






引言
今天Qwen3正式发布。作为通义千问系列的最新成员,Qwen3不仅在编码、数学推理等核心能力上比肩国际顶尖模型,更通过一系列创新设计,重新定义了开源大模型的技术边界。
本文旨在深入解析Qwen3的核心技术创新,探讨其在实际应用中的潜力,以及对开源AI生态的影响。无论你是AI研究者、开发者,还是对前沿技术感兴趣的读者,本文都将为你提供一个全面而深入的Qwen3技术导览。
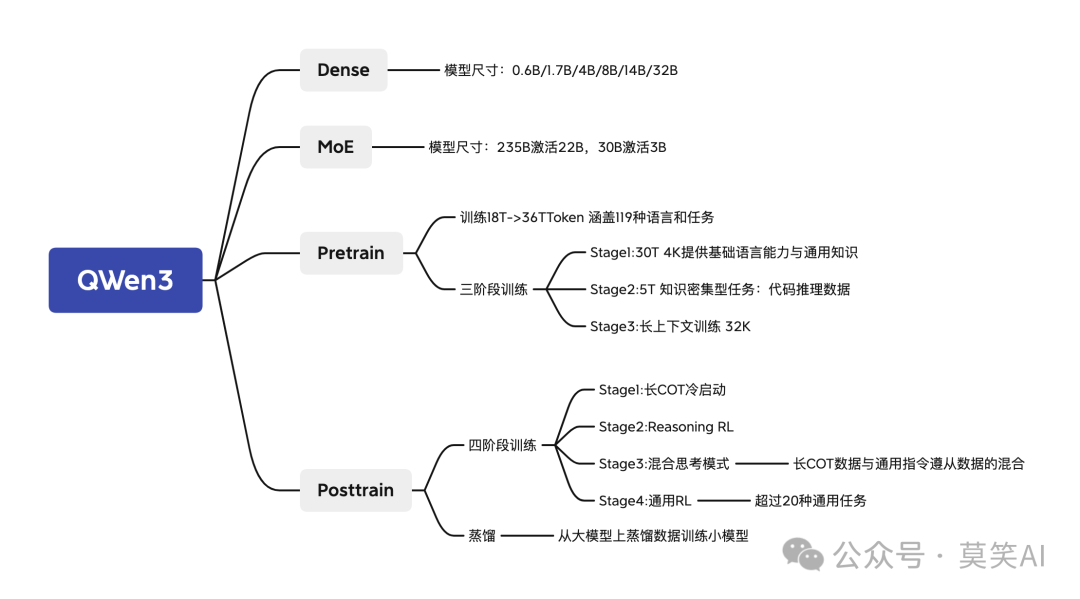
Qwen3的核心创新亮点包括:
混合思维架构: 独创的Thinking/Non-Thinking双模推理系统,实现推理预算的精准控制。
超大规模训练: 36万亿Token预训练数据(是Qwen2.5的2倍),覆盖119种语言及STEM领域。
极致效率突破: 采用混合专家(MoE)模型,以10%激活参数即可达成上代模型性能。
接下来,让我们一起深入Qwen3的技术细节。
 QWen3
QWen3
模型架构创新
双引擎驱动:Dense与MoE协同进化
Qwen3构建了一个完整而强大的模型矩阵,包括:
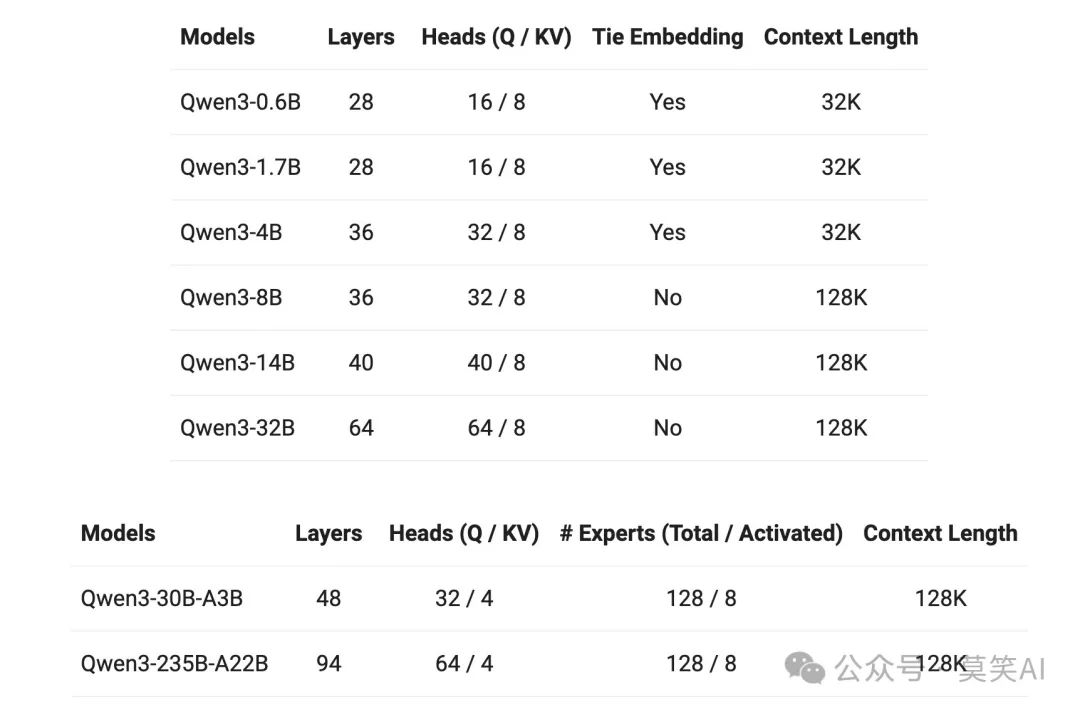
- Dense模型: 0.6B/1.7B/4B/8B/14B/32B全参数激活
- MoE模型: 235B总参/22B激活、30B总参/3B激活 这种设计为不同应用场景提供了灵活选择。Dense模型适合需要全面能力的场景,而MoE模型则在保持高性能的同时大幅提升了计算效率。
 值得注意的是,MoE-235B模型仅激活22B参数就能达到传统稠密模型的效果,这一突破性进展为大规模AI应用带来了新的可能。
值得注意的是,MoE-235B模型仅激活22B参数就能达到传统稠密模型的效果,这一突破性进展为大规模AI应用带来了新的可能。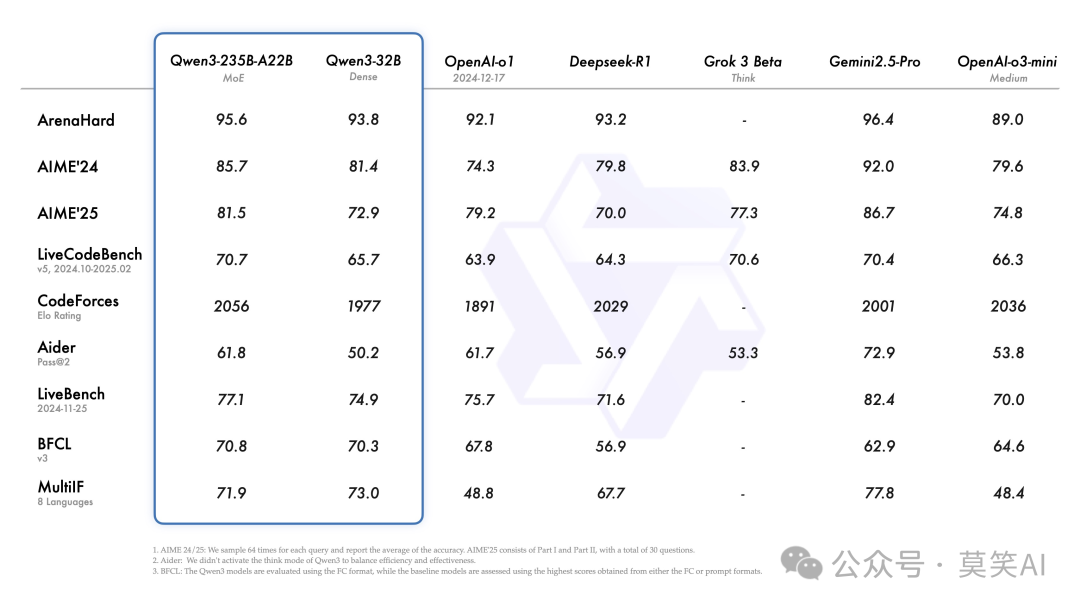
预训练技术
三阶段训练范式
Qwen3采用了精心设计的三阶段训练策略,每个阶段都针对特定能力进行优化:Stage1(基础能力构建):
- 利用30万亿Token、4K上下文窗口训练,建立扎实的语言和知识基础。
- 创新性地采用PDF文档解析技术(借助Qwen2.5-VL),构建高质量知识库。
Stage2(专业能力强化):
- 聚焦5万亿Token的STEM、编程等知识密集型任务训练。
- 引入合成数据生成技术(利用Qwen2.5-Math/Coder),包括教科书、问答对等高质量数据。
这里Stage2的出现与前两天的清华论文《Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?》中提及的RL中的推理能力原先基础模型已经获得结论相呼应,在基座模型训练过程中已经需要注入推理能力。
