







作者: 帝国理工,伦敦米德尔塞克斯大学,InsightFace
paper: https://arxiv.org/pdf/1905.00641.pdf
github: https://github.com/deepinsight/insightface/tree/master/RetinaFace
1.摘要
摘要: 虽然在未受控制的人脸检测方面取得了巨大进步,但野外准确有效的面部定位仍然是一个开放的挑战。这篇文章提出了一个强大的单阶段人脸检测器,名为RetinaFace,它利用联合监督和自我监督的多任务学习,在各种人脸尺度上执行像素方面的人脸定位。具体来说,我们在以下五个方面做出了贡献:(1)我们在WIDER FACE数据集上手动注释五个面部标志,并在这个额外的监督信号的帮助下观察硬面检测的重要改进。 (2)我们进一步增加了一个自监督网格解码器分支,用于与现有的受控分支并行地预测像素三维形状的面部信息。 (3)在WIDER FACE硬测试装置上,RetinaFace的性能优于现有技术平均预测(AP)1.1%(达到AP等于91.4%)。 (4)在IJB-C测试集上,RetinaFace使最先进的方法(ArcFace)能够改善他们在面部验证中的结果(FAR = 1e-6的TAR = 89.59%)。 (5)通过采用轻量级骨干网络,RetinaFace可以在单个CPU内核上实时运行,以实现VGA分辨率的显示。
2. 人脸检测任务引言
nsight Face在2019年提出的最新人脸检测模型,原模型使用了deformable convolution和dense regression loss, 在 WiderFace 数据集上达到SOTA。截止2019年8月,原始模型尚未全部开源,目前开源的简化版是基于传统物体检测网络RetinaNet的改进版,添加了SSH网络的检测模块,提升检测精度,作者提供了三种基础网络,基于ResNet的ResNet50和ResNet152版本能提供更好的精度,以及基于mobilenet(0.25)的轻量版本mnet,检测速度更快。
与通用物体检测不同,人脸检测具有较小的比率变化。1:1到1:1.5
但是人脸的尺度变化比较大,从几个像素到几千个像素
借鉴MTCNN,加入5个人脸关键点,提升检测算法在hard部分的精度
通过自监督学习使用网格解码器分支来预测与现有监督分支并行的像素级三维人脸形状
3. 相关工作
图像金字塔or特征金字塔
一阶段or二阶段
背景建模
SSH等通过在特征图中引入上下文建模提高小人脸的检测。可变性卷积(DCN)也有助于提高精度
多目标损失
在人脸检测中加入人脸关键点的检测有助于提高box的回归精度。如果MASK RCNN增加一个分割分支一样。
4.Retinaface
4.1 多损失
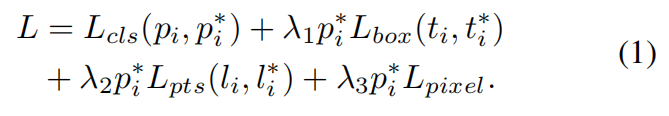
分别是分类(focal loss),box回归(IOU loss),人脸关键点,密集的回归损失(这个不懂)
4.2
采用mesh decoder来编码连接形状和纹理信息
5.实验
采用wider face数据进行训练
根据图片的清晰质量,标注了人脸的5个关键点,有些不可见的则不标注

