






前言
多模态大模型越来越火,效果也越来越好,比如Qwen2-VL效果就不错,其支持不同尺寸图片理解、视频理解,其目前已经开源,且最大开源到了72B。
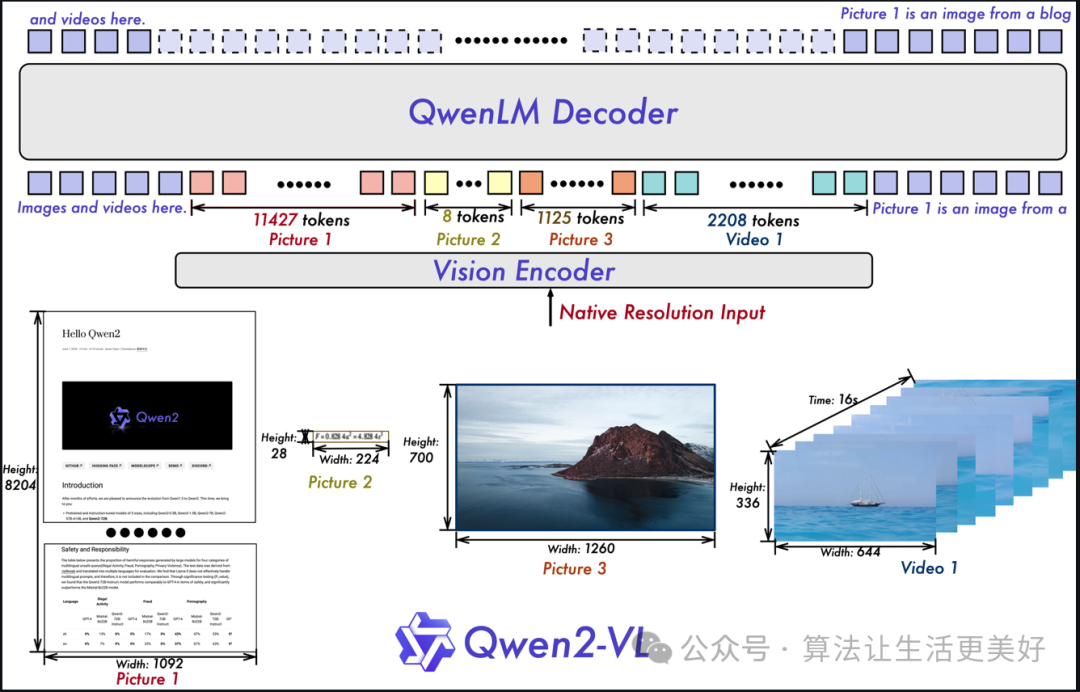
关于其技术报告,官方已经发了paper,大家可以自行阅读,而笔者主要想通过实操来看一下其实际效果以及提前踩一些坑,给大家提供一些具体的demo代码,方便大家迅速上手,甚至以此为开端上手所有多模态模型。
需要说明的是,这里的多模态是指多模态理解模型,如果大家对图片等生成模型比较感兴趣,可以看笔者之前另外一个系列:
《快速上手文生图sd3.5模型》:https://zhuanlan.zhihu.com/p/8561420928
言归正传,本篇一共分为两个part,第一个part是简单快速试一下其对视频理解的效果。第二个part是阿里天池上面正在举行一个多模态AI比赛(截至笔者写这篇博客的时候,其还没结束,感兴趣的小伙伴,可以一试),我们正好可以进行一下实践,看看能得多少分,当然官方也给了对应的baseline,大家也可以参考,也是使用Qwen2-VL。
全文较长,感兴趣的小伙伴建议收藏。
Qwen2-VL paper:https://arxiv.org/pdf/2409.12191
Qwen2-VL官方github链接:https://github.com/QwenLM/Qwen2-VL
WWW2025 多模态对话系统意图识别挑战赛:https://tianchi.aliyun.com/competition/entrance/532277?spm=a2c22.12281949.0.0.7e923b74AbsruI
小试牛刀
推理的demo大家直接用其git中提供的demo即可,作者这里试一下其对视频的理解能力
下面这个视频是笔者之前去江西婺源的景点拍摄的。
我们先试一下其7b的模型:https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor from qwen_vl_utils import process_vision_info, smart_resize model_path = "Qwen2-VL-7B-Instruct" model = Qwen2VLForConditionalGeneration.from_pretrained(model_path, torch_dtype="auto", device_map="auto", attn_implementation='flash_attention_2') processor = AutoProcessor.from_pretrained(model_path) messages = [ { "role": "user", "content": [ { "type": "video", "video": "data/demo.mp4" }, {"type": "text", "text": "描述一下这个视频,并猜一下这个视频可能的拍摄地点"}, ], } ] # Preparation for inference text = processor.