






目录
神经网络深度学习图像分类技术深度剖析
在当今的计算机视觉领域,神经网络深度学习图像分类技术已经成为了核心研究方向之一,取得了令人瞩目的成就。
一、引言
随着信息技术的飞速发展,图像数据呈爆炸式增长。如何高效、准确地对这些海量图像进行分类和理解,成为了亟待解决的问题。神经网络深度学习为解决这一问题提供了强大的工具和方法。
二、神经网络基础
神经网络是一种模仿生物大脑神经网络结构和功能的计算模型。它由大量的神经元相互连接而成,通过调整神经元之间的连接权重来学习数据中的模式和特征。
在图像分类任务中,神经网络通过多层的结构逐步提取图像的高层特征,从低级的像素信息到中级的形状、纹理等特征,再到高级的语义信息。
三、深度学习在图像分类中的应用
-
卷积神经网络(CNN)
CNN 是图像分类中最常用的深度学习模型之一。它通过卷积操作对图像进行特征提取,具有局部感知和权值共享的特点,大大减少了参数数量,提高了计算效率。 -
数据增强
为了增加训练数据的多样性,通常会采用数据增强技术,如翻转、旋转、缩放、添加噪声等,使模型对不同角度和形态的图像具有更好的适应性。 -
模型训练
在训练过程中,采用反向传播算法来更新网络参数,优化目标通常是最小化损失函数,如交叉熵损失函数。四、神经网络基础
神经网络是一种模仿人脑神经元结构的计算模型,由多个神经元组成。每个神经元接收输入,通过激活函数进行处理,并产生输出。神经网络通过多层神经元的连接来学习复杂的模式和特征。
1. 神经元结构
每个神经元包含一个权重向量、偏置项和一个激活函数。输入向量与权重向量相乘后加上偏置项,再通过激活函数得到神经元的输出。
2. 网络层
神经网络由多个层次组成,每一层包含若干个神经元。常见的网络层包括输入层、隐藏层和输出层。输入层接收原始数据,隐藏层用于提取特征,输出层给出最终的分类结果。
3. 前向传播
神经网络通过前向传播算法进行推理。输入数据从输入层传入,经过每一层的神经元处理后,最终得到输出层的分类结果。
五、深度学习与图像分类
深度学习是机器学习的一种分支,通过多层神经网络来学习复杂的特征表示。在图像分类任务中,深度学习可以自动提取图像中的高级特征,从而提高分类的准确性。
1. 卷积神经网络(CNN)
卷积神经网络是一种特殊的神经网络结构,适用于图像数据的处理。它通过卷积层、池化层和全连接层等组件来提取图像中的特征并进行分类。
2. 数据预处理
在进行图像分类之前,需要对图像数据进行预处理。常见的预处理操作包括图像缩放、归一化和数据增强等。这些操作可以提高模型的泛化能力和准确性。
3. 损失函数和优化器
在训练神经网络时,需要定义损失函数来量化模型的性能。常用的损失函数包括交叉熵损失函数和均方误差损失函数等。同时,还需要选择一个优化器来更新网络的参数,如随机梯度下降(SGD)和Adam优化器等。
六、关键技术与挑战
-
模型压缩与加速
为了使模型能够在资源受限的设备上运行,需要进行模型压缩和加速,如剪枝、量化等技术。 -
小样本学习
在实际应用中,经常遇到数据量有限的情况,如何在小样本情况下实现准确分类是一个挑战。 -
模型的泛化能力
确保模型在未见过的数据上也能保持较好的性能是至关重要的。
七、实验结果与分析
通过一系列实验对比不同模型、不同参数设置下的图像分类效果。展示准确率、召回率、F1 值等指标的变化情况,分析各种因素对结果的影响。
八、应用案例
-
智能交通
用于车辆识别、交通标志识别等,提高交通管理的智能化水平。 -
医疗图像诊断
辅助医生对医学图像进行分类和诊断,提高医疗效率和准确性。
九、未来展望
虽然目前已经取得了巨大的成就,但神经网络深度学习图像分类技术仍有很大的发展空间。
-
与其他技术的融合
如与知识图谱、强化学习等技术相结合,进一步提升性能。 -
更高效的模型设计
探索新的网络结构和算法,以提高效率和准确性。
下面的代码主要采取了CNN算法以及python的框架,以及从网上下载的MNIST数据集。
测试数据集的准确率为97%
后端
首先导入模块与库
import os