 JjLSzt
JjLSzt
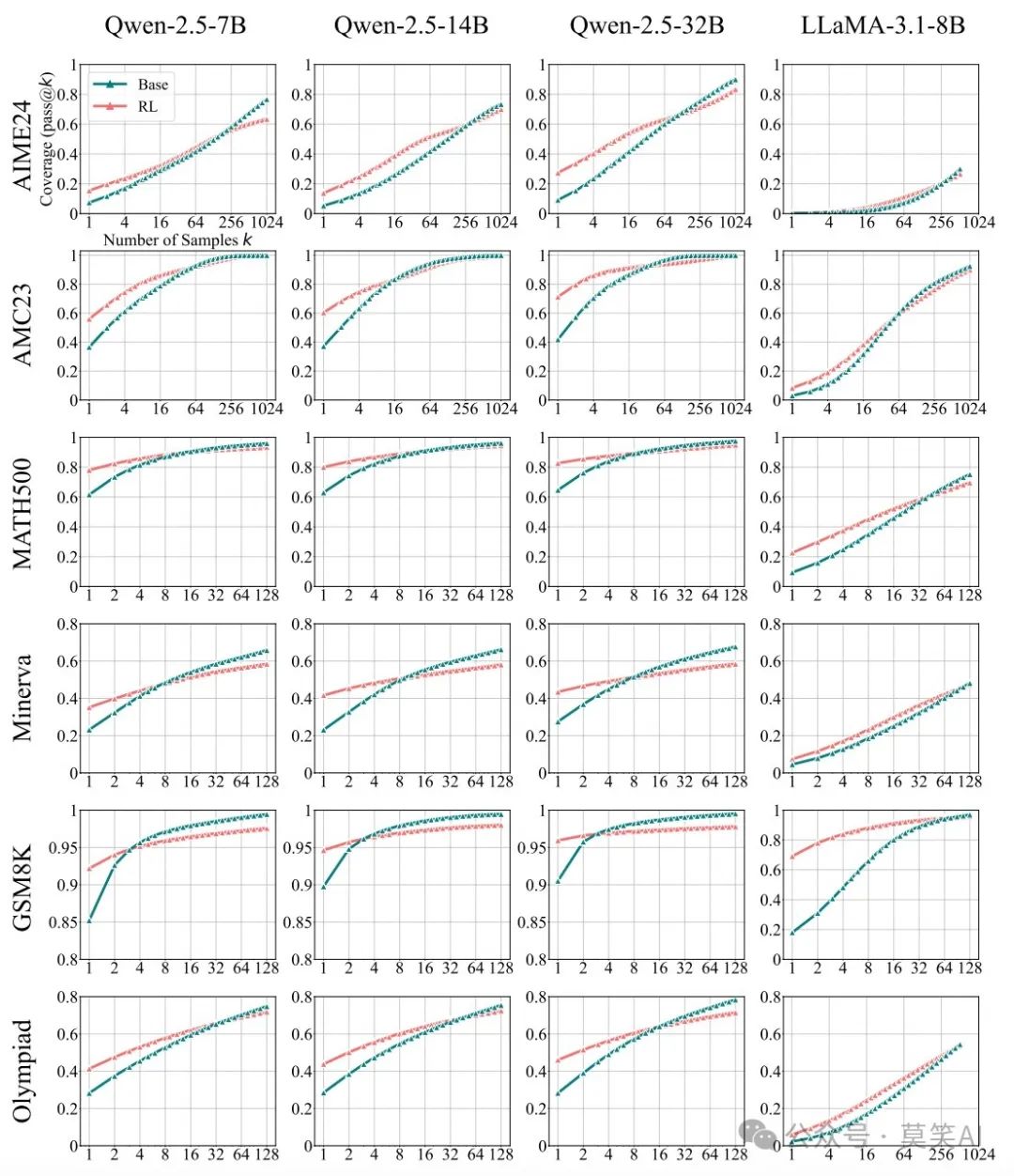 posgq0
posgq0
Stage3(长上下文能力塑造):
- 针对32K上下文窗口进行专项训练,显著提升模型处理长文本的能力。 这种渐进式训练方法确保了Qwen3在各个方面都具备了强大而均衡的能力。
后训练策略
四阶段能力精馏流程
Qwen3的后训练过程采用了创新的四阶段能力精馏流程: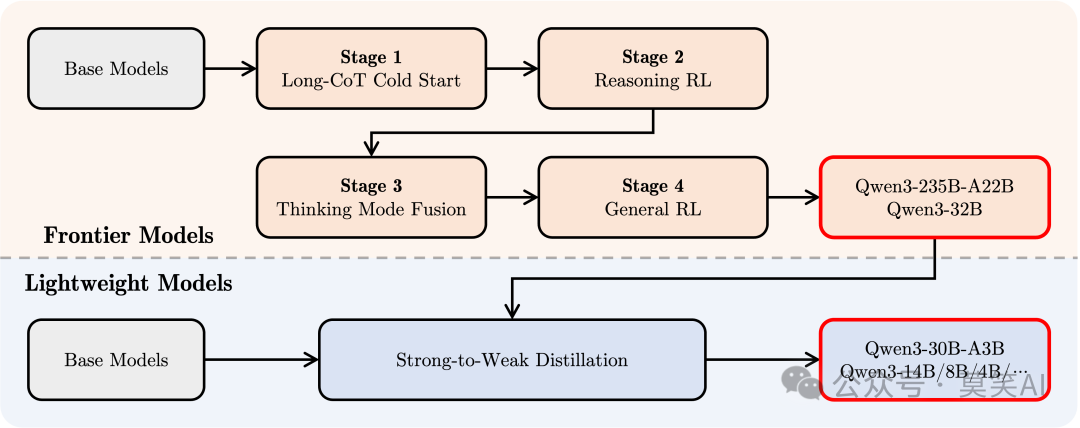 长链式思维冷启动: 通过数学证明、代码调试等长CoT(Chain-of-Thought)数据建立推理骨架。
长链式思维冷启动: 通过数学证明、代码调试等长CoT(Chain-of-Thought)数据建立推理骨架。
强化学习探索: 基于规则奖励机制,扩展模型的解空间探索能力。
双模融合训练: 将快速响应数据注入思维模型,实现推理速度与质量的平衡。
通用能力强化: 覆盖20+任务的通用强化学习(RL)训练。
此外,Qwen3还采用了知识蒸馏技术,使4B小模型能够继承32B大模型的能力,这一点与DeepSeek等先进模型的做法一致。
思维模式开关设计
Qwen3的一大创新是引入了可控的思维模式切换机制。用户可以通过 /think 与 /no_think 指令在对话中显式控制模型的思考模式: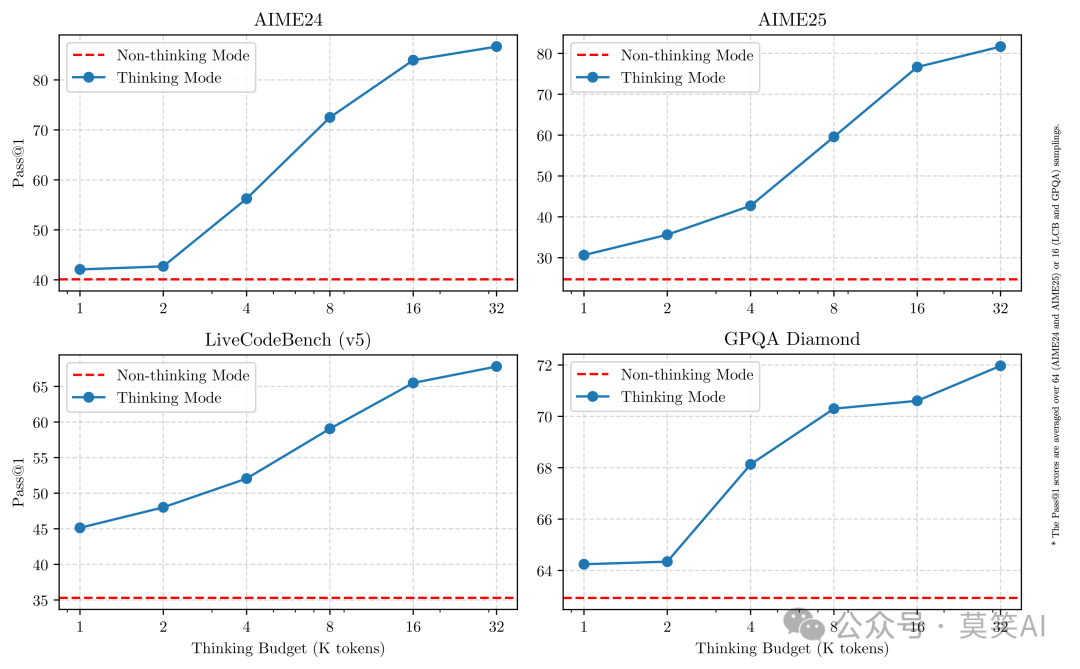 这一设计允许用户根据具体需求灵活调整模型的响应方式,在深度思考和快速回应之间找到最佳平衡。
这一设计允许用户根据具体需求灵活调整模型的响应方式,在深度思考和快速回应之间找到最佳平衡。
本质上QWen3将思维模式转成了模型对指令的遵从能力,根据输出中是否输出/think与/no_think显式控制输出模式,同时模型输出与Deepseek类似也是遵从一个格式 think process answer,当/no_think模式时,模型仍然会输出``标签,只是思考过程内为空的。
思维模式开关示例 user_input_1 = “解释量子隧穿效应 /think” # 默认启用深度思考 user_input_2 = “解释量子隧穿效应 /no_think” # 强制快速响应
输出:
User: 解释量子隧穿效应 /think
Bot: <think>
嗯,用户让我解释量子隧穿效应。首先,我得确定自己对这个概念的理解是否正确。量子隧穿效应是量子力学中的一个现象,对吧?就是粒子能够穿过经典力学中不可能通过的势垒。比如,经典物理中,如果一个球没有足够的能量滚过一座山,它就无法到达另一边。但在量子力学中,粒子却有一定的概率出现在势垒的另一边,即使它的能量低于势垒的高度。这似乎违反了经典直觉,所以需要详细解释。