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) image_inputs, video_inputs = process_vision_info(messages) inputs = processor( text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt", ) inputs = inputs.to("cuda") # Inference generated_ids = model.generate(**inputs, max_new_tokens=128) generated_ids_trimmed = [ out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids) ] output_text = processor.batch_decode( generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False ) print(output_text)
它的输出如下:

['这个视频展示了一个传统的中国村庄,坐落在山间。村庄的房屋大多是白墙黑瓦,屋顶上覆盖着黑色的瓦片。村庄的建筑风格具有浓厚的中国传统文化特色,房屋紧密相连,形成了一个紧凑的社区。村庄周围环绕着郁郁葱葱的树木和山脉,给人一种宁静和自然的感觉。天空中有一些云雾,增加了画面的层次感和神秘感。\n\n根据这些特征,这个视频可能的拍摄地点是中国的某个山区村庄,可能是江南地区的一个古镇,如乌镇、西塘等。这些地方以其传统的建筑风格和美丽的自然风光而闻名。']
可以看到基本上描述是正确的,而且比较详细,不过没有直接说出地点到底是哪里?其还提供了一个Qwen2-VL-Max版本的在线demo,我们直接试一下
demo:https://huggingface.co/spaces/Qwen/Qwen2-VL
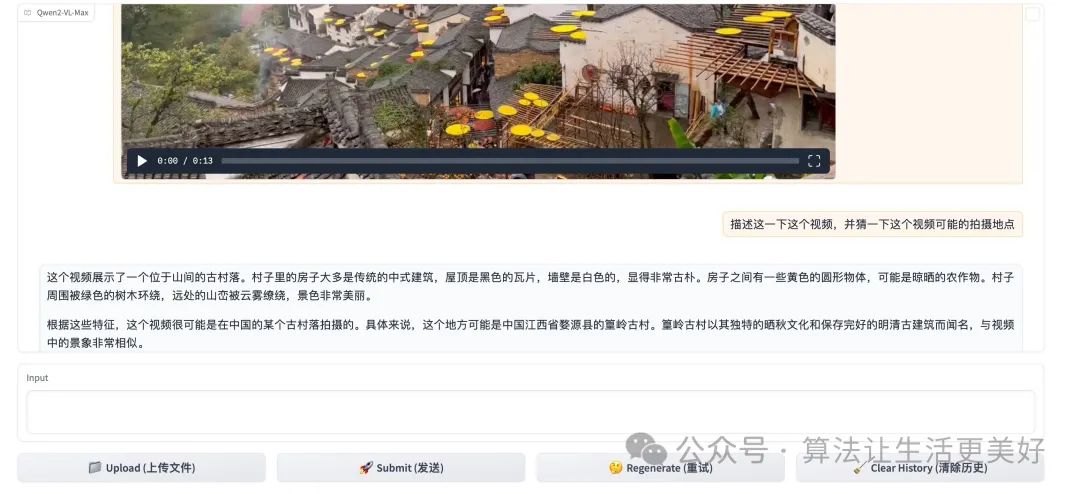
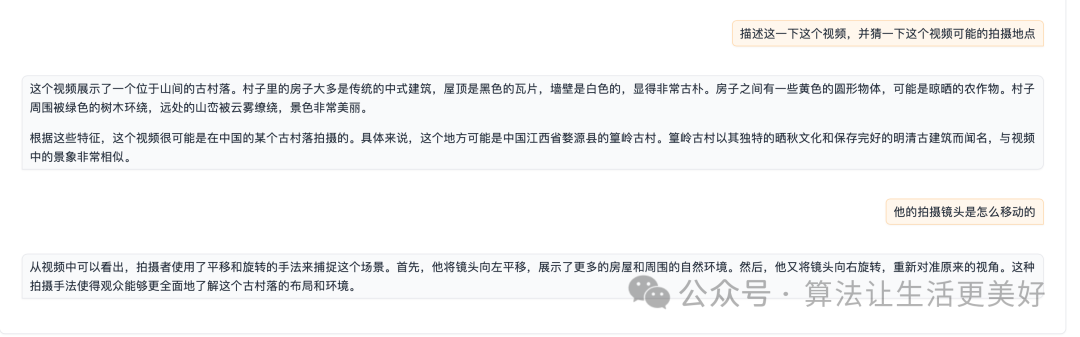
可以看到其准确说出了地点,而且追问拍摄手法时也回答的准确,效果还是不错的。
初步体验还是可以的,接下来我们就要开始上手训练一番了。
实践
- 比赛简介
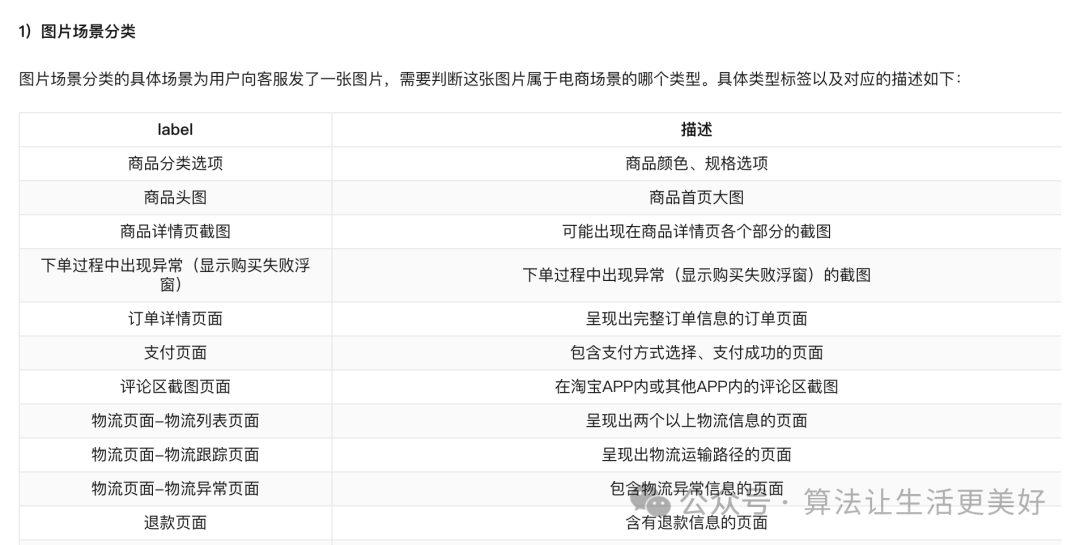
此比赛全部为文本结合图像的分类任务,其中包含2大类:图片场景分类以及多轮对话意图分类,比赛限制模型大小参数量小于10B


- baseline
我们先不做任何trick,直接用官方提供的1K训练集进行训练,然后提交一个baseline看看能有多少分?
