






一、什么是大模型?
近年来,人工智能领域掀起了一股"大模型"热潮。所谓大模型,指的是拥有数十亿甚至数千亿参数的机器学习模型。这些模型从海量的训练数据中学习到了丰富的知识和特征,具有强大的学习和泛化能力。大模型之所以引起广泛关注,主要有以下几个显著特点。
01 参数数量巨大
大模型通常拥有数十亿甚至数千亿的参数,这些参数是模型从训练数据中学习得到的。这使得大模型能够学习到更加细致和复杂的数据特征。
以OpenAI的GPT-3为例,它拥有1750亿个参数,这是当时最大的语言模型。相比之下,早期的语言模型如GPT-1只有1.5亿个参数。参数数量的大幅增加,使得大模型能够捕捉到更加细微的语义关系和上下文信息。

02 学习能力强大
由于参数多,大模型能够从大量的训练数据中提取出更加细致和复杂的特征。这使得它们在各种任务上表现出色,如自然语言处理、计算机视觉、语音识别等。
以BERT为例,它在多项NLP基准测试中取得了突破性进展,超越了人类水平。这种强大的学习能力,使得大模型可以胜任从问答、文本生成到情感分析等各种复杂的语言任务。
在计算机视觉领域,大模型也展现出了出色的性能。
例如,OpenAI的DALL-E 2可以根据文本描述生成高度逼真的图像,在创造力和想象力方面堪比人类。这种跨模态的学习能力,使得大模型不再局限于单一的感知通道,而是能够融合多种信息源,产生更加丰富的输出。
03 泛化能力强
大模型通常具有较好的泛化能力,即在未见过的数据上也能表现出较好的性能。这使得它们可以应用于各种场景,而不仅局限于特定的任务。以GPT-3为例, 它可以胜任从文本生成、问答到代码编写等各种任务,展现出了很强的通用性。
这种泛化能力,使得大模型可以成为通用的智能助手,为人类提供各种服务。
04 计算资源需求大
训练大模型需要大量的计算资源,包括高性能的GPU/TPU等硬件以及大量的存储空间。
以GPT-3的训练为例,它需要消耗数百万美元的计算资源。这给模型的训练和部署都带来了一定的挑战。
只有少数科技公司和研究机构,才有能力投入如此庞大的计算资源。这也加剧了人工智能领域的"马太效应",使得少数玩家垄断了大模型的开发和应用。
05 数据需求量大
大模型往往需要大量的训练数据来避免过拟合,并充分发挥其性能。以GPT-3为例,它的训练数据包括了从网页、书籍到维基百科等海量的文本信息。
这对于数据收集和标注提出了更高的要求,需要投入大量的人力和财力。据坊间传闻,OPENAI在早期训练GPT时就花大价钱请了大量外包公司来帮助标记数据。同时,由于训练数据的广泛性,大模型也可能从中学习到一些有偏见或不恰当的内容,这也是需要重点关注的问题。
总的来说,大模型之所以引起广泛关注,是因为它们在学习能力、泛化能力以及应用广度等方面都展现出了前所未有的优势。这使得它们成为人工智能领域的新宠,正在推动各个应用领域的进步。
二、大模型的应用领域
大模型在自然语言处理(NLP)、计算机视觉、语音识别等多个领域都有广泛的应用。
01 自然语言处理
在NLP领域,大模型已经成为事实标准。
谷歌的BERT、OpenAI的GPT系列、微软的GPT-Neo等,都是这个领域的代表作。以BERT为例,它是一个基于Transformer的双向语言模型,在多项NLP基准测试中取得了突破性进展,如问答、文本分类、命名实体识别等。
BERT的成功,在很大程度上得益于它强大的上下文建模能力。与传统的单向语言模型不同,BERT可以同时考虑文本的左右上下文信息,从而更好地捕捉语义关系。这使得BERT在理解自然语言方面有了质的飞跃。
除了BERT,OpenAI的GPT系列也取得了令人瞩目的成就。GPT-3作为目前最大的语言模型,拥有1750亿个参数,在文本生成、问答、翻译等任务上都展现出了出色的性能。
而GPT的强大之处在于它能够利用海量的训练数据,学习到丰富的语言知识和常识,从而具备了非常强大的生成能力,以目前的性能来说,输出一篇还看得过去的文章那都是分分钟的事情。
这些大模型的出现,不仅提升了NLP任务的性能,也极大地拓展了其应用场景。从智能问答、对话系统,到内容生成、代码编写,大模型都展现出了强大的能力。
未来,它们有望成为通用的智能助手,为人类提供各种语言服务。
02 计算机视觉
在计算机视觉领域,大模型也展现出了出色的性能。
例如,OpenAI的DALL-E 2可以根据文本描述生成高度逼真的图像,在创造力和想象力方面堪比人类。DALL-E 2的成功,得益于它在视觉和语言之间建立了强大的联系。
它不仅能够理解文本描述中的语义信息,还能够根据这些信息生成对应的视觉内容。这种跨模态的学习能力,使得DALL-E 2可以胜任从图像生成、编辑到视觉问答等各种视觉任务。

