









两个贡献,一是使用hyper-class来增强数据,从网络上搜索hyper-class-labeled的数据,形成多类学习任务。二是公式化精细识别模型和hyper-class识别模型,通过挖掘二者的关系提升识别率。
hyper-class 数据增强
数据增强的方法有裁切,镜像,增加随机噪声。但他们的效果有限,主要是信息类似。作者根据图像处理精细类别信息,还有内在的“属性”信息,而且这样的属性标记的图片(比如不同角度的车)容易获取。
最常见的hyper-class是super-class,包括一系列的精细类别。另一种是factor-class,比如车辆,某种品牌的车辆可能包括多于一种的hyper-class(角度),比如人脸的不同表情。下图显示了两种hyper-class的示意。
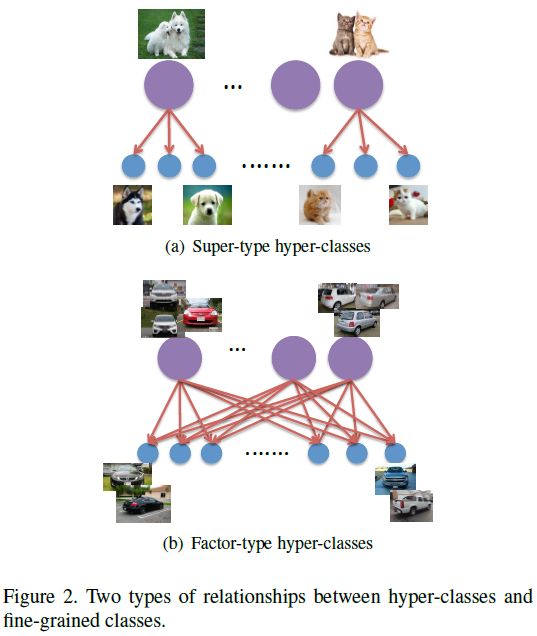
作者使用的车辆角度图片使用Baidu搜索,Google搜索的结果是与检索图片车辆型号相同的图片,如下图所示。

hyper-class规则化学习模型
给定图像x,识别结果为y的概率为:
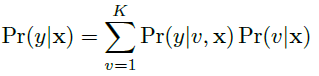
使用softmax函数对factor-type hyper-class概率进行建模,h(x)表示x的高层特征,即,
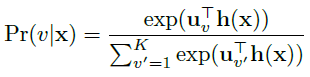
其中
uv
表示hyper-class分类模型的权值,Pr(y=c|v,x)如下计算:
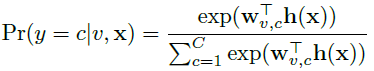
其中
wv,c
表示factor-specific精细分类模型的权值,此时预测公式为:
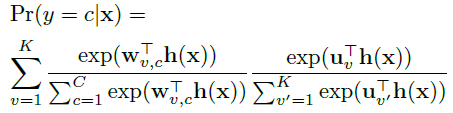
factor-specific的权值 wv,c 应该获取factor-type hyper-class分类器 uv 对应的相似高层factor相关信息。
将
wv,c
和
uv
如下规则化:
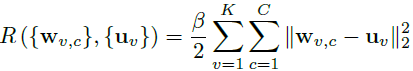
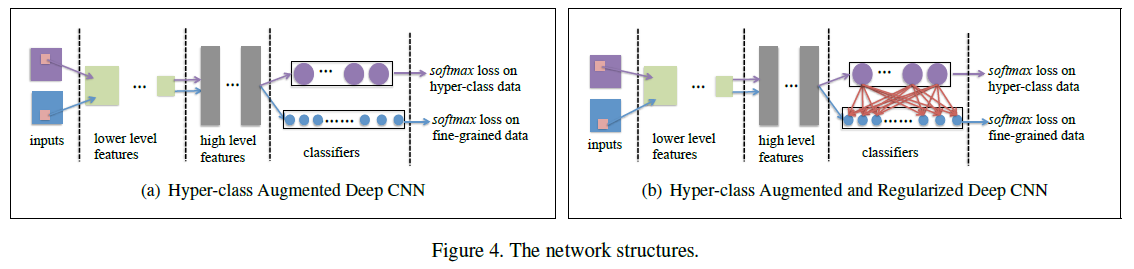
模型结构如下图(b)所示:















 1454
1454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









