






Xie S, Yang T, Wang X, et al. Hyper-class augmented and regularized deep learning for fine-grained image classification[C]// IEEE Conference on Computer Vision and Pattern Recognition. 2015.
车型识别“Hyper-class Augmented and Regularized Deep Learning for Fine-grained Image Classification”
介绍
难点:
- 精细粒度的标记数据的获取要昂贵得多(通常需要专业领域);
- 存在大的类内(intra-class)和小类间(inter-class)方差。
目前训练策略:
在已有模型上预训练CNN并在小规模数据集上fine-tune。
本文工作:
- 使用hyper-class来增强数据,从网络上搜索hyper-class-labeled的数据,形成多类学习任务。
- 公式化精细识别模型和hyper-class识别模型,通过挖掘二者的关系提升识别率。
增强数据:
- super-class,包括一系列的精细类别。
- factor-type hyper-classes 因子类型。
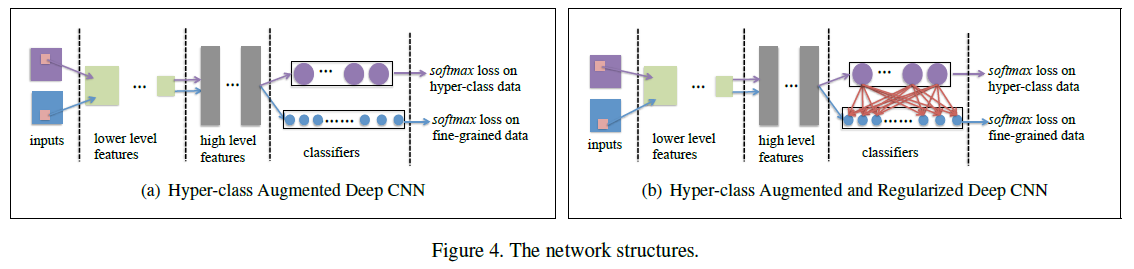
提出超类增强和正则化深度学习(hyper-class augmented and regularized deep learning)。学习框架与神经网络与多任务学习密切相关。这个想法是通过允许他们共享神经网络的相同特征层来联合训练多个相关任务。

超类增强和正则化深度学习
解决第一个难点,用由一些超类标记的大量辅助图像来增强细粒度数据。
第二个难点,提出新的CNN模型。
超类数据增强
- super-class,包括一系列的精细类别。
- factor-type hyper-classes 因子类型。
对于给定的细粒度(fine-grained class)类,图像可能有不同的视角视图,即因子类型超类(factor-type hyper-classes)。这和super-type hyper-class 与 fine-grained classes完全不同。一个fine-grained class只能归属于一个单一的super-type class。比如fine-grained class “吉娃娃”属于super-type class“dog”,并不属于“cat”。然而对于汽车数据,其 fine-grained class可以有不同的视角,因此不必归为同一个单独的hyper-class。从生成的角度来看,可以通过首先生成其视图(hyper-class)然后生成给定的视图来生成汽车图像的fine-grained class。这也是我们下一小节描述的模型的概率基础。由于这种类型的超类可以被认为是图像的隐藏因素,这种类型称为factor-type hyper-class。
**super-type和factor-type 两种hyper-class之间的关键区别是:super-type是由fine-grained类隐含的,而factor-type对于给定的fine-grained类是未知的。**factor-type另一个示例为人脸的不同表情(愉快,愤怒,微笑等),每个人都有不同表情的多张图像。
正则化学习模型
给定细粒度训练图像(fine-grained
training images)和辅助超类标记图像(auxiliary hyper-class labeled images),一个直接的策略是通过共享共同的特征和学习分类器来训练多任务CNN。在多任务学习中,hyper-class类和fine-grained类的标签集是不相交的,我们不用hyper-class标签来标记fine-grained的数据。
Factor-type Hyper-class Regularized Learning
给定图像x,识别结果为y的概率为:
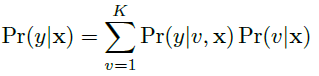
Pr(v|x)是任何 factor-type hyper-class v的概率,并且Pr(y|v,x)指定给定factor-type hyper-class和输入图像x的任何fine-grained class的概率。
使用softmax函数对factor-type hyper-class概率进行建模,h(x)表示x的高层特征,即:
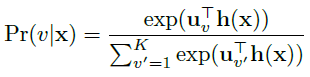
其中
uv
表示hyper-class分类模型的权值,
Pr(y=c|v,x)
如下计算:
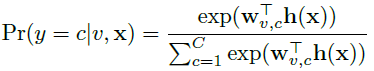
其中
wv,c
表示factor-specific精细分类模型的权值,此时预测公式为:
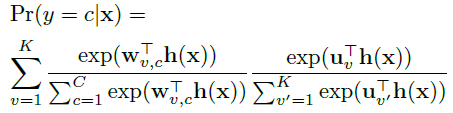
虽然我们的模型在混合模型中有其根,但是值得注意的是,不像大多数以前的混合模型,处理Pr(v|x)作为自由参数,我们将其制定为一个鉴别模型。它是 hyper-class增强图像,允许我们准确地学习{
uv
}。 然后我们可以记录
Dt
中的细粒度识别数据的负对数似然性和
Da
中的数据的hyper-class识别:

为了激励非平凡正则化,我们注意到factor-specific权重
wv,c
应该捕获与对应的factor-type hyper-class分类器
uv
类似的高水平factor-related特征。为此在
wv,c
和
uv
间引入正则化:

为了理解正则化,在我们的汽车识别示例中,原始的fine-grained 数据不能够学习每视角类别分类器
wv,c
,因为没有办法推断视角hyper-class。但现在我们可以在hyper-class增强数据上训练视点分类器
uv
,因此正则化负责将知识传递到每个视角类别分类器,从而帮助模糊fine-grained任务中的类内方差。
引入
w′v,c=wv,c−uv
,则上式化简为:

Pr(y=c|x)
由下式给出:

可以看出,fine-grained 分类器与factor-type hyper-class分类器共享相同的分量
uv
。 因此,它将所提出的模型连接到传统的浅层多任务学习中使用的权重共享。
Super-type hyper-class regularized learning
super-type hyper-class正则化深度学习的唯一区别在于
Pr(y|v,x)
,它可以简单地建模

因为super-type hyper-class
vc
由fine-grained标签c隐含地表示。正则化为:

统一的深度CNN
使用hyper-class增强数据和多任务正则化学习技术,我们达到统一的深CNN框架,如图所示:
其示了优化问题:
















 5193
5193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