接下来,我需要考虑用户可能的背景。他们可能是学生,或者是对物理学感兴趣的非专业人士。如果是学生,可能需要更深入的数学解释,比如薛定谔方程的解,波函数在势垒中的指数衰减,以及透射系数的计算。但如果是非专业人士,可能需要用更通俗的语言和类比来说明,避免复杂的数学公式。
用户的需求可能不仅仅是定义,而是理解为什么量子隧穿会发生,以及它的实际应用。比如,在半导体器件、核聚变、扫描隧道显微镜中的应用。因此,我需要涵盖这些方面,同时确保解释清晰易懂。
另外,用户可能没有说出的是他们对波函数和概率的理解程度。量子隧穿涉及波函数的非零概率密度在势垒另一侧,所以可能需要简要解释波函数的概念。但要注意不要偏离主题太远,保持解释的连贯性。
还要注意可能的误区,比如是否有人认为粒子真的“穿过”势垒,而实际上可能更准确的是波函数的指数衰减导致一定的概率存在。需要澄清这种概率性,而不是确定的路径。
最后,结构方面,应该先给出基本定义,再解释原理,接着举例子,最后提到应用。这样逻辑清晰,层次分明,有助于用户逐步理解。
</think>
量子隧穿效应(Quantum Tunneling)是量子力学中的一种现象,描述了微观粒子(如电子、质子等)能够以非零概率穿过经典力学中无法通过的势垒。这种现象在经典物理中是完全不可能的,但在量子力学中却成为基础特性之一。
---
### **核心原理**
1. **经典与量子的对比**:
- **经典物理**:如果一个粒子(如小球)的能量低于势垒的高度(例如一座山),它会被完全阻挡,无法越过势垒。
- **量子物理**:粒子的行为由波函数描述,其波函数在势垒区域会呈现指数衰减,但并不会完全消失。因此,粒子有一定的概率出现在势垒的另一侧,即使它的能量低于势垒高度。
2. **数学描述**:
- 通过求解薛定谔方程,可以发现波函数在势垒区域的解是指数衰减的(形式为 $ e^{-\alpha x} $,其中 $\alpha$ 与势垒宽度和高度相关)。
- 透射概率(穿过势垒的概率)由波函数在势垒另一侧的振幅平方决定,与势垒宽度、高度及粒子能量相关。
---
### **直观类比**
想象一个醉汉试图翻越一堵墙:
- **经典视角**:如果他没有足够的力气(能量),他会被困在墙的一侧。
- **量子视角**:他像“幽灵”一样,有一定概率直接“穿过”墙,而无需翻越。
---
### **关键特点**
1. **概率性**:隧穿效应并非确定性过程,而是以一定概率发生。
2. **依赖势垒特性**:势垒越宽或越高,透射概率越低。
3. **微观主导**:隧穿效应在微观尺度(如原子、亚原子)显著,宏观物体因质量太大(德布罗意波长极短)几乎无法观察到。
---
### **实际应用**
1. **核聚变**:
- 恒星内部的核聚变反应依赖质子通过量子隧穿效应克服库仑势垒,从而发生核反应。
