







- 关于CART
Classification And Regression Tree,即分类回归树算法,简称CART算法,它是决策树的一种实现,通常决策树主要有三种实现,分别是ID3算法,CART算法和C4.5算法。 CART算法是一种二分递归分割技术,把当前样本划分为两个子样本,使得生成的每个非叶子结点都有两个分支,因此CART算法生成的决策树是结构简洁的二叉树。由于CART算法构成的是一个二叉树,它在每一步的决策时只能是“是”或者“否”,即使一个feature有多个取值,也是把数据分为两部分。。
第一步是计算Gini指数
Gini指数是用于评估数据集的成本函数的名称。
数据集的拆分用于将训练模式划分为两组,基尼指数的值可以反映出通过切分创建的两个组中的类的混合程度,通过基尼指数可以了解切分的好坏程度。完美的切分得到的基尼指数为0,而最差情况的切分即每组50/50分类使得基尼指数为0.5(对于2分类问题)。
举个例子,我们有两组数据,每组有2行。 第一组中的行都属于类0,第二组中的行属于类1,因此它是完美的切分。
我们首先需要计算每组中类的比例
proportion = count(class_value) / count(rows)
根据上面例子给的描述,每组中的比例应该如下
group_1_class_0 = 2 / 2 = 1
group_1_class_1 = 0 / 2 = 0
group_2_class_0 = 0 / 2 = 0
group_2_class_1 = 2 / 2 = 1
然后计算Gini指数
gini_index = sum(proportion * (1.0 - proportion))
gini_index = 1.0 - sum(proportion * proportion)
然后,必须根据组的大小,相对于父组中的所有样本,对每组的基尼系数进行加权。我们可以将此权重添加到组的Gini计算中,如下所示:
gini_index = (1.0 - sum(proportion * proportion)) * (group_size/total_samples)
在这个例子中,每组的基尼指数的值分别计算如下
Gini(group_1) = (1 - (11 + 00)) * 2/4
Gini(group_1) = 0.0 * 0.5
Gini(group_1) = 0.0
Gini(group_2) = (1 - (00 + 11)) * 2/4
Gini(group_2) = 0.0 * 0.5
Gini(group_2) = 0.0
下面是一个名为gini_index()的函数,它计算各组的Gini指数

给出数据

运行后会打印两个Gini指数,首先是最差情况的0.5,然后是最佳情况的0.0。

第二步是切分
切分涉及三个部分,第一部分我们是计算基尼指数。 剩下的两部分是:
切分数据集。
评估所有切分情况。
切分数据集:
切分数据集意味着在给定属性索引和该属性的切分值的情况下将数据集分成两个列表。
分成这两个组后我们就可以使用上面的Gini指数来评估切分的好坏。
切分数据集涉及迭代每一行,检查属性值是低于还是高于切分值,并分别将其分配给左侧或右侧组。
下面是一个名为test_split()的函数,它实现了这个过程。
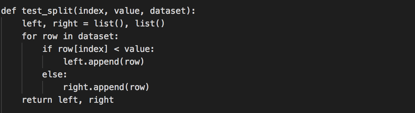
评估所有切分情况:
通过上面的Gini函数和test_split函数,我们现在可以进行评估了。
给定一个数据集,我们必须检查每个属性的每个值作为候选切分,评估切分的成本并找到我们可以做出的最佳切分。
找到最佳切分后,我们可以将其用作决策树中的节点。
我们将使用字典来表示决策树中的节点,因为我们可以按名称存储数据。当选择最佳切分并将其用作树的新节点时,我们将存储所选属性的索引,要切分的属性的值和由所选切分点切分的两组数据。
每组数据其实就是拆分过程分配给左侧或者右侧组的子集。想象一下,在构建决策树时递归地再次拆分每个组。
下面是一个名为get_split()的函数,它实现了这个过程。 可以看到它迭代每个属性,然后遍历该属性的每个值,切分和评估切分情况。
然后记录最佳的切分,在所有检查完成后返回。
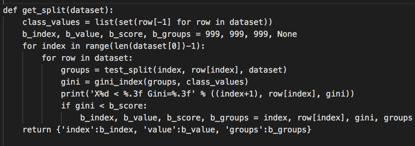
我们给出一个小数据集来测试这个函数和我们的整个数据集的拆分过程。
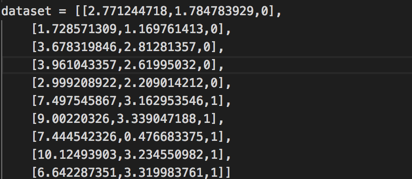
结果如下