Qwen2-VL的训练代码用的是LLaMA-Factory:https://github.com/hiyouga/LLaMA-Factory
该框架非常的简单,容易上手,按照步骤一步步照着做就行。
首先是把数据转化成其要求的shareg pt格式:
import os import json def tans2sharegpt_train(input_file, output_file): train_data_list = [] with open(input_file) as f: lines = json.load(f) for line in lines: cur_train_data = dict() messages = [{"role":"user", "content":line["instruction"]}, {"role":"assistant", "content":line["output"]}] images = [] for cur_image_name in line["image"]: images.append(os.path.join("data/train/images",cur_image_name)) cur_train_data["messages"] = messages cur_train_data["images"] = images train_data_list.append(cur_train_data) # save with open(output_file, "w") as file: json.dump(train_data_list, file, ensure_ascii=False) print("total data num : ", len(train_data_list)) input_file = "data/train/train.json" output_file = "data/www2025.json" tans2sharegpt_train(input_file, output_file)
然后在data/dataset_info.json里面配置一下:
"www2025": { "file_name": "www2025.json", "formatting": "sharegpt", "columns": { "messages": "messages", "images": "images" }, "tags": { "role_tag": "role", "content_tag": "content", "user_tag": "user", "assistant_tag": "assistant" } },
接下来就可以开始训练就行了,LLaMA-Factory推荐的训练脚本是其 llamafactory-cli工具,推理也是用它,该工具其实是其作者进行了进一步的封装,笔者这里这里再给一个更原生一点的启动脚本供大家参考,其中@就是实际大家需要使用的机器数。
`pip install pyav pip install transformers==4.46.1 pip install qwen-vl-utils==0.0.2 pip install accelerate==1.0.1 pip install deepspeed==0.13.5 cd LLaMA-Factory OUTPUT_PATH=/output/www2025_1126 ds_config_file=config/ds_zero3_offload.json torchrun $@ src/train.py \ --deepspeed $ds_config_file \ --stage sft \ --do_train \ --model_name_or_path model/Qwen2-VL-7B-Instruct \ --dataset www2025 \ --template qwen2_vl \ --finetuning_type full \ --output_dir $OUTPUT_PATH \ --overwrite_cache \ --overwrite_output_dir \ --warmup_ratio 0.1 \ --per_device_train_batch_size 1 \ --gradient_accumulation_steps 1 \ --ddp_timeout 180000000 \ --learning_rate 1e-5 \ --lr_scheduler_type cosine \ --logging_steps 1 \ --cutoff_len 4096 \ --save_steps 1000 \ --plot_loss \ --num_train_epochs 2 \ --bf16`
其中ds_zero3_offload.json配置如下:
{ "fp16": { "enabled": "auto", "loss_scale": 0, "loss_scale_window": 1000, "initial_scale_power": 16, "hysteresis": 2, "min_loss_scale": 1 }, "bf16": { "enabled": "auto" }, "zero_optimization": { "stage": 3, "offload_optimizer": { "device": "cpu" }, "offload_param": { "device": "cpu" }, "overlap_comm": true, "contiguous_gradients": true, "sub_group_size": 1e6, "reduce_bucket_size": "auto", "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "stage3_max_live_parameters": 1e6, "stage3_max_reuse_distance": 1e6, "stage3_gather_16bit_weights_on_model_save": true }, "gradient_accumulation_steps": "auto", "gradient_clipping": "auto", "steps_per_print": 10, "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "wall_clock_breakdown": false }
笔者是用了32卡训练的,最后训练集的loss是0.0341。
这里大家用zero3训练,一定要下载最新版本的LLaMA-Factory,不然训练过程中会卡住。具体见:https://github.com/hiyouga/LLaMA-Factory/issues/5944
训练完我们就可以推理测试集了。这里可以用llamafactory-cli,但是同理笔者再给一个更原生一点的推理脚本,