2. **半导体器件**:
- 隧道二极管(Tunnel Diode)和闪存(Flash Memory)利用隧穿效应实现电子快速转移。
3. **扫描隧道显微镜(STM)**:
- 通过测量电子隧穿电流,STM 可以在原子级别观察材料表面。
4. **放射性衰变**:
- α粒子(氦核)通过隧穿效应从原子核中逃逸,导致放射性衰变。
---
### **常见疑问**
- **“粒子如何穿过势垒?”**
量子隧穿并非粒子“穿越”势垒的实体路径,而是波函数在势垒另一侧的非零概率密度。粒子的位置本质上是概率分布,而非确定轨迹。
- **“为什么经典物体没有隧穿效应?”**
宏观物体质量大,德布罗意波长极短,波函数衰减极快,导致透射概率趋近于零。
---
### **总结**
量子隧穿效应是量子力学与经典物理的根本区别之一,体现了微观世界的概率性和波粒二象性。它不仅是理论上的奇观,更是现代科技(如半导体、核能、量子计算)的基石。
----------------------
User: 解释量子隧穿效应 /no_think
Bot: <think>
</think>
量子隧穿效应(Quantum Tunneling)是量子力学中一种非常奇特且违反经典直觉的现象。它指的是微观粒子(如电子、质子等)能够以一定的概率穿过一个经典力学中无法穿越的势垒(potential barrier)的现象。
---
## 🌌 一、经典物理 vs 量子物理
在**经典物理**中,一个物体要穿过一个势垒(比如一个高墙),它必须拥有**足够的能量**。例如,一个球要滚过一座山,必须有足够的动能才能翻过山头。
但在**量子物理**中,微观粒子(如电子)表现出**波动性**。即使它们的能量低于势垒的高度,它们仍然有一定的**概率**出现在势垒的另一侧。这种现象就被称为**量子隧穿效应**。
---
## 🔬 二、量子隧穿的物理图像
想象一个电子从势垒的一侧出发,它面对一个“高墙”(势垒)。在经典物理中,如果它的能量不足以翻过这个墙,它就会被“弹回”。
但在量子力学中,电子的行为更像是一个**波函数**。波函数在势垒区域不会突然消失,而是**指数衰减**。虽然幅度变小了,但只要不是完全为零,就表示电子仍然**有可能**出现在势垒的另一侧。
---
## 🧮 三、数学上的描述(简化版)
在量子力学中,粒子的运动由**薛定谔方程**描述。当粒子遇到一个势垒时,其波函数在势垒区域会变成**指数衰减的形式**:
$$
\psi(x) \sim e^{-\alpha x}
$$
其中 $\alpha$ 与势垒的高度、宽度以及粒子能量有关。只要这个波函数在势垒的另一侧不是零,粒子就有一定的概率出现在那里。
---
## 🧪 四、实际应用
量子隧穿效应虽然在宏观世界中不明显,但在微观世界和现代科技中却至关重要,例如:
1. **半导体器件**:如隧道二极管、闪存等。
2. **核物理**:恒星中的核聚变(如太阳中的氢聚变)依赖于量子隧穿。
3. **扫描隧道显微镜(STM)**:利用电子的隧穿效应来观察原子级别的表面结构。
4. **量子计算**:某些量子算法(如量子退火)利用了隧穿效应。
---
## 🤔 五、一些常见问题
### Q1:为什么宏观物体不会发生隧穿?
A:因为宏观物体的质量大,波函数衰减极快,隧穿概率几乎为零。
### Q2:隧穿效应是否违反能量守恒?
A:不违反。粒子的总能量仍然守恒,只是在势垒中表现出波动性,从而有一定概率出现在另一侧。
### Q3:隧穿效应是否瞬间发生?
A:不是瞬间,而是需要一定时间,但这个过程比经典物理预测的时间要短,称为“超光速”隧穿,但并不违反相对论(因为信息不能超光速传递)。
---
## ✅ 总结
量子隧穿效应是量子力学中一个非常基础且重要的现象,它揭示了微观粒子的**波动性**和**概率性**,在现代科技中有广泛应用。它是量子世界与经典世界之间一个显著的分界线。
如果你对这个现象背后的数学或具体实验感兴趣,我也可以进一步解释。
----------------------
以下是一个简单的Python示例,展示如何使用Qwen3的思维模式控制:
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-30B-A3B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# 更新对话历史
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# 使用示例
if __name__ == "__main__":
chatbot = QwenChatbot()
# 默认思考模式
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# 使用 /no_think 模式
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# 使用 /think 模式
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
这个示例展示了如何初始化Qwen3模型,并通过简单的指令控制其思考模式。开发者可以基于此进一步拓展,实现更复杂的交互逻辑。
示例输出:
User: How many r's in strawberries?
Bot: <think>
Okay, let's see. The user is asking, "How many r's in strawberries?" Hmm. So I need to count the number of times the letter 'r' appears in the word "strawberries". Let me start by writing out the word so I can visualize it better.
Strawberries. Let me break it down letter by letter. S-T-R-A-W-B-E-R-R-I-E-S. Wait, is that right? Let me check again. S-T-R-A-W-B-E-R-R-I-E-S. Yeah, that's "strawberries". Now, I need to count the 'r's. Let's go through each letter one by one.
First letter: S – no. Second: T – no. Third: R – that's one. Fourth: A – no. Fifth: W – no. Sixth: B – no. Seventh: E – no. Eighth: R – that's two. Ninth: R – that's three. Tenth: I – no. Eleventh: E – no. Twelfth: S – no. Wait, does "strawberries" have twelve letters? Let me count again. S(1), T(2), R(3), A(4), W(5), B(6), E(7), R(8), R(9), I(10), E(11), S(12). Yes, twelve letters total. So the 'r's are at positions 3, 8, and 9. That's three 'r's.
Wait, but maybe I missed something. Let me spell it out again: S-T-R-A-W-B-E-R-R-I-E-S. Breaking it down into parts: "straw" (S-T-R-A-W), then"ber" (B-E-R), then"ries" (R-I-E-S). Wait, in"strawberries", after "straw" comes "berry" and then"ies"? So maybe the structure is "straw" + "berry" + "ies"? Let me check the spelling again. Yes, "strawberries" is the plural of "strawberry". The singular is S-T-R-A-W-B-E-R-R-Y. Then plural adds an 's' at the end, making it S-T-R-A-W-B-E-R-R-I-E-S. So in the singular, there are two 'r's in"strawberry": the third letter and then the eighth and ninth? Wait, no. Let's check "strawberry". S-T-R-A-W-B-E-R-R-Y. So positions 3 (R), 8 (R), 9 (R). Wait, that would be three 'r's in the singular, but "strawberry" is spelled with two 'r's in the middle? Wait, no. Let me spell it out again. S-T-R-A-W-B-E-R-R-Y. So after the 'E', there are two 'R's before the 'Y'. So that's two 'R's in"berry" part. So in"strawberry", there are two 'r's. Then when it becomes plural, "strawberries", adding 'ies' instead of just 's', so replacing the 'y' with 'i' and adding 'es'. So the plural would be S-T-R-A-W-B-E-R-R-I-E-S. So the 'r's are still in the same positions as the singular, which were two 'r's? Wait, no. Wait, in the singular "strawberry", the letters are S-T-R-A-W-B-E-R-R-Y. So that's two 'r's in the middle (positions 3 and 8?), but wait, let's count again. S(1), T(2), R(3), A(4), W(5), B(6), E(7), R(8), R(9), Y(10). So in the singular, there are two 'r's at positions 3 and 8? Wait, no, positions 3, 8, and 9? Wait, no. Let me write it out: S-T-R-A-W-B-E-R-R-Y. After the 'E', there are two 'R's followed by a 'Y'. So that's two 'R's in the middle. So positions 3 (R), 8 (R), and 9 (R)? Wait, no, the third letter is R, then after the E, the next letters are R, R, Y. So that's two R's. So in the singular, there are two R's. Then in the plural, when we replace the Y with I and add E-S, it becomes S-T-R-A-W-B-E-R-R-I-E-S. So the R's are still in the same positions: third letter and then the eighth and ninth letters? Wait, let me count again. S(1), T(2), R(3), A(4), W(5), B(6), E(7), R(8), R(9), I(10), E(11), S(12). So that's three R's: at positions 3, 8, and 9. So the plural "strawberries" has three R's. But wait, in the singular "strawberry", there are two R's. So when you make it plural, you add 'ies', which doesn't add any R's. Therefore, the plural "strawberries" should have the same number of R's as the singular, which is two. But according to my count above, when I spelled out "strawberries" as S-T-R-A-W-B-E-R-R-I-E-S, that's three R's. So there's a contradiction here. Where is the mistake?
