







caffe在window下的安装具体的可以参考如下博客:【caffe-Windows】caffe+VS2013+Windows无GPU快速配置教程
我是安装微软的caffe库,其为caffe-master。
这个使用有几个注意点:
1、我的VS2013只能正确编译release下X64工程,其它模式下的编译出错,
编译好的exe文件运行不了,提示缺少MSVCR120D.dll、MSVCP120D.dll等文件,其能在64为系统C:\Windows\SysWOW64下找到,
于是把其考到exe文件下,虽然不提示缺少dll文件,但是有出现"无法运行的应用程序",当时以为是工程配置有问题,
解决方法:后来360软件自动跳出一个提示框说系统缺少重要dll文件,需要修复,然后我就点击了确定,神奇的是release下的exe可以运行了。具体原因未知,(已解决)原因是:
下载的MSVCR120D.dll、MSVCP120D.dll与系统位数版本不相符,加有d的是工程在debug下需要的dll,其会导致
exe运行时0xc000007b错误,具体解决方法参考博客:http://blog.csdn.net/yangdashi888/article/details/72683290
2、如何在window下运行linux的shell脚本,即sh结尾的文件。
其中我们要安装 Git bash 软件,以后再window下只有双击sh文件就可以运行,及caffe里的examples里的工程我们都可以运行。但是git bash不具有linux的很多指令,例如make、wget等,即使在windwos上安装也使用不了。只当作运行exe程序即可。
3、在caffe master编译好的build文件下的caffe-master\Build\x64\Release路径下会生产一些dll文件,有人可能会配置环境变量,以后就可以直接把exe考到任何地方了。
这是很危险的,这可能会导致一些exe文件可以正常运行,有些不可以。其中像caffe.exe、convert_imageset.exe等可能因为出错而闪退,(无法看清其错误信息)。
后来把所以的dll文件考到相应的文件夹下,exe就工作正常了。使用bat脚本来运行caffe.exe则会如下:

4、其中,关于生成levelldb或者lmdb格式的数据集方法,
a、一种就是直接使用caffe自带的create_imagenet.sh文件,其相关数据配置如下:
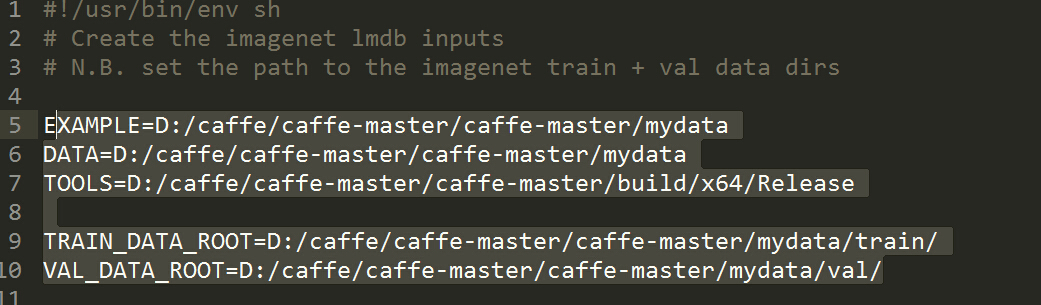
example设定为数据集的路径 data也设定为数据集路径 tools为convert_imageset.exe的路径
TRAIN_DATA_ROOT训练数据集路径 VAL_DATA_ROOT测试数据集路径 -----记得起后面要带‘/’。要不exe会
提示不能发现图片文件。
b、另一种是使用window的脚本bat文件,很好用.先新建个txt文件,后把其后缀改为bat即可。其里面的配置为:
SET GLOG_logtostderr=1
f:
cd F:\xuanliancaffe\dierci
convert_imageset.exe train/ train.txt mytrainlmdb 0
pause 其前面的路径定位跟linux系统指令很像,其中convert_imageset.exe为当前路径下的应用程序,train/为训练数据路径,其中train.txt 为当前路径下的图像名字文件。其中mytrainlmdb当前路径下的即将新建的文件名,用于存放
训练数据,其默认是lmdb格式数据,如果要生成levelldb则需要改为:(注意:这个文件名重新运行的时候要提前删除,否则exe会报错,一闪而过,根本看不出什么错误,这是个坑)
SET GLOG_logtostderr=1
cd F:\xuanliancaffe\dierci
convert_imageset.exe --backend=leveldb train/ train.txt mytrainlevelldb2 0
pause
5、网络参数的解释(核心部分):
其中solver.prototxt文件配置,其是训练整个网络时的核心,为:
net: "models/bvlc_reference_caffenet/train_val.prototxt"
test_iter: 100
test_interval: 1000
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 100000
display: 20
max_iter: 450000
momentum: 0.9
weight_decay: 0.0005
snapshot: 10000
snapshot_prefix: "models/bvlc_reference_caffenet/caffenet_train"
solver_mode: GPU 在caffe中的关于一次迭代itterration指的是运行完一个batch,跟c++网络里的说的enpoch不同。这里主要的是test_iter、学习率的变化(刚开始学习率大的话会来回震荡,一般越后期学习率要越小)、momentum加速收敛、weight_decay权值衰减。snapshot设置的越小越好。
首先简短的介绍各个超参数设置规则:
1、test_iter:其要结合验证样本val的数量设置,其为test_iter*batch_size=测试样本数,过小可能会造成只有一类样本进行测试,如下:

如果test_iter*batch_size少于上面的个数,则一直是第0类样本进行测试,这个需要自己使用excel或者一些文本打乱小工具进行打乱测试集,否者也会造成准确率时大时小。
2、learn_rate的变化规律,对于少样本少种类的训练学习率最好设置在0.001一下,如果设置成0.01则容易造成震荡,即accuracy时高时低,相差也大,如0.4然后0.1。
而且越后期学习率应当越小,这就需要上面的四个参数一起配合使用,详情见下面介绍。
3、momentum加速收敛:
其理论大概为如果这次的权值变化趋势跟上次的一样则加快权值变化,其只对负梯度起作用,momentum是梯度下降法中一种常用的加速技术。叫做冲量梯度下降法。对于一般的SGD,其表达式为
x←x−α∗dx
,x沿负梯度方向下降。而带momentum项的SGD则写生如下形式:
v=β∗v−a∗dxx←x+v
其中β 即momentum系数,通俗的理解上面式子就是,如果上一次的momentum(即v)与这一次的负梯度方向是相同的,那这次下降的幅度就会加大,所以这样做能够达到加速收敛的过程。
4、weight_decay权值衰减,值越大初始的loss也越大,其与momentum的关系请参考博客后面的内容。
在机器学习中,常常会出现overfitting,网络权值越大往往overfitting的程度越高,因此,为了避免出现overfitting,会给误差函数添加一个惩罚项,常用的惩罚项是所有权重的平方乘以一个衰减常量之和。
![\begin{align}J(W,b)&= \left[ \frac{1}{m} \sum_{i=1}^m J(W,b;x^{(i)},y^{(i)}) \right] + \frac{\lambda}{2} \sum_{l=1}^{n_l-1} \; \sum_{i=1}^{s_l} \; \sum_{j=1}^{s_{l+1}} \left( W^{(l)}_{ji} \right)^2 \\&= \left[ \frac{1}{m} \sum_{i=1}^m \left( \frac{1}{2} \left\| h_{W,b}(x^{(i)}) - y^{(i)} \right\|^2 \right) \right] + \frac{\lambda}{2} \sum_{l=1}^{n_l-1} \; \sum_{i=1}^{s_l} \; \sum_{j=1}^{s_{l+1}} \left( W^{(l)}_{ji} \right)^2\end{align}](http://ufldl.stanford.edu/wiki/images/math/4/5/3/4539f5f00edca977011089b902670513.png)
原理:通过增大loss,反向传播时大权重减少的值比较多,从而达到惩罚。
右边项即用来惩罚大权值。权值衰减惩罚项使得权值收敛到较小的绝对值,而惩罚大的权值。从而避免overfitting的出现。