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor from qwen_vl_utils import process_vision_info, smart_resize import json import os import imagesize import pandas as pd import copy from datetime import datetime model_path = "output/www2025_1126" model = Qwen2VLForConditionalGeneration.from_pretrained(model_path, torch_dtype="auto", device_map="auto", attn_implementation='flash_attention_2') processor = AutoProcessor.from_pretrained(model_path) MAX_SEQ_LEN = 32000 id_list = [] predict_list = [] input_file = "data/test1/test1.json" total = 0 with open(input_file) as f: lines = json.load(f) for line in lines: cur_train_data = dict() if line["instruction"].startswith("<image>"): raise if line["instruction"].endswith("<image>"): raise total = total + 1 # if 393 > total: # continue content_list = [] for index, content in enumerate(line["instruction"].split("<image>")): content_list.append({"type":"text", "text":content}) if index != len(line["instruction"].split("<image>")) - 1: content_list.append({"type":"image", "image":os.path.join("data/test1/images", line["image"][index])}) messages = [{"role":"user", "content":content_list}] while True: # Preparation for inference text = processor.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) image_inputs, video_inputs = process_vision_info(messages) inputs = processor( text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt", ) inputs = inputs.to("cuda") if len(inputs.input_ids[0]) > MAX_SEQ_LEN: # 长度过长 # [{'role': 'user', 'content': [{'type': 'text', 'text': '你是一个电商客服专家,请根据用户与客服的多轮对话判断用户的意图分类标签。\n<用户与客服的对话 START>\n用户: '}, {'type': 'image', 'image': '/group/40092/20025/kaitongyang/self/VL/Qwen2-VL/data/test1/images/213d275e17278528447488623d1015-0.jpg'}, {'type': 'text', 'text': '\n客服: 您好!这款商品您遇到了什么问题吗?\n用户: '}, {'type': 'image', 'image': '/group/40092/20025/kaitongyang/self/VL/Qwen2-VL/data/test1/images/213d275e17278528447488623d1015-1.jpg'}, {'type': 'text', 'text': '\n客服: 亲爱的,当前由智能助手为您提供服务;请问您对这张图片有什么需要帮助的吗?\n用户: '}, {'type': 'image', 'image': '/group/40092/20025/kaitongyang/self/VL/Qwen2-VL/data/test1/images/213d275e17278528447488623d1015-2.jpg'}, {'type': 'text', 'text': '\n客服: 亲爱的,当前是由智能机器人提供服务;对于这张图片,您需要哪方面的帮助呢? 如果上述内容未能解答您的疑问,请回复“转人工”,我们将为您转接到人工客服进行处理哦~\n用户: 再次出现漏水情况\n客服: 亲爱的顾客,非常抱歉给您带来了不便。如果商品出现问题,您可以通过搜索小程序【家电服务助手】来预约专业人员上门服务。温馨提示:①如果您购买的商品在15天内出现质量问题,经过鉴定符合要求的话,我们提供退换服务;②如果超过15天但在保修期内,性能问题可享受免费保修;如涉及收费项目,工作人员会按照统一标准向您展示费用。\n<用户与客服的对话 END>\n请直接只输出分类标签结果,不需要其他多余的话。以下是可以参考的分类标签为:["反馈密封性不好","是否好用","是否会生锈","排水方式","包装区别","发货数量","反馈用后症状","商品材质","功效功能","是否易褪色","适用季节","能否调光","版本款型区别","单品推荐","用法用量","控制方式","上市时间","商品规格","信号情况","养护方法","套装推荐","何时上货","气泡"]\n'}]}] # print(total) # print(messages) # print(len(inputs.input_ids[0])) messages[0]['content'] = messages[0]['content'][1:] continue else: break # Inference: Generation of the output generated_ids = model.generate(**inputs, max_new_tokens=128) generated_ids_trimmed = [ out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids) ] output_text = processor.batch_decode( generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False )[0] # print(total, output_text) id_list.append(line["id"]) predict_list.append(output_text) if len(id_list) % 200 == 0: current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S") print(current_time, flush=True) print(len(id_list), flush=True) print(output_text) phase = "1210" data = pd.DataFrame({"id":id_list, "predict":predict_list}) data.to_csv("pred_result/%s.csv" % phase, index=False)
当然也可以用vllm加速来推理,具体可以见:https://github.com/hiyouga/LLaMA-Factory/blob/main/scripts/vllm_infer.py。因为笔者一直装vllm没装成功,所以懒的折腾了,大家可以试试。
另外在上面给出的原生推理脚本中,可能有两个地方需要解释一下,一个是messages对齐,我们看Qwen2-VL给的推理脚本(第一小节那里),他的messages格式要求是:
messages = [ { "role": "user", "content": [ { "type": "image", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg", }, {"type": "text", "text": "Describe this image."}, ], } ]
而我们的测试集messages的格式(或者LLaMA-Factory训练的时候)是:
{'messages': [{'role': 'user', 'content': '你是一个电商客服专家,请根据用户与客服的多轮对话判断用户的意图分类标签。\n<用户与客服的对话 START>\n用户: <http>\n客服: "建议您关注一下我们的成套优惠活动: 购买指定的晾衣机,将免费获赠一款洗衣机 晾衣机型号【HL-QS23SU1】 ①采用三重防护新标准,包括防漏电、防燃烧和防跌落。 ②配备柔光大屏幕,照明范围可达20平方米 ③设计为纤薄全嵌式,可完美嵌入阳台空间 <http>"\n用户: <image>\n客服: 重磅消息【大家期待已久的市政府补贴活动来了】!! 【以旧换新 市政府补贴】特定型号的一级能效产品可享受八折优惠,二级能效产品可享受八五折优惠,单件最高可减2000元,八大类别均可享受立即下单立减的优惠; 赶紧点击链接领取福利吧→<http> 【库存有限,先到先得,机会难得】\n用户: 您好,洗衣机关于排水口的问题\n客服: 亲爱的顾客,关于波轮式洗衣机:它们都是采用下排水设计的。至于滚筒式洗衣机:型号中包含X的表示下排水,没有X的则是上排水设计。(需要注意的是,MAX是特定系列的标识,这里的X并不意味着下排水) 您可以查看商品页面中的详细信息或规格参数来了解具体产品的排水方式。如果您有疑问,比如询问“这款是上排水吗”,我们的在线客服助手会帮您查询的。\n用户: 刚装上就出问题了\n客服: 您可以在微信搜索“家电服务”小程序或扫描下方二维码,在线申请安装、维修、移机、清洗等服务,我们的客服团队会为您安排专业技术人员上门服务;在保修期内,性能问题的处理是免费的,如果需要收费,技术人员会按照统一收费标准向您说明。\n用户: 出现了漏水情况\n客服: 亲爱的顾客,非常抱歉给您带来了不便。如果商品出现问题,您可以通过搜索小程序【家电服务助手】来预约专业人员上门服务。温馨提示:①如果您购买的商品在15天内出现质量问题,经过鉴定符合要求的话,我们提供退换服务;②如果超过15天但在保修期内,性能问题可以免费维修;如涉及收费项目,工作人员会按照统一标准向您展示费用。\n<用户与客服的对话 END>\n请直接只输出分类标签结果,不需要其他多余的话。以下是可以参考的分类标签为:["反馈密封性不好","是否好用","是否会生锈","排水方式","包装区别","发货数量","反馈用后症状","商品材质","功效功能","是否易褪色","适用季节","能否调光","版本款型区别","单品推荐","用法用量","控制方式","上市时间","商品规格","信号情况","养护方法","套装推荐","何时上货","气泡"]\n'}], 'images': ['/group/40092/20025/kaitongyang/self/VL/Qwen2-VL/data/train/images/21084b9217277750918824374d0ac0-0.jpg']}
仔细看,这两种messages的格式是不一样的。最大的区别就是下面这一种有个很关键的占位符
<image>
这个占位符的位置实际上就是到时候图片要填充的位置,即有可能是:文本+图片+文本。现在我们需要把这种测试集的messages格式转化为上面推理脚本要求的messages格式才行。具体怎么转化呢?很简单,我们就使用这个占位符进行split,这样文本就分割成了多段,然后占位符对应的位置就放实际图片就行。所以上面的测试集格式转化为推理的格式应该是:
[{'role': 'user', 'content': [{'type': 'text', 'text': '你是一个电商客服专家,请根据用户与客服的多轮对话判断用户的意图分类标签。\n<用户与客服的对话 START>\n用户: <http>\n客服: "建议您关注一下我们的成套优惠活动: 购买指定的晾衣机,将免费获赠一款洗衣机 晾衣机型号【HL-QS23SU1】 ①采用三重防护新标准,包括防漏电、防燃烧和防跌落。 ②配备柔光大屏幕,照明范围可达20平方米 ③设计为纤薄全嵌式,可完美嵌入阳台空间 <http>"\n用户: '}, {'type': 'image', 'image': '/group/40092/20025/kaitongyang/self/VL/Qwen2-VL/data/test1/images/21084b9217277750918824374d0ac0-0.jpg'}, {'type': 'text', 'text': '\n客服: 重磅消息【大家期待已久的市政府补贴活动来了】!! 【以旧换新 市政府补贴】特定型号的一级能效产品可享受八折优惠,二级能效产品可享受八五折优惠,单件最高可减2000元,八大类别均可享受立即下单立减的优惠; 赶紧点击链接领取福利吧→<http> 【库存有限,先到先得,机会难得】\n用户: 您好,洗衣机关于排水口的问题\n客服: 亲爱的顾客,关于波轮式洗衣机:它们都是采用下排水设计的。至于滚筒式洗衣机:型号中包含X的表示下排水,没有X的则是上排水设计。(需要注意的是,MAX是特定系列的标识,这里的X并不意味着下排水) 您可以查看商品页面中的详细信息或规格参数来了解具体产品的排水方式。如果您有疑问,比如询问“这款是上排水吗”,我们的在线客服助手会帮您查询的。\n用户: 刚装上就出问题了\n客服: 您可以在微信搜索“家电服务”小程序或扫描下方二维码,在线申请安装、维修、移机、清洗等服务,我们的客服团队会为您安排专业技术人员上门服务;在保修期内,性能问题的处理是免费的,如果需要收费,技术人员会按照统一收费标准向您说明。\n用户: 出现了漏水情况\n客服: 亲爱的顾客,非常抱歉给您带来了不便。如果商品出现问题,您可以通过搜索小程序【家电服务助手】来预约专业人员上门服务。温馨提示:①如果您购买的商品在15天内出现质量问题,经过鉴定符合要求的话,我们提供退换服务;②如果超过15天但在保修期内,性能问题可以免费维修;如涉及收费项目,工作人员会按照统一标准向您展示费用。\n<用户与客服的对话 END>\n请直接只输出分类标签结果,不需要其他多余的话。以下是可以参考的分类标签为:["反馈密封性不好","是否好用","是否会生锈","排水方式","包装区别","发货数量","反馈用后症状","商品材质","功效功能","是否易褪色","适用季节","能否调光","版本款型区别","单品推荐","用法用量","控制方式","上市时间","商品规格","信号情况","养护方法","套装推荐","何时上货","气泡"]\n'}]}]
另外一个需要搞懂的地方就是,在推理到393个样本的时候,会发现因为测试集过长,超过了最大长度,导致OOM。
Token indices sequence length is longer than the specified maximum sequence length for this model (48437 > 32768). Running this sequence through the model will result in indexing errors
那我们怎么办呢?那就截断呗即不断的舍弃content列表中最开始的一个元素,直到最大长度降到预设的门限。
上面这两点,大家看上面的代码应该是一目了然就清楚了。
那么最后我们提交一下分数看看成绩:

截止作者提交:参赛队伍一共1338个,这个成绩大概是140来名。
到此我们已经完整的学习了怎么使用Qwen2-VL来进行微调自己的任务以及训练完后怎么推理,大家有想试试自己任务的,例如视频等微调,脚本是大同小异的,完全可以复用。
- trick
