







 本文解释了注意力机制如何根据输入空间的相似性赋予权重,用于预测值计算。重点讨论了QKV向量模型、点积注意力模型以及Transformer中注意力机制的关键结构,强调了特征提取和自注意力的概念。
本文解释了注意力机制如何根据输入空间的相似性赋予权重,用于预测值计算。重点讨论了QKV向量模型、点积注意力模型以及Transformer中注意力机制的关键结构,强调了特征提取和自注意力的概念。
此处为b站学习视频记录
https://www.bilibili.com/video/BV1dt4y1J7ov/?share_source=copy_web&vd_source=c675206b339487e9755eec554de241a9


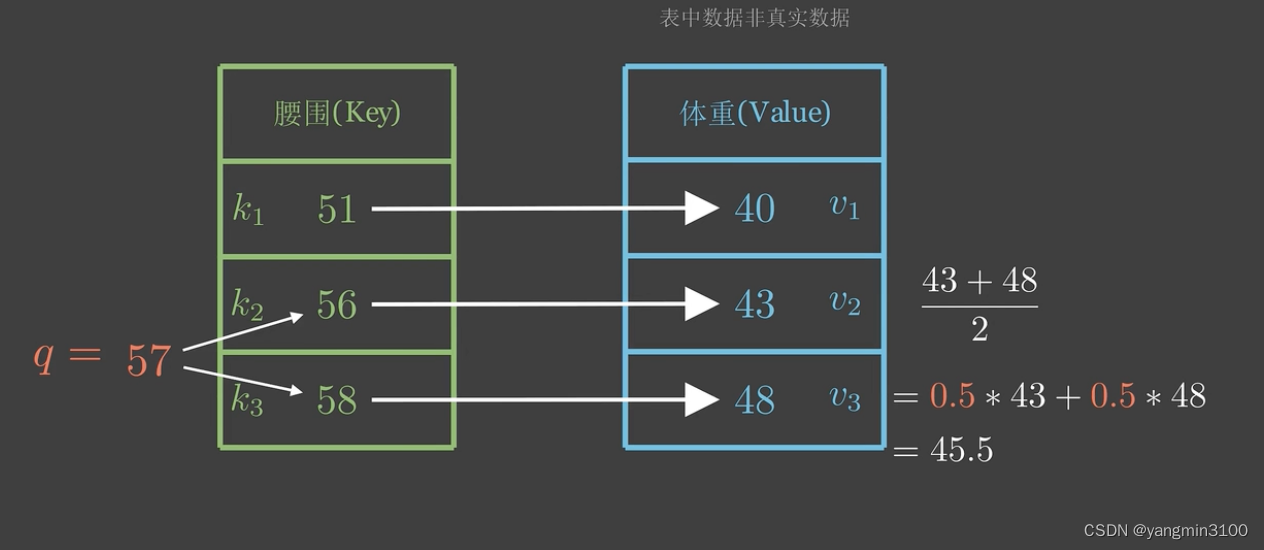
现在给出一个人的腰围为57, 想要预测他的体重,自然的,因为体重57在56和58之间,所以我们推断其体重在43~48之间

但是我们还需要定量计算体重预测值,怎么办呢?我们可以根据57和56,57和58的相似程度来给56对应的体重43和58对应的体重48赋予权重,再求和得到预测值。由于57到56、58的距离一样,所以一种方法是取它们对应的体重的平均值。

因为57距离56、58最近,我们自然会非常“注意”他们,所以我们分给他们的注意力权重各为0.5。
现在我们引入QKV,并将注意力范围扩展到整个数据集
q代表一个新的未见样本的输入,我们需要得到这个新的未见样本的输出
也就是说,我们需要查询q(query)对应的value,我们怎么做呢?我们只能用现有的已经见到的这些样本来做。
已经见到的样本叫做训练集,也就是说,我们需要通过训练集来查询query对应的value。
怎么查询呢?或者说我们怎么计算呢?那就是借助训练集,借助已有的键值对,借助已有的K和V
一个自然的想法就是:我观察我的新样本q和已知样本K,K和q越相似,其对应的value就越像q对应的value。
因此我们可以计算q和现有的所有的V之间的相似度,并且赋予那些与q相似的k对应的value高的权重,最终将赋权后的所有的k的value求和,就可以得到q所对应的value的预测值。

α
\alpha
α是任意能刻画相关性的函数,但需要归一化,我们以高丝核函数所为相似性度量函数,并将其通过softmax做归一化:

相应的,预测函数变为:
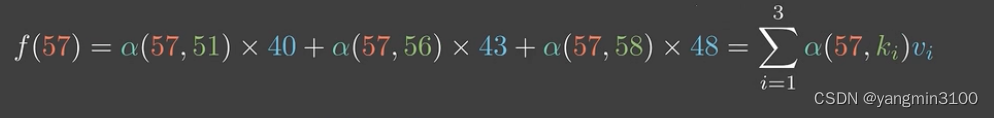
通过这种方式,我们就可以得到体重估计值,这也就是注意力机制。其实就是根据预测样本和训练集样本在输入空间的相似性得到权重,对训练样本的输出值进行加权得到预测值的过程。
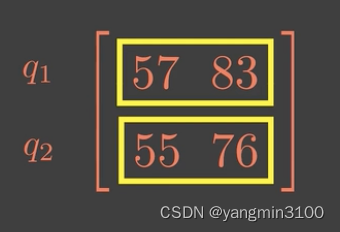
现在我们来考虑QKV是多维向量时的情况:
注意力可以是以下几种:(参考李沐老师动手学深度学习课程注意力讲解)
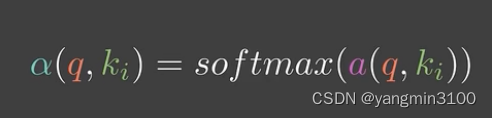

我们以点积模型为例:
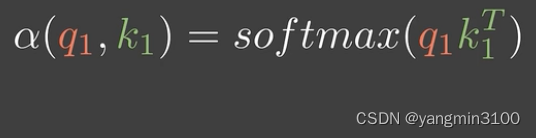
由此得到预测函数为:
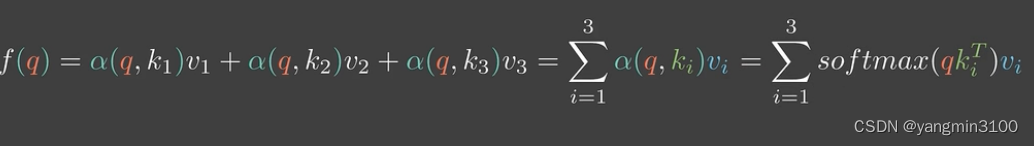
为了方便,我们用矩阵来表示:
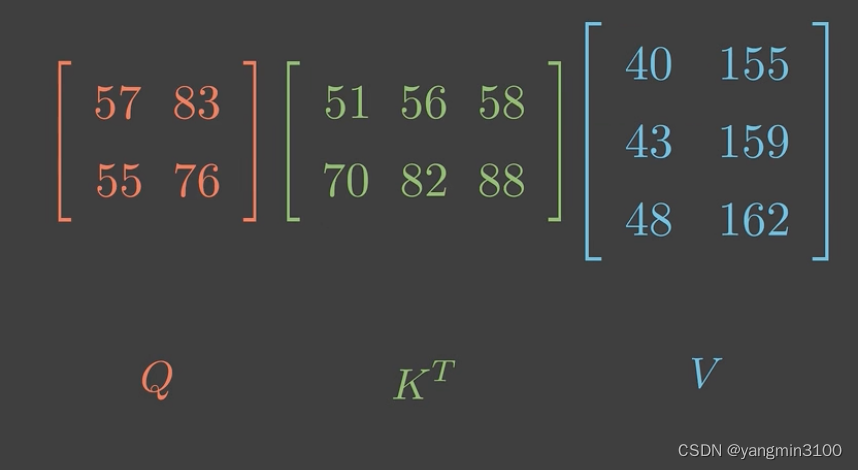
最重要的,从这里我们可以看出,K作为与Q与相同特征数量、与V具有相同样本个数的矩阵,K的行数一定等于Q的列数,K的列数一定等于V的行数。这一点非常重要,对于理解多头注意力的代码非常关键。我们必须弄清楚数据流经模型时每一步的形状,才能对数据的变换过程了如指掌。