Let me check the spelling of "strawberry" again. The correct spelling is S-T-R-A-W-B-E-R-R-Y. So in the singular, there are two R's: one in"straw" (third letter) and two in"berry" (positions 8 and 9). Wait, no. Wait, "strawberry" is S-T-R-A-W-B-E-R-R-Y. So after the E, it's R, R, Y. So that's two R's. So in the singular, two R's. Then the plural is "strawberries", which is formed by changing the Y to I and adding E-S. So replacing the Y with I and adding E-S. So the plural becomes S-T-R-A-W-B-E-R-R-I-E-S. Now, in the plural, the letters after the E are R, R, I, E, S. So the R's are still in positions 8 and 9. Therefore, the plural "strawberries" should also have two R's. But when I count through the letters of "strawberries" as S-T-R-A-W-B-E-R-R-I-E-S, that's three R's. So why the discrepancy?
Ah, maybe my initial breakdown was wrong. Let's write out the letters with their positions:
1: S
2: T
3: R
4: A
5: W
6: B
7: E
8: R
9: R
10: I
11: E
12: S
So in "strawberries", the R's are at positions 3, 8, and 9. That's three R's. But according to the singular "strawberry", there are two R's. How does that happen? Because in the singular, the letters after the E are R, R, Y. So positions 8: R, 9: R, 10: Y. So in the singular, two R's. Then in the plural, replacing Y with I and adding E-S, making positions 8: R, 9: R, 10: I, 11: E, 12: S. Therefore, the R's are still at positions 8 and 9. So why does my count of "strawberries" show three R's? Because maybe I made a mistake in the spelling. Let me check the spelling of "strawberries" again. The correct spelling is S-T-R-A-W-B-E-R-R-I-E-S. So that's S-T-R-A-W-B-E-R-R-I-E-S. So after the E, there are two R's, then I, E, S. So that's two R's. Wait, but when I count the letters:
1. S
2. T
3. R
4. A
5. W
6. B
7. E
8. R
9. R
10. I
11. E
12. S
So that's 12 letters. The R's are at positions 3, 8, and 9. So three R's. But according to the singular, there are two R's. So why is there an extra R in the plural? That doesn't make sense. Unless I'm miscounting the positions. Let me try another approach. Let's write out the word and underline the R's.
S T R A W B E R R I E S
Underlining the R's: the third letter is R, then after the E, there are two R's. So that's three R's in total. Therefore, the answer is three. But I thought the singular had two. Wait, maybe I was wrong about the singular. Let me check the spelling of "strawberry" again. The correct spelling is S-T-R-A-W-B-E-R-R-Y. So in the singular, there are two R's after the E. So positions 8 and 9. Then the Y is at position 10. So the singular has two R's. Then the plural is formed by changing the Y to I and adding E-S, resulting in S-T-R-A-W-B-E-R-R-I-E-S. So in the plural, the R's are still at positions 8 and 9. Therefore, the plural should also have two R's. But according to the letter count, there are three R's. Where is the mistake here?
Wait, maybe the third R is actually in the "straw" part. Let me look again. The word "strawberries" starts with S-T-R-A-W. So the first R is at position 3. Then after that comes B-E-R-R-I-E-S. So the next R's are at positions 8 and 9. So that's three R's in total. Therefore, the correct answer is three. But why did I think the singular has two? Let me check the singular again. "Strawberry" is S-T-R-A-W-B-E-R-R-Y. So the R's are at positions 3, 8, and 9? Wait, no. Let me count the letters in "strawberry":
1. S
2. T
3. R
4. A
5. W
6. B
7. E
8. R
9. R
10. Y
So that's ten letters. The R's are at positions 3, 8, and 9. Therefore, the singular "strawberry" also has three R's. Wait, but I thought it was two. Maybe I was mistaken before. Let me confirm by looking up the spelling. "Strawberry" is spelled S-T-R-A-W-B-E-R-R-Y. Yes, so after the E, there are two R's before the Y. So that's three R's in total. Therefore, the singular has three R's, and the plural "strawberries" also has three R's because the pluralization doesn't add or remove any R's. Therefore, the answer should be three R's in"strawberries".
But why did I initially think the singular had two? Maybe because I was miscounting the positions. Let me verify once more. "Strawberry" is S-T-R-A-W-B-E-R-R-Y. Breaking it down into syllables: "straw-berry". The "straw" part is S-T-R-A-W, and the "berry" part is B-E-R-R-Y. So in"berry", there are two R's. So in total, the word has three R's: one in"straw" and two in"berry". Therefore, both the singular and plural forms have three R's. So the answer is three.
</think>
The word "strawberries" contains **3** instances of the letter **r**.
Here's the breakdown:
1. The first **r** is in the third letter: **S-T-R**...
2. The second **r** is in the eighth letter: ...**B-E-R**...
3. The third **r** is in the ninth letter: ...**R-R-I-E-S**.
Thus, the correct count is **3 r's**.
**Answer:** There are **3** r's in"strawberries".
----------------------
User: Then, how many r's in blueberries? /no_think
Bot: <think>
</think>
Let's count the number of **r's** in the word **blueberries** step by step.
### Step-by-step breakdown of the word:
**blueberries** → B-L-U-E-B-E-R-R-I-E-S
Now, let's look for the letter **r**:
1. The first **r** appears in the 7th position: **...B-E-**R**...**
2. The second **r** appears right after: **...-**R**-I-E-S**
### Total count:
- There are **2** instances of the letter **r** in **blueberries**.
### ✅ Final Answer:
**There are 2 r's in "blueberries".**
----------------------
User: Really? /think
Bot: <think>
Okay, the user asked about the number of r's in"blueberries" after previously asking about "strawberries." I told them there are 2 r's in "blueberries," but now they're responding with "Really?"which is a bit skeptical.
Hmm, maybe they're not convinced. Let me double-check my answer to make sure I didn't make a mistake. The word "blueberries" is spelled B-L-U-E-B-E-R-R-I-E-S. Let me go through each letter one by one:
B, L, U, E, B, E, R, R, I, E, S.
Looking at the letters, the R's are at positions 7 and 8. So that's two R's. Wait, is there another one I missed? Let me spell it out again: B-L-U-E-B-E-R-R-I-E-S. Yep, only two R's.
