






大模型常见推理框架:Transformers、Llama.cpp、Llamafile、Ollama、vLLM、TGI(Text Generation Inference)、DeepSpeed。vLLM,deepspeed是重点
1.Transformers
由HuggingFace推出的Transformers,是一个强大的Python库,专为简化本地运行LLM而设计。其优势在于自动模型下载、提供丰富的代码片段,以及非常适合实验和学习。
2.Llama.cpp
基于C++的推理引擎,专为Apple Silicon打造,能够运行Meta的Llama2模型。它在GPU和CPU上的推理性能均得到优化。Llama.cpp的优点在于其高性能,支持在适度的硬件上运行大型模型(如Llama 7B),并提供绑定,允许您使用其他语言构建AI应用程序。其缺点是模型支持有限,且需要构建工具。
3.Llamafile
Mozilla开发的C++工具,基于llama.cpp库,为开发人员提供了创建、加载和运行LLM模型所需的各种功能。它简化了与LLM的交互,使开发人员能够轻松实现各种复杂的应用场景。Llamafile的优点在于其速度与Llama.cpp相当,并且可以构建一个嵌入模型的单个可执行文件。然而,由于项目仍处于早期阶段,不是所有模型都受支持,只限于Llama.cpp支持的模型。
4.ollama
作为Llama.cpp和Llamafile的用户友好替代品,Ollama提供了一个可执行文件,可在您的机器上安装一个服务。安装完成后,只需简单地在终端中运行即可。其优点在于易于安装和使用,支持llama和vicuña模型,并且运行速度极快。
5.vLLM
vLLM是一个高吞吐量、内存高效的大型语言模型(LLMs)推理和服务引擎。
目标是为所有人提供简便、快捷、经济的LLM服务。vLLM的优点包括高效的服务吞吐量、支持多种模型以及内存高效。然而,为了确保其性能,用户需要确保设备具备GPU、CUDA或RoCm。
基于操作系统中经典的虚拟(Virtual)内存和分页(Page)技术,提出了一个新的注意力算法 PagedAttention,并打造了一个LLM服务系统——vLLM。
vLLM通过借鉴虚拟(Virtual)内存的原理,采用固定大小的块和动态映射的方式,有效地管理了内存,减少了内存浪费。从原理实现来看,我个人觉得 其命名中的 v 即这里的虚拟(Virtual)含义。
对于模型的批量推理/并行推理,需要解决如下的几个问题:
对Early-finished Requests的处理:不同请求所生成的文本长度不一致,可能差别很大,并且不易预测。如果没有一个将已生成结束的请求从Batch中移除并提前返回结果的机制,那么只能等一个Batch内所有请求都完成生成后才返回生成结果,导致生成短文本的用户则需要多“陪跑”数秒到数十秒才能得到结果,这对于服务响应时间是不利的;
对Late-joining Requests的处理:完整生成一段文本需要长达数秒或数十秒的时间,是漫长的。所以如果没有一个将新请求插入到推理Batch的机制,那么只能像CV业务那样,等前面的请求都完成推理了才进行后续请求的推理。这会导致请求需要在系统中长时间等待排队,表现为服务响应时间过长甚至不可接受;
Batching an arbitrary set of requests:每个请求对应的QKV Tensor的Length维度各不相同,在批量计算Attention时,需要处理此问题。诚然Padding+Masking的方法可以解决,但严重浪费算力和显存,对于算力和显存均有限的推理GPU是不利的。
在这个过程中,vLLM通过PagedAttention技术和“先来先服务(FCFS),后来先抢占,gpu不够就先swap到cpu上”的调度策略(Scheduler),在1个推理阶段处理尽可能多的请求,解决高并发场景下的推理吞吐问题。这就是整个vLLM运作的核心思想。
vLLM推理框架的关键点:
- 分区(Partitioning):vLLM推理框架通过将大型语言模型分解为多个部分来实现推理加速。这些部分可以是在不同设备上执行的,例如在CPU、GPU或TPU上。通过这种方式,可以并行处理模型的不同部分,从而加快推理速度。
- 虚拟内存(Virtual Memory):vLLM推理框架利用虚拟内存技术来管理模型在内存中的数据。通过将模型所需的数据加载到虚拟内存中,可以减少实际内存的使用,并提高数据访问的速度。
