






一名来自新西兰的帅气小伙将大模型决策过程可视化了!
项目简介
llm-viz的主要目标是展示大型语言模型(LLM)的工作流程和内部机制。具体来说,它提供了一个GPT风格网络的工作实现的3D模型,即OpenAI的GPT-2、GPT-3(以及可能的GPT-4)中使用的网络拓扑结构的可视化。通过这个项目,用户可以更直观地理解LLM的内部架构和工作原理。
在llm-viz中,显示的第一个具有工作权重的网络是一个微小的网络,用于对字母A、B和C的小列表进行排序。这个演示示例模型是基于Andrej Karpathy的minGPT实现。渲染器还支持可视化任意大小的网络,尽管对于较大的网络,权重文件可能由于体积庞大(数百MB)而没有被下载。
如果在线玩感觉不过瘾,可以部署到本地,用户需要先安装依赖项,然后启动开发服务器即可进行本地运行
大模型可视化
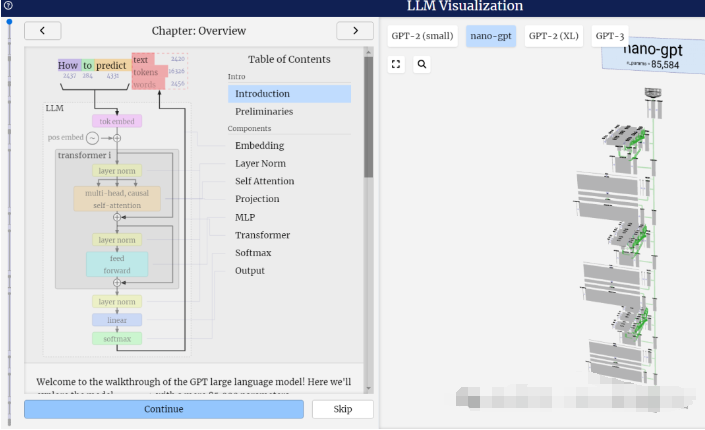
在此我们以nano-GPT为例,将推理过程进行了可视化。

左侧的图表展示了模型结构的全面概览,详细描绘了模型的整体框架及其各个组件的组成。
从上图中,我们可以清晰地看到nano-GPT是基于Transformer架构构建的。Transformer架构本质上是一种Encoder-Decoder结构,然而GPT模型独辟蹊径,仅采用了Decoder部分。在Decoder中,每个Token的输出仅依赖于当前输入Token之前的Token信息,因此Decoder主要被应用于文本生成任务,它通过自回归的方式预测下一个可能出现的单词。
当然,有仅采用Decoder的模型,自然也有仅利用Encoder的模型。Bert便是其中的佼佼者。在Encoder中,每个Token的输出都融合了所有输入Token的信息,这使得Encoder在文本理解方面表现尤为出色。
此外,还有一类模型同时使用了Encoder和Decoder,它们构成了典型的seq2seq架构。其中,Encoder负责捕获源序列的内在表示,而Decoder则将这些表示解码为目标序列。这种架构在诸如语言翻译、语音识别等应用中发挥了重要作用。

在选择模型整体或特定组件时,右侧界面支持鼠标交互功能,让您能够轻松获取所选部分的详细信息。
从上述图表中,我们可以清晰地看到LLM(大型语言模型)的工作流程。首先,它将输入的文本切分为Token,随后依据预定义的字典将这些Token转换为对应的字典索引,即IDs。紧接着,通过Word2Vec或其他自定义的Embedding技术,这些IDs被进一步转化为embedding向量,这些向量能够更好地捕捉文本中的语义信息。最后,这些向量被输入到Transformer编码器中进行深度处理。

特别值得一提的是,当您选择模型整体或其中某个组件时,右侧界面将实时播放各个组件处理数据的动画,让您能够直观地了解数据在模型中的流转过程,从而更深入地理解模型的工作原理。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









