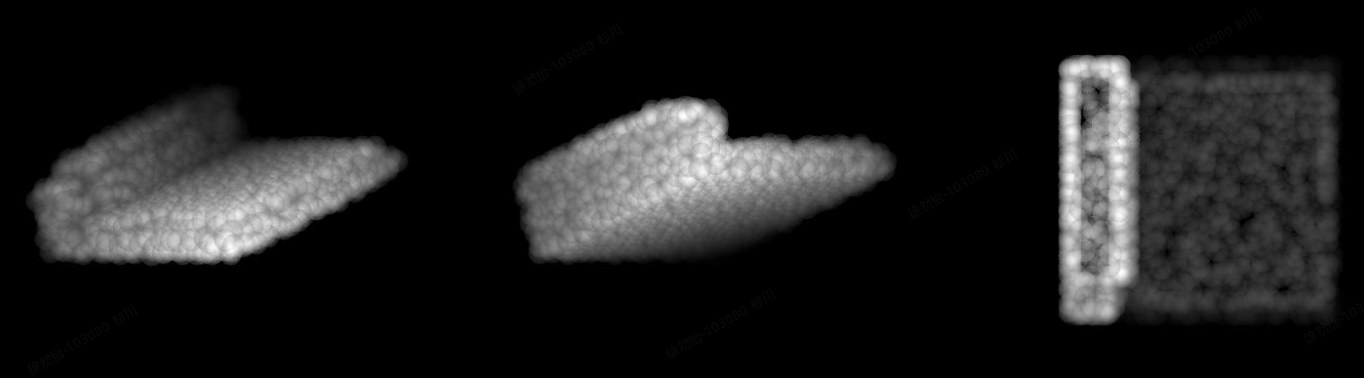
2220_label_bed_pred_bed.jpg:(这张标签为床,预测为床)
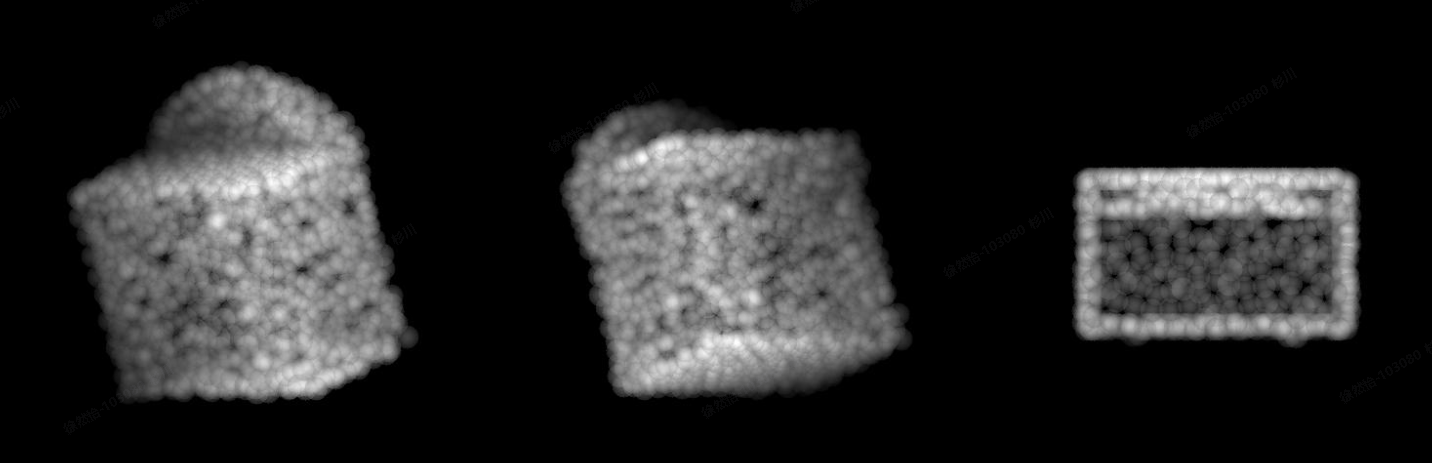
221_label_dresser_pred_sink.jpg(这是将梳妆台预测为洗碗槽)
处理自己的数据集:
https://blog.csdn.net/jiugeshao/article/details/131347202















 2673
2673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