另一个例子是商汤科技开发的大模型。它们在图像分类、目标检测等基准测试中,都取得了超越人类水平的成绩。这些模型能够从海量的视觉数据中学习到丰富的视觉特征,从而在各种视觉任务上展现出卓越的性能。
值得一提的是,这些大模型不仅在感知层面表现出色,在理解层面也有了长足进步。例如,DALL-E 2不仅能生成逼真的图像,还能够理解图像中的语义信息,回答与图像相关的问题。
例如OpenAI今年发布的基于Transformer架构的视频生成大模型Sora。它可以根据文本描述生成长达60秒的高清视频,包含写实的背景、复杂的镜头角度以及富有情感的多角色叙事。
Sora不仅可以根据文本生成视频,还可以基于现有图像或视频进行编辑,如创建完美循环的视频、动画静态图像等。它还展现出了一些模拟物理世界特性的能力,如动态相机运动、长期一致性和对象持久性等。
研究人员认为,Sora的出现标志着视频创作领域迎来了"iPhone时刻"。它可以大幅提高创作者的效率和创造力,在游戏、电影、广告等领域都有广泛应用前景。
这种视觉-语言的融合,使得大模型具备了更加人性化的交互能力。总的来说,大模型正在重塑计算机视觉的边界,使得机器在视觉感知和理解方面的能力与日俱增。
03 语音识别
在语音识别领域,大模型也显示出了强大的能力。
例如,微软的Whisper模型,可以准确识别复杂的语音信号,在多种语音识别基准测试中取得了领先成绩。
Whisper的成功,得益于它能够从海量的语音数据中学习到丰富的声学特征。与传统的基于HMM的语音识别系统不同,Whisper采用了基于Transformer的端到端架构,能够更好地捕捉语音信号中的上下文信息。这使得它在处理复杂的语音场景,如多人对话、背景噪音等方面,都展现出了出色的鲁棒性。
除了语音识别,大模型在语音合成领域也取得了长足进步。例如,谷歌的WaveNet和DeepSpeech,可以生成高保真度、自然流畅的语音输出。这些模型不仅能够模拟人类的发音特点,还能够根据上下文信息,生成富有感情和韵律的语音。
最近大火的Suno也是一个很好的案例,用户只需输入几句歌词或歌名,并选择音乐风格,就可以在1分钟内生成2分钟左右的歌曲。即使是对音乐一窍不通的小白,也能通过简单的4步操作就完成歌曲创作。生成的歌曲旋律流畅,让不少人感到惊喜。
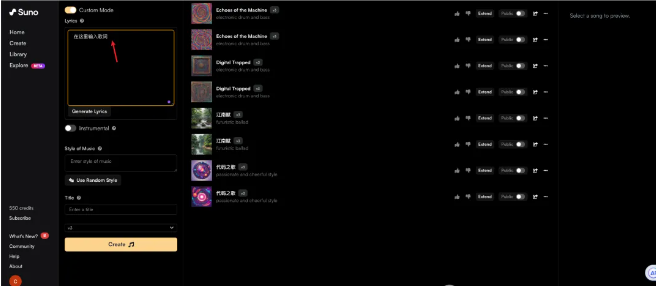
总的来说,大模型正在重塑语音技术的边界,使得机器在感知和生成语音方面的能力与日俱增。未来,它们有望成为通用的语音助手,为人类提供各种语音服务。
三、大模型的挑战
尽管大模型取得了令人瞩目的成就,但它们在训练和部署过程中也面临着一些重大挑战。
01 训练成本高昂
训练大模型需要大量的计算资源和海量的训练数据,这意味着巨大的时间和金钱成本。

以GPT-3的训练为例,据估计需要消耗数百万美元的计算资源。这使得只有少数科技公司和研究机构才有能力开发这样的模型。
这种高昂的训练成本,加剧了人工智能领域的"马太效应"。只有少数拥有雄厚资金和算力的玩家,才能够开发出大模型。
这可能会导致人工智能技术的垄断,限制其在社会中的普及和应用。同时,高昂的训练成本也可能会阻碍新的创新者进入这个领域。如果只有少数巨头能够开发出大模型,那么人工智能的发展就可能失去多元化和活力。这对于推动技术进步和社会公平,都会产生不利影响。
02 对计算资源的需求大
大模型在训练和推理过程中对计算资源的需求非常大,这对于模型的部署和应用带来了一定的限制。