本来分享到此就结束了,上面的代码应该够大家上手自己的任务了,但既然我们用了一个比赛来进行的实践,那就再针对这个比赛多聊几句该有可能提升分数的方向吧,这里提供一些思路供大家参考(不一定有效),当然都是一些数据层面的,因为模型没啥能改的,除非换个基座。
第一个能想到的就是cot,前面训练的时候我们没有对类别的含义进行进一步的解释,现在可以加上这些含义而且预测的时候让其一并给出理由。为此我们需要先得到有cot的回复,我们可以先用训练集那1K的数据,因为他有label,所以我们用Qwen2-VL-7B让其给出当前为啥是这个分类,下面是一个case的prompt和其给出的理由。
[{'role': 'user', 'content': [{'type': 'text', 'text': '你是一个电商客服专家,请根据用户与客服的多轮对话判断用户的意图分类标签。\n<用户与客服的对话 START>\n用户: '}, {'type': 'image', 'image': 'data/train/images/213e438b17282904772446704d0b28-0.jpg'}, {'type': 'text', 'text': '\n客服: 抱歉哦,小富目前还不能识别图片,您可以简单描述一下遇到的问题吗?/:068~~\n用户: <http>\n客服: 若您仍有疑问,可回复“客服”以便进一步协助您~\n用户: 内胆使用的是316不锈钢吗\n客服: 亲爱的,升级版的抗菌不锈钢是在304不锈钢的基础上改进的,它有抗菌功能(其内胆表面能够释放具有抑菌作用的铜离子,有效阻止大肠杆菌和金黄色葡萄球菌等有害细菌的生长);不过它的抗酸碱和抗腐蚀性能比不上316不锈钢;而316不锈钢在抗腐蚀和抗酸碱方面表现更佳,但没有抗菌功能。 ▲对于居住在海边或喜欢储存各种饮品的人来说,推荐使用316不锈钢;如果是为了儿童使用,建议选择抗菌不锈钢;追求性价比的话,304不锈钢是不错的选择;/:810\n<用户与客服的对话 END>\n请直接只输出分类标签结果,不需要其他多余的话。以下是可以参考的分类标签为:["反馈密封性不好","是否好用","是否会生锈","排水方式","包装区别","发货数量","反馈用后症状","商品材质","功效功能","是否易褪色","适用季节","能否调光","版本款型区别","单品推荐","用法用量","控制方式","上市时间","商品规格","信号情况","养护方法","套装推荐","何时上货","气泡"]\n'}, {'type': 'text', 'text': '每个标签的含义是:{"反馈密封性不好":"买家反馈商品密封性差会漏", "是否好用":"买家咨询商品是否好用", "是否会生锈":"咨询商品是否会生锈", "排水方式":"(适用产品:洗衣机、热水器)咨询商品排水方式", "包装区别":"咨询商品不同包装的区别","发货数量":"咨询商品发货数量","反馈用后症状":"买家反馈用完后引起的人体反应","商品材质":"咨询商品具体材质,配件材质,填充物","功效功能":"咨询商品功效功能","是否易褪色":"咨询商品是否易褪色","适用季节":"咨询商品适用季节","能否调光","咨询商品光源/灯光/光线/亮度是否可调","版本款型区别":"咨询两个版本/型号/款式/类型/套装/组合等区别,不包括商品数量/重量/尺寸类区别","单品推荐":"消费者咨询能否帮助推荐一下某类/某个商品,非sku级别","用法用量":"咨询商品使用方法/步骤/顺序,包括但不限于用量,使用时间,使用部位","控制方式":"咨询商品如何控制,能否可以通过手机/电脑控制","上市时间","咨询商品的上市时间","商品规格":"咨询商品的数量、重量、含量、容量", "信号情况":"咨询手机使用的信号是否良好,以及信号不佳如何处理", "养护方法":"咨询商品的养护方法","套装推荐":"消费者希望能推荐一些套装","何时上货":"咨询补货/上货时间","气泡":"咨询贴膜如何避免产生气泡及除气泡方法"}\n当前所属类别是商品材质,请给出理由,不超过50字。\n'}]}]
模型回答是
用户询问内胆材质,客服回答了304不锈钢、316不锈钢和抗菌不锈钢的区别,因此用户意图是咨询商品材质。
完整的代码是:
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor from qwen_vl_utils import process_vision_info, smart_resize import json import os import imagesize import pandas as pd import copy from datetime import datetime from template import dialogue_template, fig_template model_path = "Qwen2-VL-7B-Instruct" model = Qwen2VLForConditionalGeneration.from_pretrained(model_path, torch_dtype="auto", device_map="auto", attn_implementation='flash_attention_2') processor = AutoProcessor.from_pretrained(model_path) MAX_SEQ_LEN = 32000 id_list = [] predict_list = [] input_file = "data/train/train.json" total = 0 with open(input_file) as f: lines = json.load(f) for line in lines: cur_train_data = dict() if line["instruction"].startswith("<image>"): raise if line["instruction"].endswith("<image>"): raise total = total + 1 # if 393 > total: # continue content_list = [] for index, content in enumerate(line["instruction"].split("<image>")): content_list.append({"type":"text", "text":content}) if index != len(line["instruction"].split("<image>")) - 1: content_list.append({"type":"image", "image":os.path.join("data/train/images", line["image"][index])}) if "请根据用户与客服的多轮对话判断用户的意图分类标签" in line["instruction"]: content_list.append({"type":"text", "text":dialogue_template.format(label=line["output"])}) elif "请你对消费者上传的图片进行分类" in line["instruction"]: content_list.append({"type":"text", "text":fig_template.format(label=line["output"])}) else: raise messages = [{"role":"user", "content":content_list}] # print(messages) while True: # Preparation for inference text = processor.