






特点:trimap-free、人像matte,速度快
因为目标定义明确,才能trimap-free。
本质还是图片matte
结构
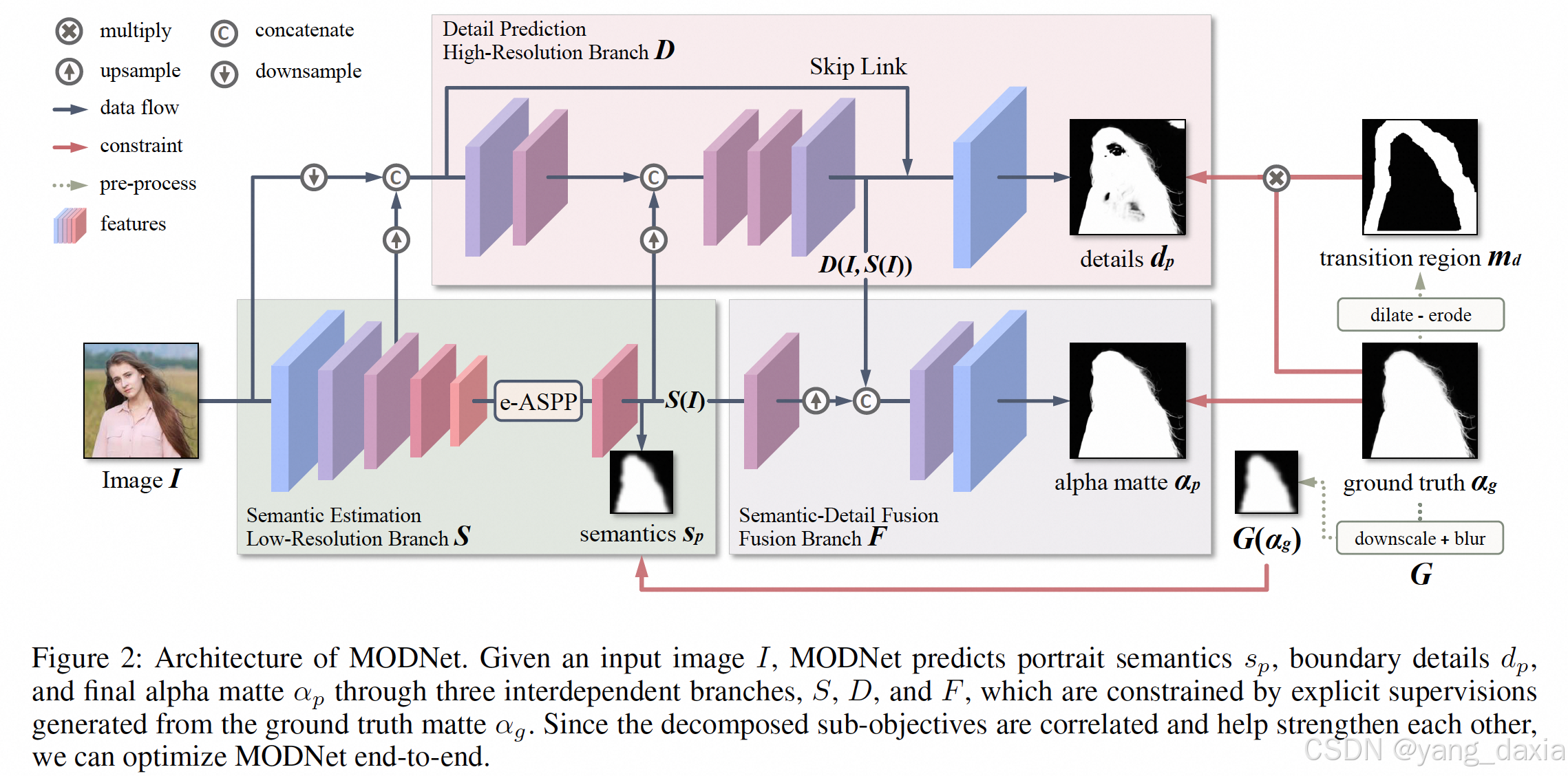
卷积神经网络,分为3个模块,小分辨率目标分割、细节预测、alpha预测
所以loss也是3个加权
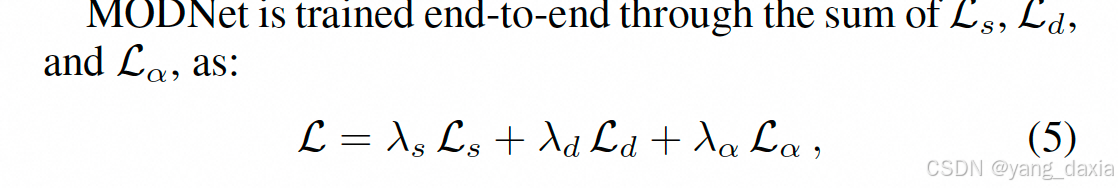
分割gt通过alpha下采样+blur获取,细节只关注边界loss。
domain适应
通过在其他数据上自监督的训练。加了两个一致性loss。让模型的3个输出彼此之间的边界信息对齐。(因为前景的人是固定的,换了domain,也就是背景,一般就是边界学习的不太好,所以要保证边界对齐),细节loss加了一个与原模型做对齐。

视频后处理
one-frame-delay。
如果前一帧与后一帧相似,与本帧不相似,则说明本帧闪烁,取前后帧的均值作为本帧的结果。

局限
- trimap-free的方法,效果不错,但是加入trimap信息,还是可以大幅提升modnet的效果
- 本方法未引入时空信息,所以对于运动比较快的,表现不好。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