为了缓解梯度消失问题,我们还会在归一化之前处以一个特征维度,得到:
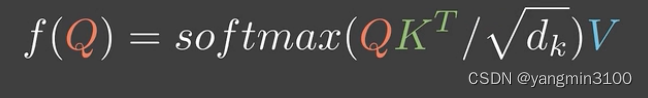
我们把这一系列操作形象的称为:缩放点击注意力模型(scaled dot-product attention)
如果QKV是同一个矩阵会发生什么?那就是 自注意力
用X表示,则可以得到下面的式子:
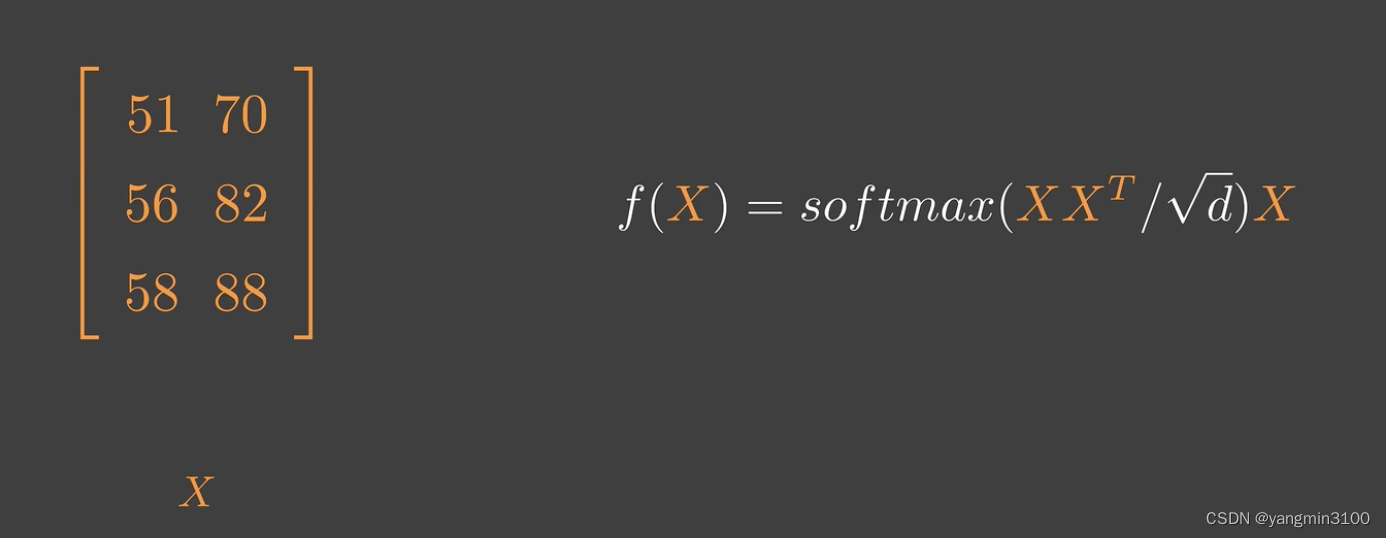
但在实际运用中可能会对X先做不同的线性变换再输入,这里还有一个好处就是,通过线性变换,我们可以控制做注意力时的维度,人为的控制模型复杂度,比如Transformer。

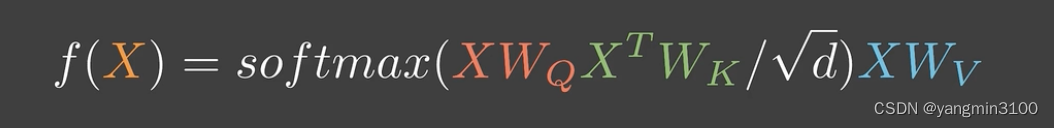
这里的x^TW_k 应该是(XW_k)^T 视频作者笔误了。
一点思考
从沐神注意力机制的讲解我们就可以知道,注意力机制出现已久,是先贤们探索的结果。他一开始是一种预测算法,是根据预测样本和训练集样本在输入空间的相似性得到权重,对训练样本的输出值进行加权得到预测值的过程。
有趣的时,预测算法也可以看作一个特征提取器,比如mlp,本质就是我们将输入映射到的输出空间不同,如果映射到一维实数空间,我们就是在做回归,如果映射到离散的空间,可以认为我们就是在做分类。如果映射到多维空间,那就可以认为我们在做特征提取。
在这方面,cnn是在空间上做特征提取,rnn是在时间上做特征提取。就是都是一个encoder的过程,encoder?那就是transformer的特征提取器?那transformer的特征提取器由什么组成?那不就是注意力机制吗?
所以把注意力机制看透,他就是在做特征提取,而恰好,transformer看中了这个特征提取器组成了他的encoder,当然 decoder是在做解码,那解码和编码本就是相反的过程,所以特征提取器也可以做解码。
由此,transformer最本质的注意力机制,我想我不在那么模糊了。


















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