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) image_inputs, video_inputs = process_vision_info(messages) inputs = processor( text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt", ) inputs = inputs.to("cuda") if len(inputs.input_ids[0]) > MAX_SEQ_LEN: # 长度过长 # [{'role': 'user', 'content': [{'type': 'text', 'text': '你是一个电商客服专家,请根据用户与客服的多轮对话判断用户的意图分类标签。\n<用户与客服的对话 START>\n用户: '}, {'type': 'image', 'image': '/group/40092/20025/kaitongyang/self/VL/Qwen2-VL/data/test1/images/213d275e17278528447488623d1015-0.jpg'}, {'type': 'text', 'text': '\n客服: 您好!这款商品您遇到了什么问题吗?\n用户: '}, {'type': 'image', 'image': '/group/40092/20025/kaitongyang/self/VL/Qwen2-VL/data/test1/images/213d275e17278528447488623d1015-1.jpg'}, {'type': 'text', 'text': '\n客服: 亲爱的,当前由智能助手为您提供服务;请问您对这张图片有什么需要帮助的吗?\n用户: '}, {'type': 'image', 'image': '/group/40092/20025/kaitongyang/self/VL/Qwen2-VL/data/test1/images/213d275e17278528447488623d1015-2.jpg'}, {'type': 'text', 'text': '\n客服: 亲爱的,当前是由智能机器人提供服务;对于这张图片,您需要哪方面的帮助呢? 如果上述内容未能解答您的疑问,请回复“转人工”,我们将为您转接到人工客服进行处理哦~\n用户: 再次出现漏水情况\n客服: 亲爱的顾客,非常抱歉给您带来了不便。如果商品出现问题,您可以通过搜索小程序【家电服务助手】来预约专业人员上门服务。温馨提示:①如果您购买的商品在15天内出现质量问题,经过鉴定符合要求的话,我们提供退换服务;②如果超过15天但在保修期内,性能问题可享受免费保修;如涉及收费项目,工作人员会按照统一标准向您展示费用。\n<用户与客服的对话 END>\n请直接只输出分类标签结果,不需要其他多余的话。以下是可以参考的分类标签为:["反馈密封性不好","是否好用","是否会生锈","排水方式","包装区别","发货数量","反馈用后症状","商品材质","功效功能","是否易褪色","适用季节","能否调光","版本款型区别","单品推荐","用法用量","控制方式","上市时间","商品规格","信号情况","养护方法","套装推荐","何时上货","气泡"]\n'}]}] # print(total) # print(messages) # print(len(inputs.input_ids[0])) messages[0]['content'] = messages[0]['content'][1:] continue else: break # Inference: Generation of the output generated_ids = model.generate(**inputs, max_new_tokens=128) generated_ids_trimmed = [ out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids) ] output_text = processor.batch_decode( generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False )[0] id_list.append(line["id"]) predict_list.append(output_text) if len(id_list) % 200 == 0: current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S") print(current_time, flush=True) print(len(id_list), flush=True) print(output_text) phase = "1215" data = pd.DataFrame({"id":id_list, "predict":predict_list}) data.to_csv("pred_result/%s.csv" % phase, index=False)
其中dialogue_template和fig_template的是
dialogue_template = """每个标签的含义是:{{"反馈密封性不好":"买家反馈商品密封性差会漏", "是否好用":"买家咨询商品是否好用", "是否会生锈":"咨询商品是否会生锈", "排水方式":"(适用产品:洗衣机、热水器)咨询商品排水方式", "包装区别":"咨询商品不同包装的区别","发货数量":"咨询商品发货数量","反馈用后症状":"买家反馈用完后引起的人体反应","商品材质":"咨询商品具体材质,配件材质,填充物","功效功能":"咨询商品功效功能","是否易褪色":"咨询商品是否易褪色","适用季节":"咨询商品适用季节","能否调光","咨询商品光源/灯光/光线/亮度是否可调","版本款型区别":"咨询两个版本/型号/款式/类型/套装/组合等区别,不包括商品数量/重量/尺寸类区别","单品推荐":"消费者咨询能否帮助推荐一下某类/某个商品,非sku级别","用法用量":"咨询商品使用方法/步骤/顺序,包括但不限于用量,使用时间,使用部位","控制方式":"咨询商品如何控制,能否可以通过手机/电脑控制","上市时间","咨询商品的上市时间","商品规格":"咨询商品的数量、重量、含量、容量", "信号情况":"咨询手机使用的信号是否良好,以及信号不佳如何处理", "养护方法":"咨询商品的养护方法","套装推荐":"消费者希望能推荐一些套装","何时上货":"咨询补货/上货时间","气泡":"咨询贴膜如何避免产生气泡及除气泡方法"}} 当前所属类别是{label},请给出理由,不超过50字。 """ fig_template = """每个标签的含义是:{{"商品分类选项":"商品颜色、规格选项", "商品头图":"商品首页大图", "商品详情页截图":"可能出现在商品详情页各个部分的截图", "下单过程中出现异常(显示购买失败浮窗)":"下单过程中出现异常(显示购买失败浮窗)的截图", "订单详情页面":"呈现出完整订单信息的订单页面", "支付页面":"包含支付方式选择、支付成功的页面", "评论区截图页面":"在淘宝APP内或其他APP内的评论区截图", "物流页面-物流列表页面":"呈现出两个以上物流信息的页面", "物流页面-物流跟踪页面":"呈现出物流运输路径的页面","物流页面-物流异常页面":"包含物流异常信息的页面", "退款页面":"含有退款信息的页面", "退货页面":"含有退货信息的页面", "换货页面":"含有换货信息的页面","购物车页面":"淘宝购物车页面的列表图或金额计算图", "店铺页面":"店铺首页截图","活动页面":"活动截图", "优惠券领取页面":"店铺首页或活动页中领取优惠券的截图", "账单/账户页面":"包含交易明细列表、资产列表、卡券红包列表等", "投诉举报页面":"投诉或举报页面", "实物拍摄(含售后)":"用户用相机实拍的照片,包括用户售后的照片(损坏、缺失、与描述不符),或者其他用相机实拍的图片", "外部APP截图":"各种非淘宝、菜鸟APP的截图,包括京东、拼多多、短信、手机系统截图", "平台介入页面":"平台客服介入处理的截图", "其他类别图片":"拿不准的其他图片"}} 当前所属类别是{label},请给出理由,不超过50字。 """