以GPT-3为例,它在推理时需要消耗大量的GPU资源。这使得它很难在普通的计算设备上运行,只能部署在专门的云计算平台上。这不仅增加了使用成本,也限制了大模型在边缘设备上的应用。
此外,大模型的计算需求还可能对环境造成一定的负面影响。训练和运行这些模型需要大量的电力和计算资源,这可能会增加碳排放,加剧气候变化。这需要我们在开发大模型时,也要考虑其环境影响,采取更加节能环保的计算策略。
大家常说的大模型之争最终会演变为能源之争,也是不无道理的。
03 数据偏见的放大
大模型从海量的训练数据中学习知识,但这些数据可能存在一些偏见。
例如,语言模型可能会学习到一些性别、种族等方面的刻板印象;图像生成模型可能会产生不公平的视觉输出。
这些偏见可能会被放大并传播到模型的输出中,从而产生不公平或有害的结果。这种数据偏见的放大,,不仅会影响大模型的公平性和可靠性,也可能加剧社会中的不平等。
因此,在开发大模型时,我们需要格外重视数据偏见的问题,采取有效的缓解措施,如数据增强、模型微调等。
04 虚假信息的生成
大模型强大的生成能力,也可能被用于制造虚假信息和欺骗。
例如,语言模型可以生成高度逼真的虚假新闻和谣言;图像生成模型可以制造出虚假的视觉内容。这对于信息真实性和社会秩序都构成了严重威胁。
去年4月25日,甘肃平凉市公安局崆峒分局网安大队在巡查中发现,某平台账号中发布了一条标题为“今晨甘肃一火车撞上修路工人 致9人死亡”的“新闻”。
如此骇人听闻,“新闻”的点击量很快超过了1.5万,但经过调查发现,这只是犯罪嫌疑人洪某利用AI软件ChatGPT炮制的谣言。

这种"deepfake"技术的出现,使得人们很难区分真假信息。这不仅可能误导公众,还可能被用于政治操纵、金融欺诈等非法用途。因此,我们需要加强对大模型生成内容的监管和审核,同时也要提高公众的识别能力,共同应对这一挑战。
05 隐私和安全风险
大模型可能会泄露一些敏感信息,或被用于非法用途,给个人隐私和社会安全带来风险。
例如,语言模型可能会记录用户的对话内容,从而侵犯个人隐私;图像生成模型也可能被用于制造虚假的视觉内容,威胁社会安全。
这些风险需要我们在开发和使用大模型时,充分考虑隐私和安全因素,采取有效的保护措施。总的来说,大模型的发展虽然带来了巨大的机遇,但也面临着诸多挑战。
我们需要在享受技术红利的同时,也要警惕其潜在的风险和负面影响,采取有效的应对措施,确保大模型的发展能够造福人类,而不是危害人类。
四、大模型的伦理问题
大模型的发展不仅带来了技术挑战,也引发了一系列伦理问题,需要我们格外重视。
01 艺术创作的独创性
大模型在图像生成、音乐创作等领域展现出了强大的能力,这引发了艺术家对创作独创性的担忧。
一些艺术家担心自己的作品会被AI复制和滥用,影响了创作的独特性和价值。例如,当DALL-E 2可以根据文本描述生成逼真的图像时,一些艺术家担心自己的绘画作品会被AI模仿和取代。同样,当GPT可以生成高质量的文学作品时,一些作家也担心自己的创作会被AI取代,电影、音乐等等领域都存在这样的担忧,这种担忧引发了艺术界的广泛反思。一些艺术家拒绝让AI使用自己的作品,影视公司也禁止使用AI生成的内容。
我们需要在发展大模型的同时,也要充分考虑艺术创作的特殊性,制定相应的伦理规范,保护艺术家的权益。只有这样,大模型的发展才能与艺术创作和谐共存。
02 社会公平
大模型在一些关键领域的应用,也可能导致社会公平性问题。

例如,在招聘、贷款等领域,如果AI系统的决策存在偏见,可能会导致某些群体受到歧视。这不仅违背了公平正义的原则,也可能加剧社会的不平等。
同样,如果大模型在教育、医疗等公共服务中被滥用,也可能造成资源分配的不公。这可能使得弱势群体无法平等地获得这些服务,进一步加深社会的分裂。
03 人性尊严
有很多人担心,人机融合会导致人类失去独立性和自主性,从而失去作为人的核心价值。当AI可以完全取代人类的某些工作时,人们担心会失去谋生的能力,从而失去作为人的尊严。
同样,当AI可以模拟人类的情感和行为时,人们也担心会失去自我意识和独特性。
这种担忧反映了人们对于人性价值的重视。我们需要在追求技术进步的同时,也要维护人类的核心价值,确保大模型的发展不会侵犯人的尊严和自主性。
总的来说,大模型的发展不仅带来了技术挑战,也引发了一系列伦理问题。我们需要在享受技术红利的同时,也要警惕其潜在的风险,制定相应的伦理规范,确保大模型的发展能够造福人类,而不是危害人类。只有这样,我们才能在这个新的人工智能时代中,创造一个更加美好的未来。
未来展望
随着技术的不断进步,大模型的规模和能力还在持续增长。研究者们也在探索更高效的训练方法和更环保的计算策略,以应对大模型带来的挑战。
未来,大模型可能会成为人工智能领域的新标准,推动各个应用领域的快速发展。作为普通人,我们无需过度担忧它们可能带来的风险,而是要积极拥抱大模型,学习和使用它来为我们解决工作、生活中遇到的各种问题,让我们获得更多的自由和创造力。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