当weight_decay设为0.05时,则其初始loss也7.2、7.4.
其中
test_iter:
在测试的时候,需要迭代的次数,即test_iter* batchsize(TEST阶段)=测试集的大小,TEST阶段batchsize可以在prototx文件里设置,这里的batchsize是测试集的,其实当train迭代达到test_interval值时执行的,如下:
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
data_param {
source: "examples/imagenet/ilsvrc12_val_lmdb"
batch_size: 50 ##这里
backend: LMDB
}
} test_interval:
interval该参数表示:训练的时候,每迭代1000次(上面设置的是1000)就进行一次测试。caffe在训练的过程是边训练边测试的。训练过程中每1000次迭代(也就是32000个训练样本参与了计算,TRAIN阶段batchsize为32),计算一次测试误差。这样可以认为在一个epoch里,训练集中的所有样本都遍历一遍,但测试集的所有样本至少要遍历一次,至于具体要多少次,也许不是整数次,这就要看代码,大致了解下这个过程就可以了。这个跟max_iter有关,训练的时候要记得根据数据大小、bitch_size大小来进行计算值。
base_lr: 0.01lr_policy: "inv"
gamma: 0.0001
power: 0.75display:这是显示训练网络相关的参数值,其显示内容如下:

这四行可以放在一起理解,用于学习率的设置。只要是梯度下降法来求解优化,都会有一个学习率,也叫步长。base_lr用于设置基础学习率,在迭代的过程中,可以对基础学习率进行调整。怎么样进行调整,就是调整的策略,由lr_policy来设置。
http://stackoverflow.com/questions/30033096/what-is-lr-policy-in-caffe 详细的说明lr_policy的参数变化 有图
lr_policy可以设置为下面这些值,相应的学习率的计算为:
-
- - fixed: 保持base_lr不变.
- - step: 如果设置为step,则还需要设置一个stepsize, 返回 base_lr * gamma ^ (floor(iter / stepsize)),其中iter表示当前的迭代次数
- - exp: 返回base_lr * gamma ^ iter, iter为当前迭代次数
- - inv: 如果设置为inv,还需要设置一个power, 返回base_lr * (1 + gamma * iter) ^ (- power)
- - multistep: 如果设置为multistep,则还需要设置一个stepvalue。这个参数和step很相似,step是均匀等间隔变化,而multistep则是根据 stepvalue值变化
- - poly: 学习率进行多项式误差, 返回 base_lr (1 - iter/max_iter) ^ (power)
- - sigmoid: 学习率进行sigmod衰减,返回 base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
其中学习率变化图标博客:Keras中poly学习策略的实现
其中decay的学习率策略是:
LearningRate = LearningRate * 1/(1 + decay * iteration)
poly学习率策略:
LearningRate = InitialLearningRate*(1 - iter/max_iter) ^ (power) 
multistep示例:

base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "multistep"
gamma: 0.9
stepvalue: 5000
stepvalue: 7000
stepvalue: 8000
stepvalue: 9000
stepvalue: 9500
接下来的参数:
momentum :0.9上一次梯度更新的权重,具体可参看下一篇文章。
type: SGD优化算法选择。这一行可以省掉,因为默认值就是SGD。总共有六种方法可选择,在本文的开头已介绍。
weight_decay: 0.0005权重衰减项,防止过拟合的一个参数。
display: 100每训练100次,在屏幕上显示一次。如果设置为0,则不显示。
max_iter: 20000最大迭代次数。这个数设置太小,会导致没有收敛,精确度很低。设置太大,会导致震荡,浪费时间。
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"快照。将训练出来的model和solver状态进行保存,snapshot用于设置训练多少次后进行保存,默认为0,不保存。snapshot_prefix设置保存路径。
还可以设置snapshot_diff,是否保存梯度值,默认为false,不保存。
也可以设置snapshot_format,保存的类型。有两种选择:HDF5 和BINARYPROTO ,默认为BINARYPROTO
solver_mode: CPU设置运行模式。默认为GPU,如果你没有GPU,则需要改成CPU,否则会出错。
下面时自己的solver.prototxt文件的设置:
net: "models/bvlc_reference_caffenet/train_val.prototxt" #设置网络模型,文件的路径要从caffe的根目录开始
test_iter: 1000 #与test layer中的batch_size结合起来理解,假设样本总数为10000,一次性执行全部数据效率低,因此将测试数据分成几个批次来执行,每个批次的数量就是batch_size。假设batch_size为100,则需要迭代100次才能将10000个数据全部执行完,因此test_iter设置为100.
test_interval: 1000 #测试间隔,也就是每训练test_interval次,才进行一次测试
base_lr: 0.01 #0.01基础学习率,因为数据量小,0.01就会下降太快了,因此改成0.001
lr_policy: "step" #学习率变化
gamma: 0.1 #学习率变化的比率
#base_lr\lr_policy\gamma\power四个可以一起理解,用于学习率的设置。只要是梯度下降法来求解优化,都会有一个学习率,也叫步长。base_lr用于设置基础学习率,在迭代过程中,可以对基础学习率进行调整。怎样进行调整,也就是调整的策略,由lr_poliy来设置。
stepsize: 100000 #每stepsize次迭代减少学习率
display: 20 #每训练display次在屏幕上显示一次,其显示的是网络的学习率大小,和训练网络当下的损失值loss
max_iter: 450000 #最大迭代次数,这个数设置太小,会导致没有收敛,精确度很低。设置太大,会导致震荡,浪费时间
momentum: 0.9 #上一次梯度更新的权重
weight_decay: 0.0005 #权重衰减项,防止过拟合的一个参数
snapshot: 10000
snapshot_prefix: "models/bvlc_reference_caffenet/caffenet_train" #snapshot\snapshot_prefix 快照。将训练出来的model和solver状态进行保存,snapshot用于设置训练多少次后进行保存,默认为0,不保存。snapshot_prefix 设置保存路径。也可以用snapshot_format来保存类型,有两种选择:HDF5 和 BINARYPROTO ,默认类型为后者
solver_mode: CPU #设置运行模式,默认为GPU
#GPU模式
#solver_mode: GPU
#device_id: 0 #在cmdcaffe接口下,GPU序号从0开始,如果有一个GPU,则device_id:0
2.其他的一些补充参数说明:
train_val.prototxt
layer { # 数据层
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN # 表明这是在训练阶段才包括进去
}
transform_param { # 对数据进行预处理
mirror: true # 是否做镜像
crop_size: 227
# 减去均值文件
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
data_param { # 设定数据的来源
source: "examples/imagenet/ilsvrc12_train_lmdb"
batch_size: 256
backend: LMDB
}
}layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST # 测试阶段
}
transform_param {
mirror: false # 是否做镜像
crop_size: 227
# 减去均值文件
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
data_param {
source: "examples/imagenet/ilsvrc12_val_lmdb"
batch_size: 50
backend: LMDB
}
}-
lr_mult
学习率,但是最终的学习率需要乘以 solver.prototxt 配置文件中的 base_lr .如果有两个 lr_mult, 则第一个表示 weight 的学习率,第二个表示 bias 的学习率
一般 bias 的学习率是 weight 学习率的2倍’ -
其最后的权重更新大概是这样的:
-
decay_mult:权值惩罚项,需要乘以weight_decay,wi = wi -(base_lr * lr_mult) *dwi - (weight_dacay * decay_mult) * wi (dwi是误差关于wi的偏导数)
其中dwi是由损失函数反向求导得到的,如果在等式右边的wi前加上一个m则代表的是技术是momentum,这个是按正确的方向加快梯度衰减。
-
decay_mult
权值衰减,为了避免模型的over-fitting,需要对cost function加入规范项。num_output
-
卷积核(filter)的个数
-
kernel_size
卷积核的大小。如果卷积核的长和宽不等,需要用 kernel_h 和 kernel_w 分别设定
-
stride
卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。 -
pad
扩充边缘,默认为0,不扩充。扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。
也可以通过pad_h和pad_w来分别设定。 -
weight_filler
权值初始化。 默认为“constant”,值全为0.
很多时候我们用”xavier”算法来进行初始化,也可以设置为”gaussian”weight_filler { type: "gaussian" std: 0.01 }- bias_filler
偏置项的初始化。一般设置为”constant”, 值全为0。
bias_filler { type: "constant" value: 0 }-
bias_term
是否开启偏置项,默认为true, 开启
-
group
分组,默认为1组。如果大于1,我们限制卷积的连接操作在一个子集内。
卷积分组可以减少网络的参数,至于是否还有其他的作用就不清楚了。每个input是需要和每一个kernel都进行连接的,但是由于分组的原因其只是与部分的kernel进行连接的
如: 我们根据图像的通道来分组,那么第i个输出分组只能与第i个输入分组进行连接。 -
pool
池化方法,默认为MAX。目前可用的方法有 MAX, AVE, 或 STOCHASTIC -
dropout_ratio
-
drop_ratio:丢弃数据的概率,和dropout层相关,详解:http://blog.csdn.net/u013989576/article/details/70174411















 101
101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