当爬取完数据后,我们就可以制作训练数据啦。脚本如下:
import os import json import pandas as pd from template import dialogue_train_template, fig_train_template def tans2sharegpt_train(input_file, output_file): # load reason reason_data = pd.read_csv("1212.csv") reason_data_dict = dict() for idx, reason in zip(reason_data["id"].tolist(), reason_data["predict"].tolist()): reason_data_dict[idx] = reason train_data_list = [] with open(input_file) as f: lines = json.load(f) for line in lines: cur_train_data = dict() label = json.dumps({"理由":reason_data_dict[line["id"]], "所属类别":line["output"]}, ensure_ascii=False) if "请根据用户与客服的多轮对话判断用户的意图分类标签" in line["instruction"]: messages = [{"role":"user", "content":line["instruction"]+dialogue_train_template}, {"role":"assistant", "content":label}] elif "请你对消费者上传的图片进行分类" in line["instruction"]: messages = [{"role":"user", "content":line["instruction"]+fig_train_template}, {"role":"assistant", "content":label}] else: raise images = [] for cur_image_name in line["image"]: images.append(os.path.join("data/train/images",cur_image_name)) cur_train_data["messages"] = messages cur_train_data["images"] = images train_data_list.append(cur_train_data) # save with open(output_file, "w") as file: json.dump(train_data_list, file, ensure_ascii=False) print("total data num : ", len(train_data_list)) input_file = "data/train/train.json" output_file = "data/www2025.json" tans2sharegpt_train(input_file, output_file)
一条数据case如下:
{'messages': [{'role': 'user', 'content': '你是一个电商客服专家,请根据用户与客服的多轮对话判断用户的意图分类标签。\n<用户与客服的对话 START>\n用户: <image>\n客服: 抱歉哦,小富目前还不能识别图片,您可以简单描述一下遇到的问题吗?/:068~~\n用户: <http>\n客服: 若您仍有疑问,可回复“客服”以便进一步协助您~\n用户: 内胆使用的是316不锈钢吗\n客服: 亲爱的,升级版的抗菌不锈钢是在304不锈钢的基础上改进的,它有抗菌功能(其内胆表面能够释放具有抑菌作用的铜离子,有效阻止大肠杆菌和金黄色葡萄球菌等有害细菌的生长);不过它的抗酸碱和抗腐蚀性能比不上316不锈钢;而316不锈钢在抗腐蚀和抗酸碱方面表现更佳,但没有抗菌功能。 ▲对于居住在海边或喜欢储存各种饮品的人来说,推荐使用316不锈钢;如果是为了儿童使用,建议选择抗菌不锈钢;追求性价比的话,304不锈钢是不错的选择;/:810\n<用户与客服的对话 END>\n请直接只输出分类标签结果,不需要其他多余的话。以下是可以参考的分类标签为:["反馈密封性不好","是否好用","是否会生锈","排水方式","包装区别","发货数量","反馈用后症状","商品材质","功效功能","是否易褪色","适用季节","能否调光","版本款型区别","单品推荐","用法用量","控制方式","上市时间","商品规格","信号情况","养护方法","套装推荐","何时上货","气泡"]\n每个标签的含义是:{{"反馈密封性不好":"买家反馈商品密封性差会漏", "是否好用":"买家咨询商品是否好用", "是否会生锈":"咨询商品是否会生锈", "排水方式":"(适用产品:洗衣机、热水器)咨询商品排水方式", "包装区别":"咨询商品不同包装的区别","发货数量":"咨询商品发货数量","反馈用后症状":"买家反馈用完后引起的人体反应","商品材质":"咨询商品具体材质,配件材质,填充物","功效功能":"咨询商品功效功能","是否易褪色":"咨询商品是否易褪色","适用季节":"咨询商品适用季节","能否调光","咨询商品光源/灯光/光线/亮度是否可调","版本款型区别":"咨询两个版本/型号/款式/类型/套装/组合等区别,不包括商品数量/重量/尺寸类区别","单品推荐":"消费者咨询能否帮助推荐一下某类/某个商品,非sku级别","用法用量":"咨询商品使用方法/步骤/顺序,包括但不限于用量,使用时间,使用部位","控制方式":"咨询商品如何控制,能否可以通过手机/电脑控制","上市时间","咨询商品的上市时间","商品规格":"咨询商品的数量、重量、含量、容量", "信号情况":"咨询手机使用的信号是否良好,以及信号不佳如何处理", "养护方法":"咨询商品的养护方法","套装推荐":"消费者希望能推荐一些套装","何时上货":"咨询补货/上货时间","气泡":"咨询贴膜如何避免产生气泡及除气泡方法"}}\n输出格式要求:必须是一个字典,其有两个key,第一个key是理由,第二个key是所属类别\n'}, {'role': 'assistant', 'content': '{"理由": "用户询问内胆材质,客服回答了304不锈钢、316不锈钢和抗菌不锈钢的区别,因此用户意图是咨询商品材质。", "所属类别": "商品材质"}'}], 'images': ['/group/40092/20025/kaitongyang/self/VL/Qwen2-VL/data/train/images/213e438b17282904772446704d0b28-0.jpg']}
第二个就是数据增强,1000条训练数据还是太少了,我们可以多搞一些数据,但是我们没有真实的标签怎么办?可以蒸馏更大的模型给予的回复,比如用72B的模型。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