5.2 应用细节
加入了FPN
在5个金字塔特征图中加入了独立的上下文模块提高建模能力
还用可变形卷积网络(DCN)替换了横向连接和上下文模块中的所有3×3个卷积层
多正样本,采用同样的损失头和不同的特征图在计算多损失
anchor的设定:在从P2到P6的特征金字塔级别上使用特定比例的锚点
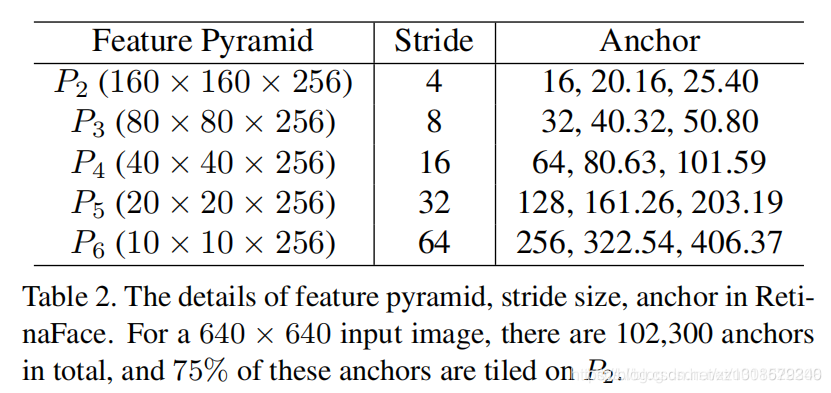
采用OHEM优化正负anchor不平衡的问题
因为wider face有20%的小人脸,于是在增强的时候,以图像的短边为基准,随机resize [0.3, 1],在调整成640*640的方形块,如果人脸的中心点在方形块中,则保留这个人脸。
图像增强
因为wider face有20%的小人脸,于是在增强的时候,以图像的短边为基准,随机resize [0.3, 1],在调整成640*640的方形块,如果人脸的中心点在方形块中,则保留这个人脸。
测试策略
翻转,多尺度,投票策略(实际应用这些都没啥用),不过竞赛的时候,这些还是很有用的。
分析
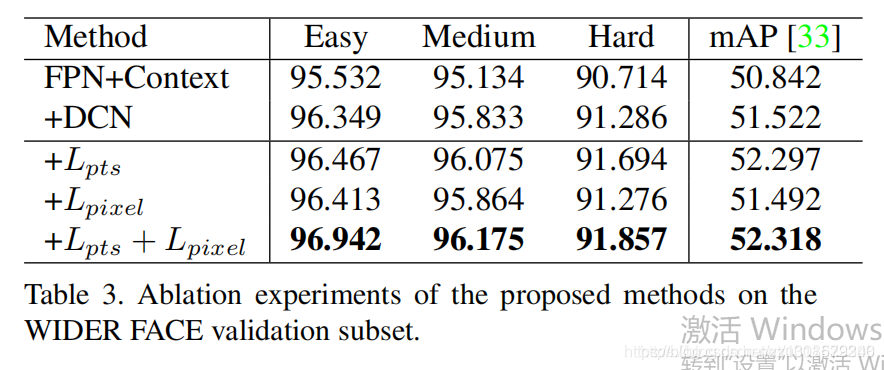
加DCN有用,0.x的提升
加上关键点分支有用, 1左右的提升
6.简化版mnet结构
RetinaFace的mnet本质是基于RetinaNet的结构,采用了特征金字塔的技术,实现了多尺度信息的融合,对检测小物体有重要的作用,RetinaNet的结构如下
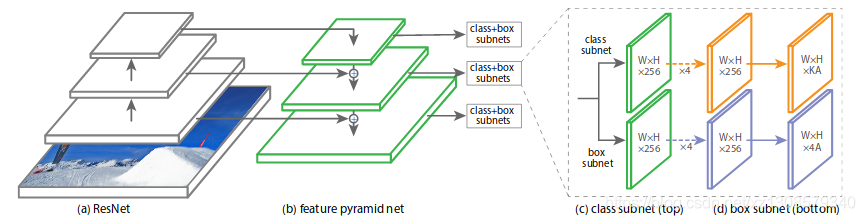
简化版的mnet与RetinaNet采用了相同的proposal策略,即保留了在feature pyramid net的3层特征图每一层检测框分别proposal,生成3个不同尺度上的检测框,每个尺度上又引入了不同尺寸的anchor大小,保证可以检测到不同大小的物体。
简化版mnet与RetinaNet的区别除了在于主干网络的选择上使用了mobilenet做到了模型的轻量化,最大的区别在于检测模块的设计。mnet使用了SSH检测网络的检测模块,SSH检测模块由SSH上下文模块组成
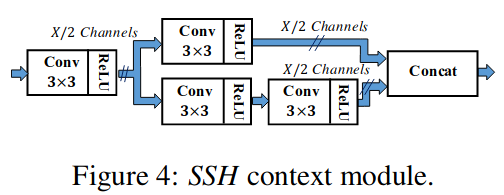
上下文模块的作用是扩张预检测区域的上下文信息。上下文模块和conv结合组成了一个检测模块
7.文章的思路
为了速度,所以在一阶段的通用检测器上进行改进,而retina检测算法又是当前精度最高的。
入了上下文建模模块,DCN等小的部件
加入了人脸关键点分支,这个确实有一定作用
多损失函数的融合。
自监督方法的引入。














 46
46











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