程序打印出每个切分点,并评估它的基尼指数。
运行该示例打印所有Gini指数,然后在X1 <6.642的数据集中打印最佳切分的分数,此时基尼指数为0.0。
第三步是创建树
创建树的根节点很简单,在整个数据集上调用get_split就好了.构建树分为三步,
终端节点。
递归拆分。
建造一棵树。
终端节点:
我们需要确定何时终止树的增长。
我们可以使用节点在训练数据集的行的深度和行数来确定。
最大树深度:这是树的根节点的最大节点数。 一旦满足树的最大深度,我们必须停止拆分添加新节点。更深的树更复杂,更有可能过度拟合训练数据。
最小节点记录:这是给定节点的训练模式数目的最小值。一旦达到或低于此最小值,我们必须停止拆分和添加新节点。训练模式太少的节点过于具体,这有可能会过度拟合训练数据。
我们在指定的点停止增长时,该节点被称为终端节点并用于进行最终预测。
这是通过获取分配给该节点的行组并选择组中最常见的类值来完成的,这将被用于进行预测。
下面名为to_terminal()的函数,它将为一组行选择一个类值,返回行列表中最常见的输出值。

递归拆分:
现在我们已经知道如何以及何时创建终端节点,接下来就是构建树了。
构建决策树涉及在为每个节点创建的组上反复调用上面的get_split()函数。
添加到现有节点的新节点称为子节点。节点可以具有零个子节点(终端节点),一个子节点(一侧直接进行预测)或两个子节点。我们将在给定节点的子节点称为左或右。
创建节点后,我们可以通过再次调用相同的函数,对拆分中的每组数据递归创建子节点。
下面是一个实现此递归过程的函数。 它将节点,节点中的最大深度,最小模式数和节点的当前深度作为参数。
函数可以用以下步骤解释:
首先,提取节点分割的两组数据以供使用并从节点中删除。当我们处理这些组时,节点不再需要访问这些数据。
接下来,我们检查左侧或右侧行组是否为空,如果为空,我们使用我们拥有的记录创建终端节点。
然后我们检查是否已达到最大深度,如果是,我们创建一个终端节点。
然后我们处理左子节点,如果行组太小则创建终端节点,否则以深度优先方式创建和添加左节点,直到在该分支上到达树的底部。
然后以相同的方式处理右侧,因为我们将构造的树恢复到根。

接下来构建树:
构建树要创建根节点并调用split(),然后递归调用自身以构建整个树,下面的函数实现这个功能

这一部分完整代码在3.py,同样给出数据
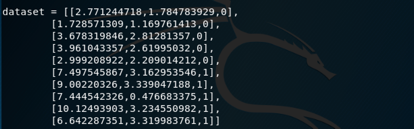
进行测试
我们看到在结果中打印出了我们上一步给出的完美切分

我们再把深度加到2,强迫树进行拆分,然后根节点的左右子节点再次使用X1属性来拆分。
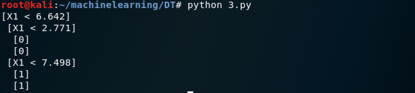
还可以继续加深
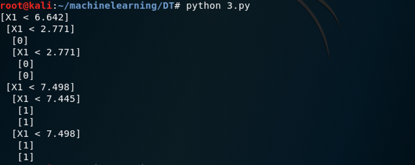
第四步是做出预测
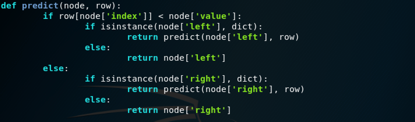
我们可以使用递归函数实现此功能,其中使用左子节点或右子节点再次调用相同的预测例程,具体取决于拆分如何影响提供的数据。
我们必须检查子节点是否是要作为预测返回的终端值,或者它是否是包含要考虑的另一级树的节点。
下面是实现此过程的predict()函数,我们可以看到给定节点中的索引和值如何用于评估提供的数据行是否位于拆分的左侧或右侧。
给出数据
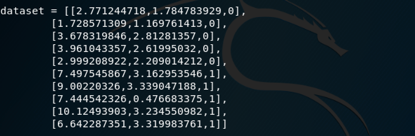
结果如下,打印出了每行正确的预测值
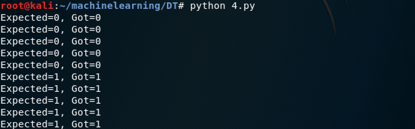
决策树的实现过程就是这样子,接下来我们解决实际问题,数据集名为data_banknote_authentication.csv
数据集涉及根据从照片中采取的若干措施来预测给定钞票是否是真实的。
数据集包含1,372行,包含5个数字变量,分别是小波变换图像的方差,小波变换图像的偏差,小波峰度变换图像,图像熵,类值。这是二分类问题。
本节将CART算法应用于Bank Note数据集。
第一步是加载数据集并将加载的数据转换为可用于计算分割点的数字。

我们将使用5折交叉验证来评估算法。 这意味着每折中将使用1372/5 = 274.4个记录。函数evaluate_algorithm()使用交叉验证来评估算法

precision_metric()计算预测的准确性。

decision_tree()是CART算法的实现,基于上面的函数,首先从训练数据集创建树,然后使用树对测试数据集进行预测。
完整代码在CART.py
运行结果如下

打印出了5折各自的准确率,以及平均的准确率
参考:
1.<机器学习实战>
2https://zhuanlan.zhihu.com/p/32003259AD%E7%AE%97%E6%B3%95
3.<机器学习>(周志华的西瓜书)
4. https://machinelearningmastery.com/category/algorithms-from-scratch/














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