- 量化(Quantization):vLLM推理框架通过将模型参数和输入数据从浮点数转换为低精度表示(如8位整数或4位整数)来实现推理加速。量化可以减少模型的参数量和计算量,从而加快推理速度。
- 蒸馏(Distillation):vLLM推理框架还可以通过蒸馏技术来减少模型的大小和计算复杂度。蒸馏是一种将大型教师模型(teacher model)的知识传递给小型学生模型(student model)的技术。学生模型具有较少的参数,但在性能上与教师模型相似。通过蒸馏,vLLM推理框架可以加速模型的推理速度。
- 混合精度(Mixed Precision):vLLM推理框架还可以使用混合精度技术,将模型中的某些部分保持为浮点数,而其他部分则使用低精度表示。这种方法可以在不牺牲太多性能的情况下,提高推理速度。
- 并行计算(Parallel Computing):vLLM推理框架可以利用并行计算技术来加速模型的推理。通过在多个处理器核心或多台设备上同时执行模型的一部分,可以显著提高推理速度。
6.TGI(Text Generation Inference)
由HuggingFace推出的大模型推理部署框架,支持主流大模型和量化方案。TGI结合Rust和Python,旨在实现服务效率和业务灵活性的平衡。它具备许多特性,如简单的启动LLM、快速响应和高效的推理等。通过TGI,用户可以轻松地在本地部署和运行大型语言模型,满足各种业务需求。经过优化处理的TGI和Transformer推理代码在性能上存在差异,这些差异体现在多个层面:
并行计算能力:TGI与Transformer均支持并行计算,但TGI更进一步,通过Rust与Python的联合运用,实现了服务效率与业务灵活性的完美平衡。这使得TGI在处理大型语言模型时,能够更高效地运用计算资源,显著提升推理效率。
创新优化策略:TGI采纳了一系列先进的优化技术,如Flash Attention、Paged Attention等,这些技术极大地提升了推理的效率和性能。而传统的Transformer模型可能未能融入这些创新优化。
模型部署支持:TGI支持GPTQ模型服务的部署,使我们能在单卡上运行启用continuous batching功能的更大规模模型。传统的Transformer模型则可能缺乏此类支持。
尽管TGI在某些方面优于传统Transformer推理,但并不意味着应完全放弃Transformer推理。在特定场景下,如任务或数据与TGI优化策略不符,使用传统Transformer推理可能更合适。当前测试表明,TGI的推理速度暂时逊于vLLM。TGI推理支持以容器化方式运行,为用户提供了更为灵活和高效的部署选项。
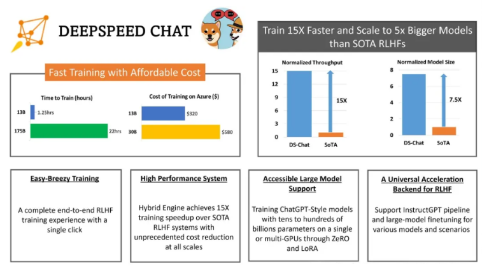
7.DeepSpeed
即是训练加速框架,又能用于推理上线,
微软精心打造的开源深度学习优化库,以系统优化和压缩为核心,深度优化硬件设备、操作系统和框架等多个层面,更利用模型和数据压缩技术,极大提升了大规模模型的推理和训练效率。
总结:择部署框架时,我们应该深入了解框架的特性、优缺点以及适用场景,综合考虑项目规模、技术栈、资源等因素,从而选择最适合的框架来支撑项目的实施。这样不仅可以提高开发效率,还能降低项目风险,确保项目的顺利推进和最终成功。
- 追求高性能推理?DeepSpeed是您的理想之选。其独特的ZeRO(零冗余优化器)、3D并行(数据并行、模型并行和流水线并行的完美融合)以及1比特Adam等技术,都极大提高了大模型训练和推理的效率。
- 期望一个易于使用的工具?ollama可能更适合您。简洁的命令行界面,让模型运行变得轻松自如。
- 需要创建嵌入模型的单个可执行文件?Llamafile将是您的得力助手。其便携性和单文件可执行的特点,让人赞不绝口。
- 在多种硬件环境下实现高效推理?TGI将是不二之选。其模型并行、张量并行和流水线并行等优化技术,确保了大模型推理的高效运行。
- 面对复杂的自然语言处理任务,如机器翻译、文本生成等?基于Transformer的模型将为您助力。其强大的表示能力,轻松捕捉文本中的长距离依赖关系。
- 处理大规模的自然语言处理任务,如文本分类、情感分析等?vLLM将是您的得力助手。作为大规模的预训练模型,它在各种NLP任务中都能展现出色的性能。

















 4009
4009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