But maybe the user is confused because in"strawberries" there are three R's, and they're checking if I'm consistent. Or perhaps they're trying to catch a mistake. Alternatively, maybe they think there's a trick, like uppercase R's or something else.
Wait, the user might be thinking of the plural form. But "blueberries" is already plural. Let me confirm the spelling again. Sometimes people might miscount if they're not careful. Let me write it out:
B - 1
L - 2
U - 3
E - 4
B - 5
E - 6
R - 7
R - 8
I - 9
E - 10
S - 11
So positions 7 and 8 are both R's. That's two. I think my answer is correct. Maybe the user is just surprised because they expected more or less, or maybe they made a typo in the word. Let me check if they wrote "blueberries" correctly. The user wrote "blueberries" in the previous question, so the spelling is correct.
Alternatively, maybe they're thinking of the word "blueberry" (singular) and then the plural, but the plural is "blueberries" with two R's. Wait, the singular is "blueberry" with one R. So in the plural, it's "blueberries" with two R's. So that's correct.
I think my answer is accurate. The user might be testing if I made a mistake. To address their skepticism, I should re-examine the word carefully and confirm the count once more. Let me also explain the process step by step incase they missed the explanation before.
Another angle: sometimes people might miscount the letters if they're not reading carefully. Let me break it down again. The word is B-L-U-E-B-E-R-R-I-E-S. The R's are in the seventh and eighth letters. So two R's.
I should respond by confirming the count and maybe spelling out the word again to make it clearer. It's possible the user is just confirming or wants to see the breakdown again. Let me make sure to be clear and thorough in my response to alleviate any doubts.
</think>
Let’s verify **"blueberries"** again to ensure accuracy.
**Spelling**: **B-L-U-E-B-E-R-R-I-E-S**
Break it down letter by letter:
1. **B**
2. **L**
3. **U**
4. **E**
5. **B**
6. **E**
7. **R**
8. **R**
9. **I**
10. **E**
11. **S**
The **r's** are in **positions 7 and 8**.
**Total r's**: **2**
If you’re confused, it might be because the plural form **"blueberries"** adds an extra **"r"** compared to the singular **"blueberry"** (which has 1 r). But in **"blueberries"**, the double **"rr"** makes it **2 r's**.
✅ **Final Answer**: **2 r's** in"blueberries".
模型结构深度解析
QWen2 VS QWen3: 演进与创新
Qwen3在保持核心架构稳定的同时,引入了一些关键的改进。让我们通过比较来深入理解这些变化:
Dense模型的微调优化
Qwen3的Dense模型结构与Qwen2相比没有显著变化,但在Attention模块中引入了一项重要优化: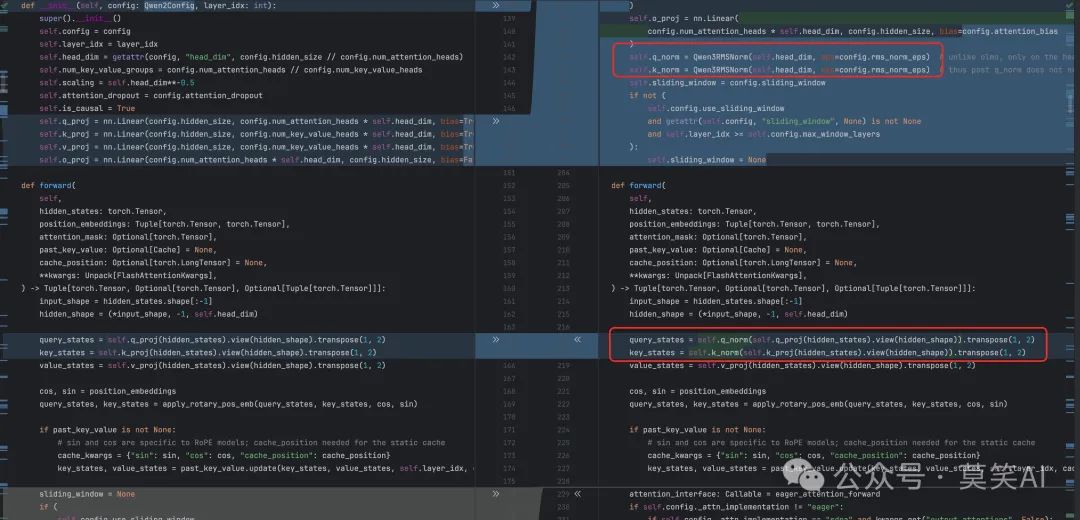 如图所示,Qwen3在Query(Q)和Key(K)计算后增加了RMSNorm归一化步骤。这一改进有助于稳定训练过程,提高模型的收敛速度和泛化能力。
如图所示,Qwen3在Query(Q)和Key(K)计算后增加了RMSNorm归一化步骤。这一改进有助于稳定训练过程,提高模型的收敛速度和泛化能力。
MoE模型: 效率与性能的平衡
Qwen3的一大亮点是引入了Mixture of Experts (MoE)模型。MoE架构允许模型在保持高性能的同时大幅提升计算效率: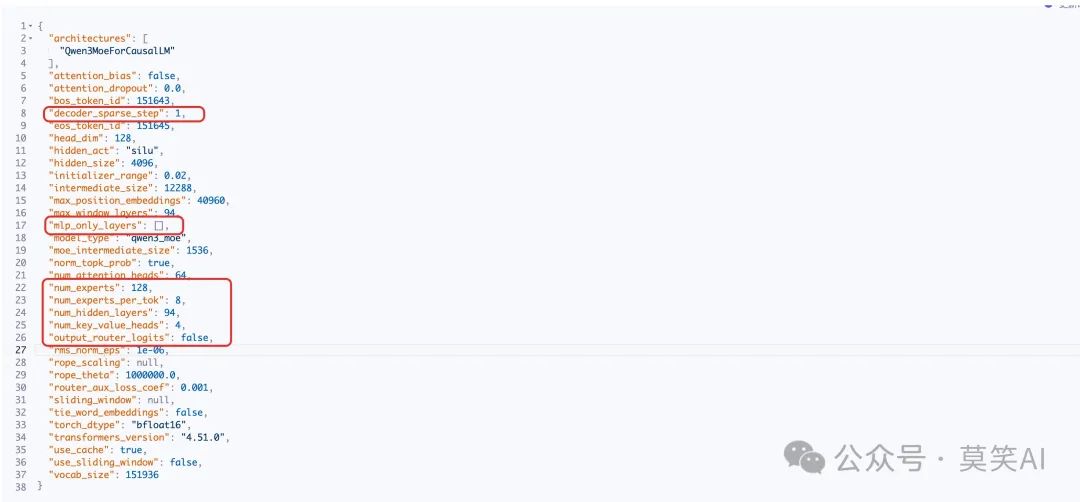 MoE层的分发逻辑如下:
MoE层的分发逻辑如下:
if (layer_idx not in config.mlp_only_layers) and (
config.num_experts > 0 and (layer_idx + 1) % config.decoder_sparse_step == 0
):
self.mlp = Qwen3MoeSparseMoeBlock(config)
else:
self.mlp = Qwen3MoeMLP(config, intermediate_size=config.intermediate_size)
这段代码展示了Qwen3如何决定在哪些层使用MoE结构。值得注意的是,所有MoE层都采用了Qwen3MoeSparseMoeBlock结构。 在Qwen3MoeSparseMoeBlock中,我们主要关注两个核心问题:
- 路由机制: 如何将输入分发给不同的专家
- 负载均衡: 如何确保各个专家被均匀利用
Qwen3采用了Top-K路由策略,但目前的代码中似乎没有明显的负载均衡机制。这可能需要解读具体技术报告。
以下是MoE结构的核心组件概览:
| 组件 | 功能 | 示例值 |
|---|---|---|
| 门控网络 | 计算路由权重 | Linear(hidden_size→num_experts) |
| 专家池 | 执行具体计算 | 多个MLP组成的ModuleList |
| TopK选择器 | 动态路由决策 | 选择权重最高的K个专家 |
输入序列
│
▼
[Token1, Token2, ..., TokenN] # 每个token独立选择专家
│
▼
门控网络 → 路由权重 → TopK选择
│
▼
专家1 专家2 ... 专家M # 仅被选中的专家参与计算
│ │ │
▼ ▼ ▼
加权求和 → 输出序列
这种设计允许模型根据输入的不同动态调整计算资源,大大提高了模型的灵活性和效率。
DeepSeek MoE VS QWen MoE
我们简单从MoE结构对比一下DeepSeek MoE 与 QWen MoE:
一、核心组件对比表
| 对比维度 | Qwen3MoE | DeepseekV3MoE |
|---|---|---|
| 路由机制 | 简单TopK选择 | 分组TopK选择 + 得分修正偏置 |
| 专家结构 | 标准MLP(gate+up+down) | 改进型MLP(gate与up独立计算后相乘) |
| 共享专家 | ❌ 无 | ✅ 独立共享专家(n_shared_experts参数控制) |
| 负载均衡机制 | ❌ 无显式处理 | ✅ 通过分组选择和得分偏置间接实现 |
| 归一化方式 | 可选TopK权重L1归一化 | 强制TopK权重L1归一化(分母含极小值保护) |
| 路由计算 | 直接Softmax后取TopK | Sigmoid后分组筛选再TopK |
| 计算优化 | 基础实现(显式循环) | 尝试优化但仍有显式循环(代码注释提到待优化) |
| 专家激活方式 | 完全动态路由 | 动态路由+静态共享专家 |
| 参数复用 | 独立专家参数 | 路由权重与专家参数解耦 |
| 路由维度 | 单个大路由池 | 分组路由(n_group参数控制) |
二、关键技术差异解析
1. 路由机制设计
| 实现细节 | Qwen3MoE | DeepseekV3MoE |
|---|---|---|
| 核心逻辑 | softmax → topk | sigmoid → 分组预选 → topk |
| 路由权重计算 | 线性层直接输出路由分数 | 可学习的路由权重矩阵(self.weight参数) |
| 分组策略 | ❌ 无 | ✅ 将专家分为n_group组,先选组内Top2再聚合(n_group参数控制) |
| 得分修正 | ❌ 无 | ✅ 使用e_score_correction_bias调整专家得分(注册为buffer的偏置项) |
# Deepseek分组路由核心代码片段
group_scores = scores_for_choice.view(-1, n_group, n_expert_per_group).topk(2,dim=-1)[0].sum(-1)
group_idx = torch.topk(group_scores, k=topk_group)[1] # 先选组
score_mask = group_mask.expand(...).reshape(-1, n_routed_experts) # 再展开
2. 专家结构对比
| 特征 | Qwen3MLP | DeepseekV3MLP |
|---|---|---|
| 激活方式 | 标准前馈结构 | 改进型门控结构 |
| 计算公式 | down(gate(x) * up(x)) | down(act(gate(x)) * up(x)) |
| 参数规模 | 标准尺寸 | 共享专家使用扩大中间层(moe_intermediate_size*n_shared_experts) |
# DeepseekV3MLP前向计算
def forward(x):
return down_proj(act_fn(gate_proj(x)) * up_proj(x)) # 先激活再相乘
3. 负载均衡策略
| 方法 | Qwen3MoE | DeepseekV3MoE |
|---|---|---|
| 显式损失项 | ❌ 无 | ❌ 无 |
| 隐式策略 | ❌ 无 | ✅ 分组路由 + 得分偏置修正 |
| 专家容量控制 | ❌ 无 | ❌ 无(但分组设计自然限制专家选择范围) |
三、结构示意图对比
Qwen3MoE数据流
输入 → 展平 → 路由计算 → TopK选择 → 专家计算 → 加权求和 → 输出
DeepseekV3MoE数据流
输入 → 路由计算 → 分组预选 → TopK选择 → 专家计算 → 加权求和 → 叠加共享专家 → 输出
↑
得分偏置修正
应用场景展望
Qwen3的创新设计为多个领域带来了新的可能性,详细结束解读等技术报告:
智能助手: 混合思维模式使Qwen3能够根据用户需求灵活切换between深度思考和快速响应,提供更自然的交互体验。
代码开发: 强化的STEM和编程能力使Qwen3成为强大的编程助手,可以辅助代码生成、debug和优化。
多语言处理: 覆盖119种语言的训练使Qwen3在跨语言应用中具有显著优势
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









