






一、财务月结的 "死亡之谷":21亿数据的性能黑洞
某集团财务系统的真实数据显示:
单一核算表单个省份日均新增1亿多条凭证
- 全国数据跑日间账突破21 亿行
HANA 性能瓶颈本质:

二、分区破局:三维度构建财务数据弹性架构
1. 数据生命周期管理模型
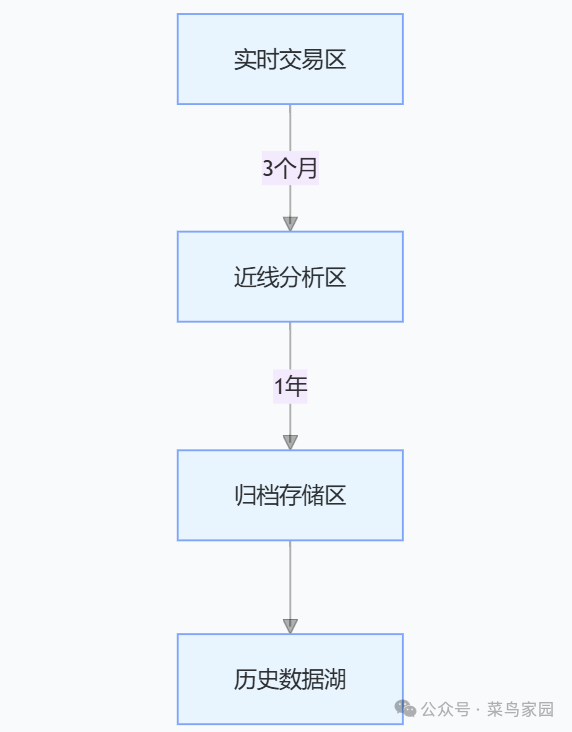
- 热数据区:内存优化存储,支持实时写入
- 温数据区:SSD 存储 + 列压缩,支持复杂查询
- 冷数据区:磁带库 / 云存储,成本仅为内存的 1/200
2. 分区策略矩阵
分区类型 | 财务应用场景 | 实施要点 |
时间范围分区 | 会计期间(YYYYMM) | 单分区≤3 亿行,预留 30% 扩展空间 |
业务维度分区 | 公司代码 / 利润中心 | 列表分区 + 复合键组合 |
混合分区 | 跨国集团合并报表 | 范围 + 哈希两级分区 |
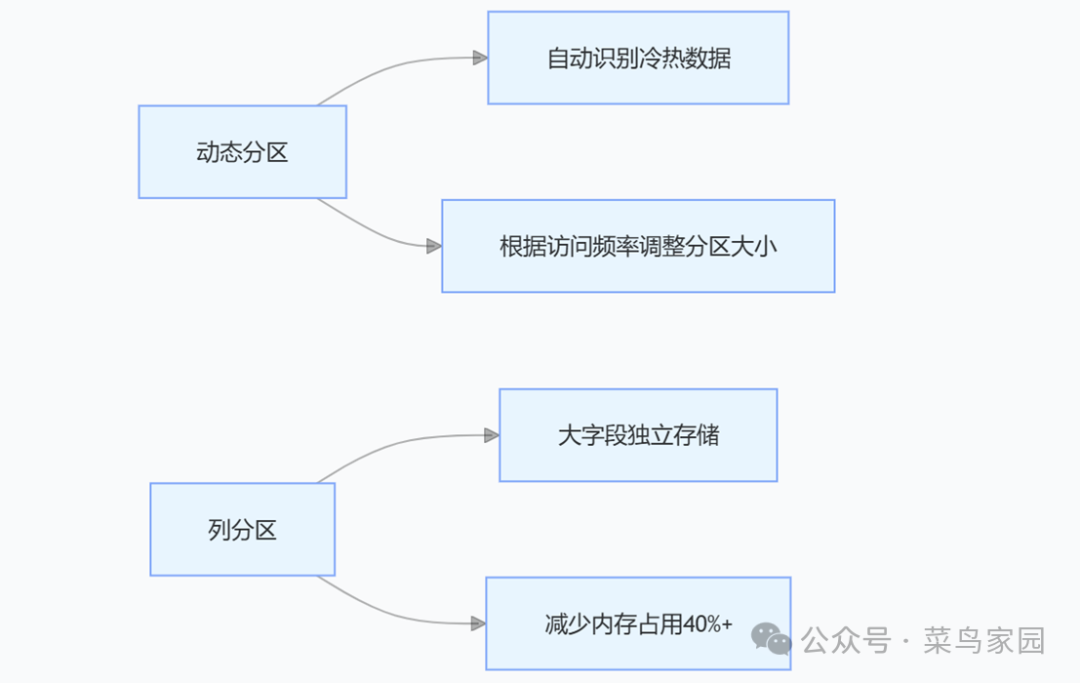
3. 智能分区技术栈
三、21 亿数据分区改造实战路径
1. 数据诊断与建模
- 通过HANA Studio热力图定位热点数据
- 建立财务数据访问频率模型
2. 分区键设计黄金法则
- 主分区键:GJAHR+POPER(YYYY、MM 格式)
- 辅助分区键:COMPANY_CODE(列表分区)
- 复合分区键:(POSTING_DATE等)
3. 性能监控仪表盘
监控指标 | 健康阈值 | 优化动作 |
单分区扫描时间 | ≤500ms | 拆分大分区 |
内存命中率 | ≥95% | 调整冷热数据比例 |
压缩率 | 6-8:1(财务数据) | 启用 HIGH 压缩 |
分区均衡度 | 差异≤15% | 执行分区重组 |
四、未来技术演进
- HANA 新特性:
- 自适应分区(自动合并小分区)
- 列级时间旅行(支持字段级版本回滚)
- 预测性分区调整(基于 LSTM 模型)
- 智能索引推荐(减少冗余索引 50%+)
五、具体分区方案还在学习、实践中,如果问题,请留言

















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