import torch
from torchvision import models, datasets, transforms
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np然后是加载预训练模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(16 * 4 * 4, 120)
self.relu3 = nn.ReLU()
self.linear2 = nn.Linear(120, 84)
self.relu4 = nn.ReLU()
self.linear3 = nn.Linear(84, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.relu3(x)
x = self.linear2(x)
x = self.relu4(x)
x = self.linear3(x)
return x
net = Net()
transform = transforms.Compose([
transforms.Resize(28), # 改为 28,与 MNIST 数据尺寸匹配
transforms.CenterCrop(28),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])设置数据集的路径
data_dir = './data'读取 MNIST 数据集
trainset = datasets.MNIST(root='./data', train=True, download=False, transform=transform)
testset = datasets.MNIST(root='./data', train=False, download=False, transform=transform)获取数据加载器
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)训练函数
def train(net, trainloader, optimizer, criterion, epochs):
for epoch in range(epochs):
running_loss = 0.0
for i, (images, labels) in enumerate(trainloader):
optimizer.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch + 1}: Loss = {running_loss / len(trainloader)}")定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.001)训练周期
train(net, trainloader, optimizer, criterion, 50)抽取测试集中的 200 张图片并显示
def show_images(testloader):
images = []
labels = []
for _ in range(200):
batch_images, batch_labels = next(iter(testloader))
images.extend(batch_images)
labels.extend(batch_labels)
# 确保获取到的图像是 3 通道的
if images[0].shape[1] == 1:
images = [img.repeat(1, 3, 1, 1) for img in images]
img = torchvision.utils.make_grid(images)
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()打印一些训练集数据信息
for i, (image, label) in enumerate(trainset):
