






写在最前:
在系统地学习了Transformer结构后,尝试使用Transformer模型对DNA序列数据实现二分类,好久前就完成了这个实验,一直拖着没有整理,今天系统的记录一下,顺便记录一下自己踩过的坑
1、数据说明
两个csv文件,共有三列,第一列是id,第二列每个数据都是一长串dna序列,第三列是它们的label,分别是0和1。
数据的data列有点长,此处截了一部分供大家参考:
2、python库准备
此处Transformer我使用了pytorch的,所以需要事先安装pytorch库,这里是一大踩坑点
我是跟这篇博客下载安装的,因为我的电脑配置也是win10+MX350显卡+CUDA10.2,最后安装在conda环境下安装pytorch:
第一次没有指定pytorch版本结果自动装了最新版,然后在python环境下输入print(torch.cuda.is_available()),结果是false。
第二次:将之前的卸载重新安装,此处指定了版本好像是1.10,结果最后还是false。
第三次:百思不得其解,就找了大量的原因,最后用了下面的命令:pip3 install torch1.10.1+cu102 torchvision0.11.2+cu102 torchaudio===0.10.1+cu102 -f https:// download.pytorch.org/whl/cu102/torch_stable.html
然后打印输出:True!!!

3、实验难点
个人感觉实验中最重要的两部分就是dna序列数据的处理和Transformer模型构建。
3.1 DNA数据处理
数据中第二列data列是dna数据,很长一串,需要进行转换。
(1)我刚开始使用了独热编码,代码如下:
def one_hot_encode_sequence(sequence):
mapping = {'A': [1, 0, 0, 0], 'C': [0, 1, 0, 0], 'G': [0, 0, 1, 0], 'T': [0, 0, 0, 1]}
encoding = [mapping[base] for base in sequence]
return np.array(encoding)
# 对DNA序列进行单热编码
# 每个seq是一个序列,序列中的每个base变成[1,0,0,0],再组合成二维
X = np.array([one_hot_encode_sequence(seq) for seq in data3['data']])
y = data3['label'].values
很好理解,就是将ACGT分别映射成[1,0,0,0] [0,1,0,0] [0,0,1,0] [0,0,0,1],但是这样就多了一个维度,打印一下x的shape看看:

直接变三维数据了,然后后面在Transformer阶段,数据维度转换就出了问题:
我想计算loss,刚开始写了loss = criterion(outputs, labels.view(-1, 1)),但是outputs是torch.Size([1, 1001, 1],labels是torch.Size([32]),这两个数据不知道怎么才能转换成同一shape的数据,当时搞了好久也没成功,所以放弃这个编码方案。。。。
(如果有大佬有方法将这两个的size改成一致,欢迎评论区留言!!)
(2)使用嵌入编码
直接上代码:
# 将DNA序列数据转换为整数编码
def integer_encode(seq):
seq = seq.upper()
encoding = {'A': 0, 'T': 1, 'C': 2, 'G': 3}
return np.array([encoding[x] for x in seq])
X = np.array([integer_encode(seq) for seq in X])
y = np.array(y)
很好理解,再看一下X的维度:

很明显比上面的三维数据要好哈哈哈
好用!爱用!!下次还用!!
3.2 Transformer结构
(1)首先需要嵌入位置信息
直接上代码吧,我喜欢做注释,这个注释也很详细,大家自己看就明白了,其实就对应了Transformer论文中PE的公式:
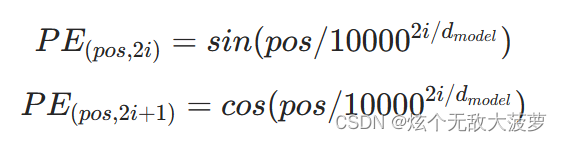
# 定义PositionalEncoding
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# pe的维度(位置编码最大长度,模型维度)
pe = torch.zeros(max_len, d_model)
# 维度为(max_len, 1):先在[0,max_len]中取max_len个整数,再加一个维度
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 位置编码的除数项:10000^(2i/d_model)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-np.log(10000.0) / d_model))
# sin负责奇数;cos负责偶数
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
#维度变换:(max_len,d_model)→(1,max_len,d_model)→(max_len,1,d_model)
pe = pe.unsqueeze(0).transpose(0, 1)
# 将pe注册为模型缓冲区
self.register_buffer('pe', pe)
def forward(self, x):
# 取pe的前x.size(0)行,即
# (x.size(0),1,d_model) → (x.size(0),d_model),拼接到x上
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
(2)然后就是Transformer结构
# 定义Transformer模型
class TransformerModel(nn.Module):
def __init__(self, input_dim, output_dim, d_model, nhead, num_layers, dim_feedforward, dropout):
super(TransformerModel, self).__init__()
# 创建一个线性变换层,维度input_dim4→d_model
self.embedding = nn.Embedding(input_dim, d_model) # 使用嵌入层
# 生成pe
self.pos_encoder = PositionalEncoding(d_model, dropout)
# 生成一层encoder
encoder_layers = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, dropout=dropout)
# 多层encoder
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers=num_layers)
# 维度d_model→output_dim
self.fc = nn.Linear(d_model, output_dim)
self.d_model = d_model
def forward(self, src):
src = src.permute(1, 0)
# 缩放
src = self.embedding(src) * np.sqrt(self.d_model)
# 加上位置嵌入
src = self.pos_encoder(src)
output = self.transformer_encoder(src)
# 调整输出形状为(batch, seq_len, d_model)
output = output.permute(1, 0, 2)
# 对所有位置的表示取平均
output = torch.mean(output, dim=1)
# 线性变换
output = self.fc(output)
# 使用sigmoid激活函数
output = torch.sigmoid(output)
return output
4、其余
解决了上面的难点,后面的导包、数据导入预处理划分、数据加载、训练数据、测试数据就不细说了,后面有完整代码大家自己看吧
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
# data1和data2是包含DNA序列数据的列表,每个数据集有三列分别是id data label,标签分别为0和1
data1 = pd.read_csv(r"D:\桌面\研0\Transformer\0.csv")
data2 = pd.read_csv(r"D:\桌面\研0\Transformer\1.csv")
# 合并
data = pd.concat([data1,data2], ignore_index=True)
X = data['data'].values
y = data['label'].values
print("X.shape:",end='')
print(X.shape)
print("y.shape:",end='')
print(y.shape)
# 将DNA序列数据转换为整数编码
def integer_encode(seq):
seq = seq.upper()
encoding = {'A': 0, 'T': 1, 'C': 2, 'G': 3}
return np.array([encoding[x] for x in seq])
X = np.array([integer_encode(seq) for seq in X])
y = np.array(y)
print("====转换成整数编码后====")
print("X.shape:",end='')
print(X.shape)
print("y.shape:",end='')
print(y.shape)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建PyTorch数据集和数据加载器
class DNADataset(torch.utils.data.Dataset):
def __init__(self, X, y):
self.X = torch.tensor(X, dtype=torch.long) # 将输入数据转换为长整型
self.y = torch.tensor(y, dtype=torch.float32)
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
train_dataset = DNADataset(X_train, y_train)
test_dataset = DNADataset(X_test, y_test)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=32, shuffle=False)
# 定义PositionalEncoding
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# pe的维度(位置编码最大长度,模型维度)
pe = torch.zeros(max_len, d_model)
# 维度为(max_len, 1):先在[0,max_len]中取max_len个整数,再加一个维度
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 位置编码的除数项:10000^(2i/d_model)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-np.log(10000.0) / d_model))
# sin负责奇数;cos负责偶数
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
#维度变换:(max_len,d_model)→(1,max_len,d_model)→(max_len,1,d_model)
pe = pe.unsqueeze(0).transpose(0, 1)
# 将pe注册为模型缓冲区
self.register_buffer('pe', pe)
def forward(self, x):
# 取pe的前x.size(0)行,即
# (x.size(0),1,d_model) → (x.size(0),d_model),拼接到x上
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
# 定义Transformer模型
class TransformerModel(nn.Module):
def __init__(self, input_dim, output_dim, d_model, nhead, num_layers, dim_feedforward, dropout):
super(TransformerModel, self).__init__()
# 创建一个线性变换层,维度input_dim4→d_model
self.embedding = nn.Embedding(input_dim, d_model) # 使用嵌入层
# 生成pe
self.pos_encoder = PositionalEncoding(d_model, dropout)
# 生成一层encoder
encoder_layers = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, dropout=dropout)
# 多层encoder
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers=num_layers)
# 维度d_model→output_dim
self.fc = nn.Linear(d_model, output_dim)
self.d_model = d_model
def forward(self, src):
src = src.permute(1, 0)
# 缩放
src = self.embedding(src) * np.sqrt(self.d_model)
# 加上位置嵌入
src = self.pos_encoder(src)
output = self.transformer_encoder(src)
# 调整输出形状为(batch, seq_len, d_model)
output = output.permute(1, 0, 2)
# 对所有位置的表示取平均
output = torch.mean(output, dim=1)
# 线性变换
output = self.fc(output)
# 使用sigmoid激活函数
output = torch.sigmoid(output)
return output
# 初始化模型
model = TransformerModel(input_dim=4,
output_dim=1,
d_model=128,
nhead=4,
num_layers=3,
dim_feedforward=256,
dropout=0.1)
# 定义损失函数和优化器
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
def train(model, iterator, optimizer, criterion):
# iterator是train_loader= DataLoader(train_dataset, batch_size=32)
model.train()
for batch in iterator:
# 初始化,防止梯度爆炸
optimizer.zero_grad()
X, y = batch
predictions = model(X)
# 计算修正损失函数
loss = criterion(predictions.squeeze(), y)
# 计算当前批数据的损失函数对模型参数的梯度
loss.backward()
# 根据梯度更新模型参数
optimizer.step()
# 测试模型
def evaluate(model, iterator, criterion):
print("===========test==========")
model.eval()
epoch_loss = 0
with torch.no_grad():# 此处不需要梯度计算
for batch in iterator:
X, y = batch
predictions = model(X)
loss = criterion(predictions.squeeze(), y)
epoch_loss += loss.item()
# 累加loss,再求平均
return epoch_loss / len(iterator)
# 开始训练
N_EPOCHS = 10
for epoch in range(N_EPOCHS):
print("第%d轮===================================="%(epoch+1))
train(model, train_loader, optimizer, criterion)
test_loss = evaluate(model, test_loader, criterion)
print(f'Epoch: {epoch+1:02}, Test Loss: {test_loss:.3f}')
我设置的epoch是10轮,每轮都会进行训练和测试,其中batch_size是32,每轮都会打印测试的平均loss,具体如下:
Epoch: 01, Test Loss: 0.641
Epoch: 02, Test Loss: 0.640
Epoch: 03, Test Loss: 0.669
Epoch: 04, Test Loss: 0.639
Epoch: 05, Test Loss: 0.638
Epoch: 06, Test Loss: 0.640
Epoch: 07, Test Loss: 0.638
Epoch: 08, Test Loss: 0.641
Epoch: 09, Test Loss: 0.639
Epoch: 10, Test Loss: 0.638
5、写在最后
第一次自行用Transformer模型实现二分类,过程很曲折,不过最后还好成功实现了。
各位大佬们如果有更好的模型实现思路,欢迎在评论区指教!
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 4841
4841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









