







《Towards Universal Sequence Representation Learning for Recommender Systems》 (KDD‘22)
序列推荐是根据用户点击过的item序列,学习出一个序列表征,然后根据表征预测下一个item,建模表征的模型有 RNN、CNN、GNN、Transformer、MLP等。
现有方法依赖于显式的商品ID建模,存在迁移性差和冷启动的问题(即使各个推荐场景的数据格式是完全相同的)。文章受预训练语言模型的启发,希望能设计一种针对序列推荐的序列表示学习的方法。
核心思想是利用:与商品相关的文本(如商品描述、标题、品牌等)来学习可跨域迁移的商品表示和序列表示。(模型可以在同一APP新的场景上快速适配、新APP上快速适配)。
核心技术主要靠MoE和动态路由。
解决的两个问题:1、需要将文本的语义空间适配到推荐任务中。2、跨domain的数据可能会冲突,导致跷跷板现象。
UnisRec模型
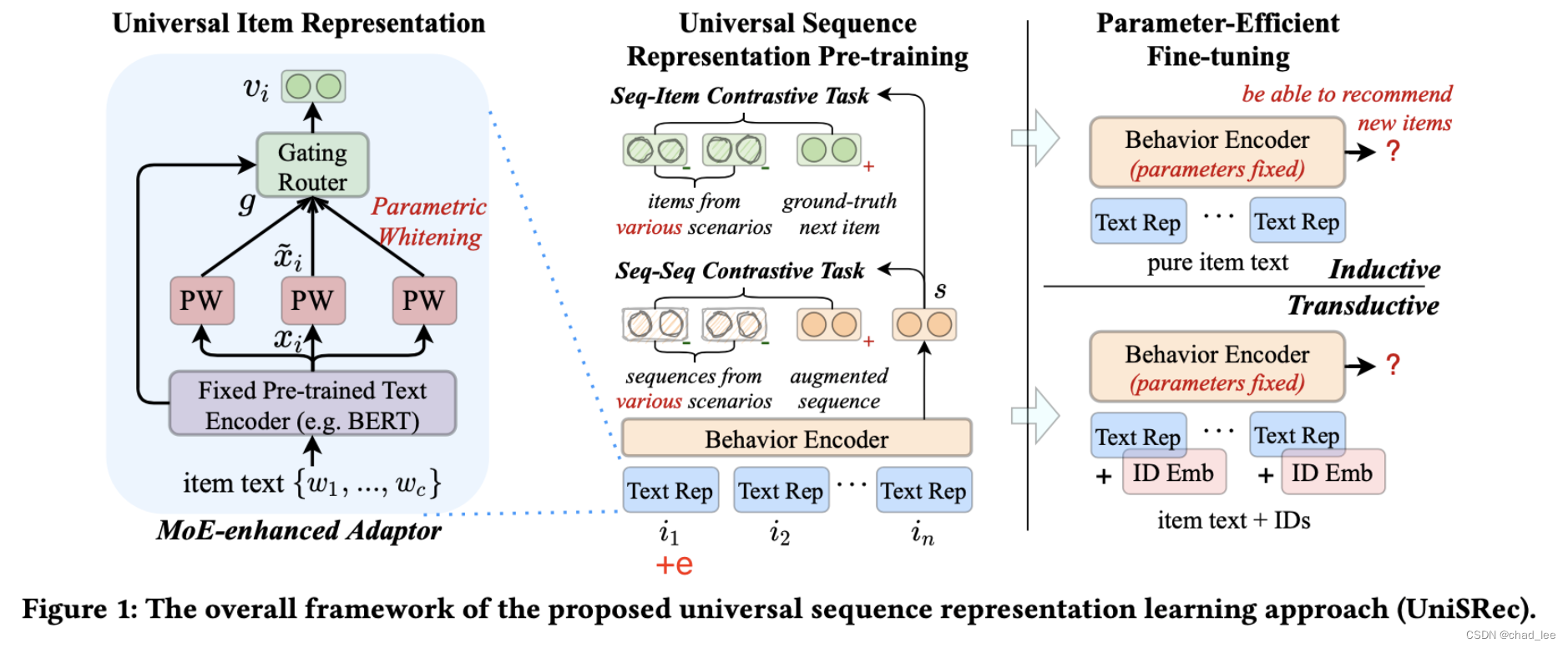
输入
用户点击过的item按照时间顺序排列 s = { i 1 , i 2 , … , i n } s=\left\{i_{1}, i_{2}, \ldots, i_{n}\right\} s={ i1,i2,…,in},其中每个商品 i 都对应着一个id和一段描述性文本(如商品描述、标题或品牌)。商品i的描述文本可以形式化为 t i = { w 1 , w 2 , … , w c } t_{i}=\left\{w_{1}, w_{2}, \ldots, w_{c}\right\} ti={ w1,w2,…,wc},其中 w j w_j wj 是共享的词表, c表示商品文本的最长长度(截断)。
- 这里的商品序列是用户匿名的,不记录user id
- 一个用户在多个平台、多个领域都会产生交互序列,每个domain的序列单独记录,混合在一起作为序列数据
- 商品ID不会作为UniSRec的输入,因为商品ID跨domain是没有意义的。
- 因此UniSRec的目的能够有 建模通用序列表征 的能力,这样的话就可以实现利用 微博 的序列数据在 淘宝 推荐
通用商品文本表示
基于预训练语言模型的商品文本编码
将商品文本输入BERT,用 [CLS] 作为序列表征:
x i = BERT ( [ [ C L S ] ; w 1 , … , w c ] ) \boldsymbol{x}_{i}=\operatorname{BERT}\left(\left[[\mathrm{CLS}] ; w_{1}, \ldots, w_{c}\right]\right) xi=BERT([[CLS];w1,…,wc])
x i ∈ R d W \boldsymbol{x}_{i} \in \mathbb{R}^{d_{W}} xi∈RdW 是 [CLS]的输出。尽管已经
Semantic Transformation via Parametric Whitening
在NLP领域有很多研究表明BERT生成的表示空间是非平滑且各向异性的,具体表现就是BERT输出的向量在计算无监督相似度的时候效果很差,一个改进措施就是把BERT的输出向量变成高斯分布,即让所有的向量转换为均值为0且协方差为单位矩阵的向量。
(也比较好理解,在BERT的预训练中完全没有显式的pairwise的优化Alignment和Uniformity)
这篇文章没有用预先算出来的均值和方差来做白化,为了在未知领域上更好地泛化,在将b和W置为可学习参数:
x ~ i = ( x i − b ) ⋅ W 1 \widetilde{\boldsymbol{x}}_{i}=\left(\boldsymbol{x}_{i}-\boldsymbol{b}\right) \cdot \boldsymbol{W}_{1}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 633
633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