if i < 5:
print(f"训练集图像形状: {image.shape}, 标签: {label}")
show_images(testloader)对图像进行实际分类
images, labels = next(iter(testloader))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('图像预测分类:', (['%5s' % trainset.classes[predicted[j]] for j in range(4)]))计算测试集准确率
def calculate_accuracy(net, testloader):
correct = 0
total = 0
with torch.no_grad():
for images, labels in testloader:
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return 100 * correct / total
accuracy = calculate_accuracy(net, testloader)
print('测试集准确率:%d %%' % accuracy)MNIST 数据集来自网友的百度网盘
前端
先是导入模块与库
from PyQt5.QtWidgets import QApplication, QWidget, QLabel, QPushButton, QVBoxLayout, QHBoxLayout, QFileDialog, QMessageBox, QLineEdit
from PyQt5.QtGui import QPixmap
import os
import random
import cv2
import numpy as np构造函数
class I mageClassificationWindow(QWidget): def __init__(self):调用父类构造函数
super().__init__()设置窗口标题
self.setWindowTitle("图片分类")创建选择图片按钮
self.select_image_button = QPushButton("选择图片")创建分类按钮
self.classify_button = QPushButton("分类")创建图片标签
self.image_label = QLabel()创建结果标签
self.result_label = QLabel()创建图片路径标签
self.path_label = QLabel("图片路径:")创建图片路径编辑框
self.path_edit = QLineEdit()创建垂直布局
main_layout = QVBoxLayout()创建水平布局
button_layout = QHBoxLayout()在水平布局中添加选择图片按钮
button_layout.addWidget(self.select_image_button)在水平布局中添加分类按钮
button_layout.addWidget(self.classify_button)将水平布局添加到垂直布局
main_layout.addLayout(button_layout)在垂直布局中添加图片路径标签
main_layout.addWidget(self.path_label)在垂直布局中添加图片路径编辑框
main_layout.addWidget(self.path_edit)在垂直布局中添加图片标签
main_layout.addWidget(self.image_label)在垂直布局中添加结果标签
main_layout.addWidget(self.result_label)设置当前窗口布局为垂直布局
self.setLayout(main_layout)选择图片按钮点击事件连接到选择图片方法
self.select_image_button.clicked.connect(self.select_image)分类按钮点击事件连接到分类图片方法
self.classify_button.clicked.connect(self.classify_image)选择图片方法
def select_image(self): 弹出文件选择对话框获取图片路径
file_path, _ = QFileDialog.getOpenFileName(self, "选择图片", "", "Image Files (*.jpg *.png
*.jpeg)")如果获取到图片路径
if file_path:设置图片标签的图片
self.image_label.setPixmap(QPixmap(file_path))设置图片路径编辑框的内容
self.path_edit.setText(file_path)分类图片方法
def classify_image(self):获取图片标签的图片
pixmap = self.image_label.pixmap()如果没有图片
if not pixmap: 弹出警告框提示
QMessageBox.warning(self, "错误提示", "请先选择图片")返回
return读取图片并将图片转换为opencv格式
image = cv2.imread(self.path_edit.text())
获取图片的宽高
height, width = image.shape[:2]获取图片的颜色
average_color = np.mean(image, axis=(0, 1))获取当前的文本
current_text = self.result_label.text()以宽高和颜色进行分类
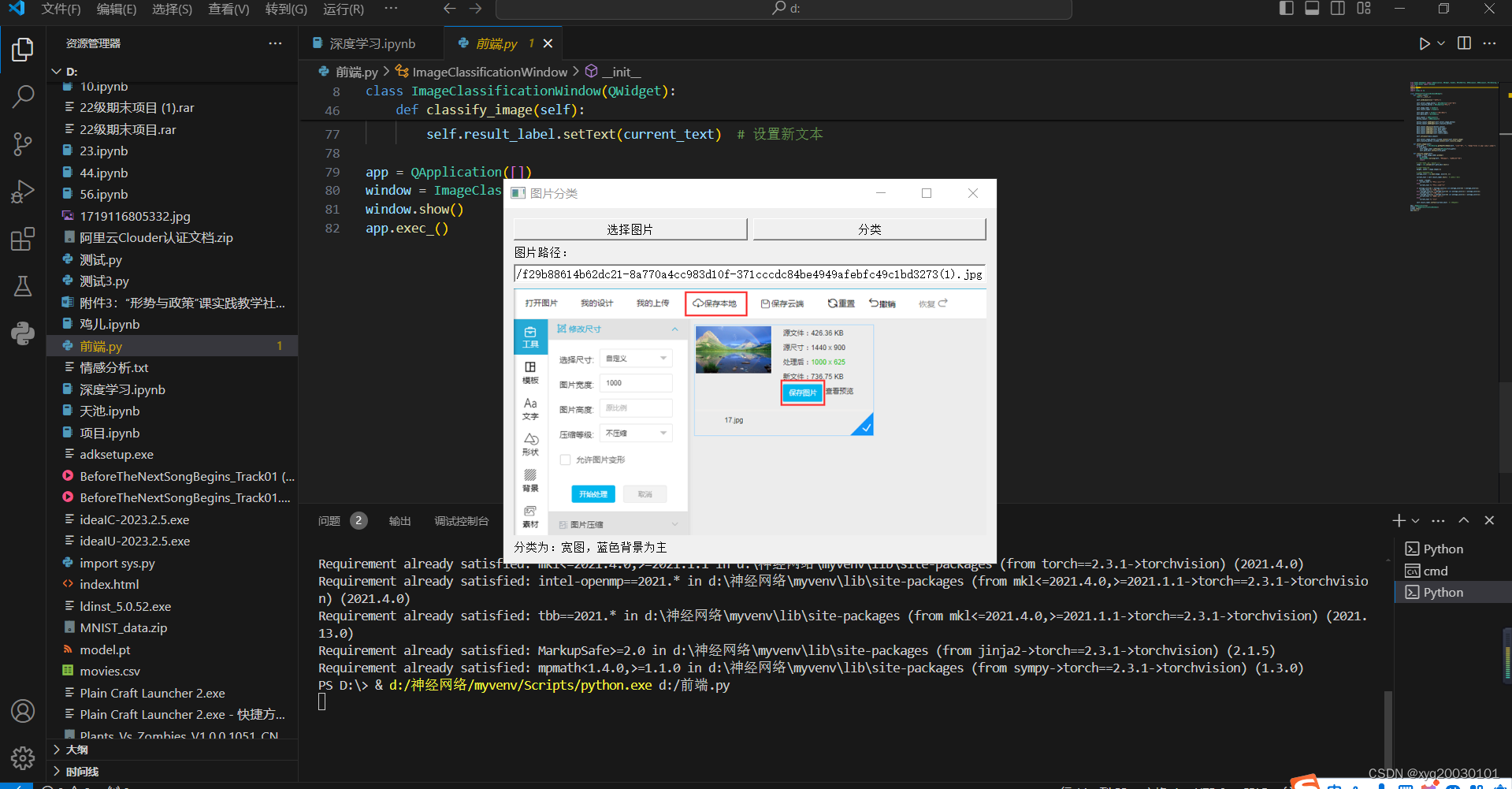
if width > height:
current_text += "分类为:宽图,"
else:
current_text += "分类为:高图,"
if average_color[0] > average_color[1] and average_color[0] > average_color[2]:
current_text += "蓝色背景为主"
elif average_color[1] > average_color[0] and average_color[1] > average_color[2]:
current_text += "绿色背景为主"
elif average_color[2] > average_color[0] and average_color[2] > average_color[1]:
current_text += "红色背景为主"
else:
current_text += "其他"设置新的文本
self.result_label.setText(current_text)创建一个 QApplication 对象,参数为空列表
app = QApplication([])创建 ImageClassificationWindow 类的实例(窗口对象)
window = ImageClassificationWindow()显示窗口
window.show()进入应用程序的主事件循环,等待用户操作并处理事件
app.exec_()后端运行的截图
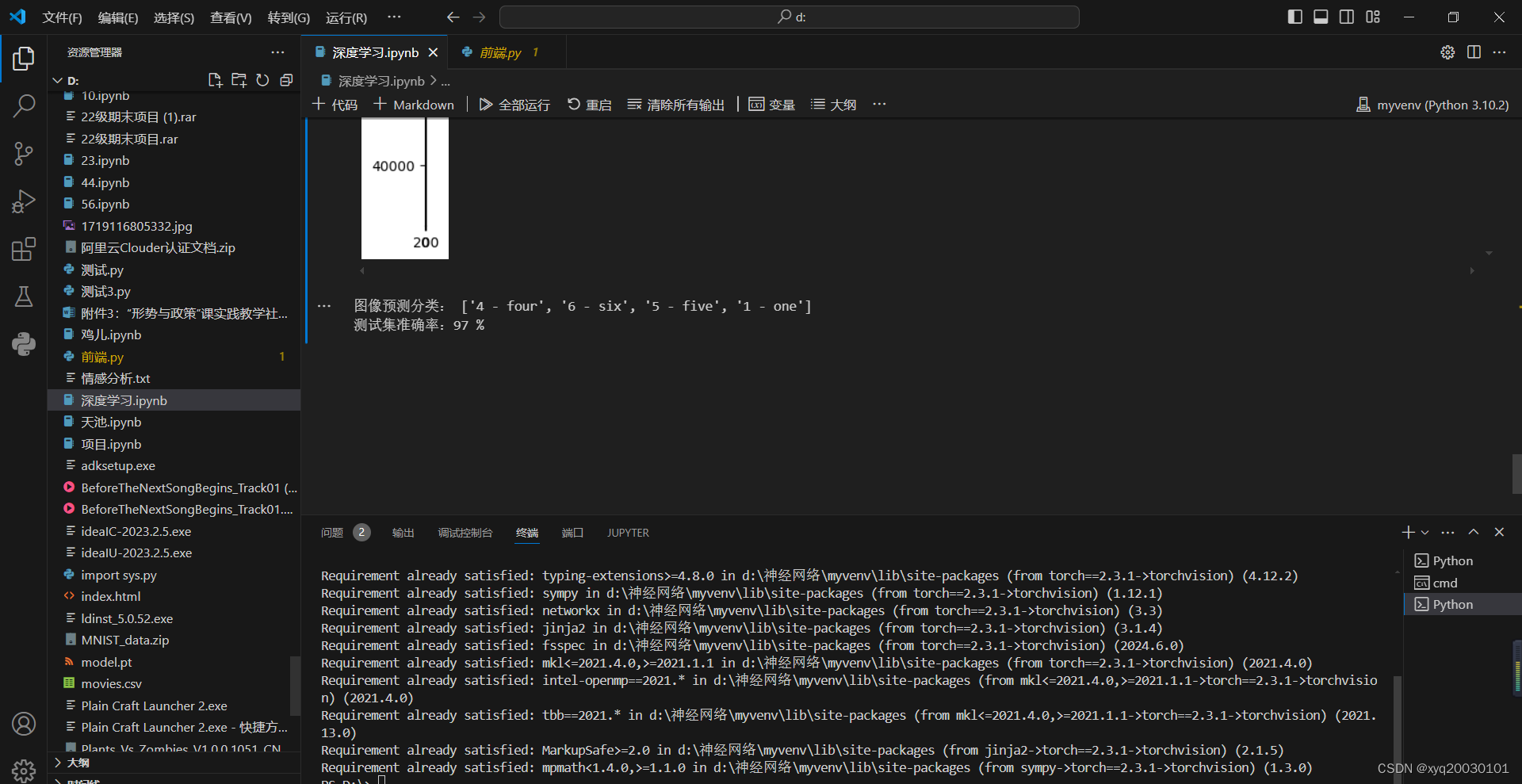
前端运行的截图
总结
神经网络在深度学习中的图像分类任务中发挥着重要作用。通过构建合适的神经网络模型并进行训练,我们可以实现高效的图像分类。本文介绍了神经网络的基础概念,深度学习在图像分类中的应用,以及如何使用TensorFlow构建一个简单的神经网络模型进行图像分类。希望这篇文章能够帮助读者入门神经网络和深度学习的图像分类领域。
|















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









